








专利摘要
本发明提供一种自动嗓音谐噪比分析方法,包括:1)从录音中切分出进行谐噪比分析的有效语音段;2)基于听觉模型,对所述语音段进行滤波处理,然后计算听觉模型中各滤波器通道中的在时域和频域二维的能量相关系数;3)设定所述相关系数的阈值,当步骤2)得出的相关系数大于该阈值时,则该相关系数所对应的时域和频域坐标点为谐波成份,否则,该相关系数所对应的时域和频域坐标点为噪音成份,最后计算谐波成份与噪音成份的比值得出谐噪比。本发明使用自相关图表征的时域和耳蜗谱域通道之间相关性来判断谐波成份,不受基频检测位置的影响,能够更准确更鲁棒的检测出谐波成份。由于使用耳蜗谱,本发明与人耳的真实听觉更加匹配。
权利要求
1.一种自动嗓音谐噪比分析方法,包括如下步骤:
1)从录音中切分出进行谐噪比分析的有效语音段;
2)基于听觉模型,对所述语音段进行滤波处理,然后计算听觉模型中各滤波器通道中的在时域和频域二维的能量相关系数;
3)设定所述相关系数的阈值,当步骤2)得出的相关系数大于该阈值时,则该相关系数所对应的时域和频域坐标点为谐波成份,否则,该相关系数所对应的时域和频域坐标点为噪音成份。
2.根据权利要求1所述的自动嗓音谐噪比分析方法,其特征在于,所述步骤2)中,所述听觉模型包括中耳、外耳模型和耳蜗模型。
3.根据权利要求2所述的自动嗓音谐噪比分析方法,其特征在于,所述耳蜗模型是由一组Gammatone滤波器构成。
4.根据权利要求1所述的自动嗓音谐噪比分析方法,其特征在于,所述步骤1)中,切分所述有效语音段的方法如下:
步骤11)利用基于能量语音活动检测技术找出多段语音的起始点和终止点位置;
步骤12)对每段语音分别进行分帧,对于每一帧,计算该帧能量大小与整个能量的平均值;计算该帧的能量变化率;
步骤13)计算出能量值和能量值变化率的平均值;
步骤14)分别找出能量大小和能量变化率同时在平均值周围一定阈值范围内的帧,这些帧中的第一帧和最后一帧分别为所述有效语音段的启示帧和终止帧。
5.根据权利要求1所述的自动嗓音谐噪比分析方法,其特征在于,所述步骤2)中,所述能量相关系数需进行归一化处理,所述步骤3)中,所述阈值设定为0.9915。
6.根据权利要求1所述的自动嗓音谐噪比分析方法,其特征在于,所述步骤3)中,还包括计算谐波成份与噪音成份的比值得出谐噪比,然后对多个样本的谐噪比进行加权平均,得到最终的谐噪比值。
7.根据权利要求6所述的自动嗓音谐噪比分析方法,其特征在于,所述谐噪比分析方法还包括:利用步骤3)所得的谐噪比进行病变嗓音评估。
说明书
技术领域技术领域
本发明属于语音信号处理技术领域,具体地说,,本发明涉及一种自动嗓音评估中的谐噪比分析方法。
技术背景背景技术
谐噪比(Harmonic to Noise Ration,HNR)是对长元音进行分析评估的主要指标。传统的谐噪比计算方法是先在时域上利用周期信号的自相关性,估计出信号基频的周期。然后根据基频周期的位置,将基频周期附近相关性强的部分作为谐波成份,而将相关性弱或不相关的部份作为噪声来计算谐噪比。这种方法存在着一些缺陷:1.对于一些病变程度较为严重的嗓音样本或者较为沙哑的嗓音样本来说,基频周期的估计很容易出现偏差,有时甚至很难估计出样本的周期,这样就无法计算出有效的谐噪比数值;2.这些谐波计算是在普通时频域上进行的,这与真实的人耳感知存在着极大的差别,因此在实际应用中,最后的计算结果与嗓音专家进行的主观评测打分匹配并不合理。
在人类听觉的研究方面,听觉场景分析(CASA)一直以来是科研工作者所关注的方面。听觉场景分析可以利用声音的各种特性(时域,频域,空间位置等)对现实世界的混合声音进行分解,使其成份归属于各自的物理声源。听觉场景分析系统一般通过时频分析模拟人耳对各频率的不同反应,产生一个二维时频分布图,将输入信号分解为系列感官元素。然后根据这些感官元素的分析,按照不同声源进行分组,得到对某个声源信号进行感知的“听觉流”(Auditory Stream),最后经过重新组合后以达到声源分离的效果。
另外在样本的选择上,为了提高样本参数的稳定性,普通系统一般需要人工手动切除录音样本头部和尾部不稳定的部分,然后多次反复测试求平均。这种方法加入了人工的干预,不仅费时费力,而且会对结果造成主观影响而使计算过程很难复现。
发明内容发明内容
本发明的目的是利用听觉场景(CASA)分析中的听觉流的概念,将不同语音样本中的谐波成份看成是不同的听觉流成份加以分离提取从而计算出谐噪比,从而提供一种更准确鲁棒的自动嗓音谐噪比分析方法。
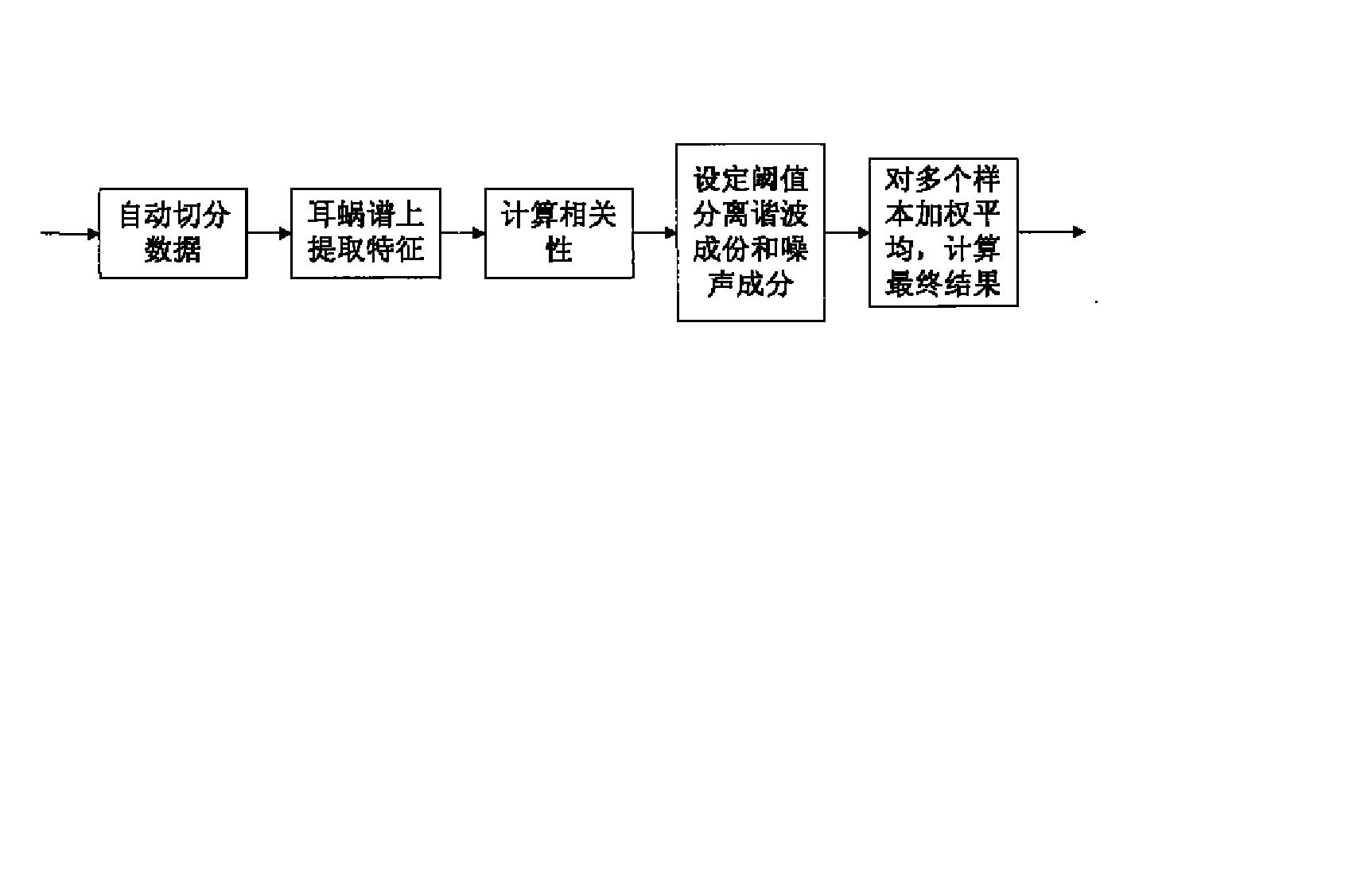
为实现上述发明目的,本发明提供的自动嗓音谐噪比分析方法包括如下步骤(参考图2):
1)从录音中切分出进行谐噪比分析的有效语音段;
2)基于听觉模型,对所述语音段进行滤波处理,然后计算听觉模型中各滤波器通道中的在时域和频域(在本发明的一个实施例中频域是指耳蜗频谱域)二维的能量相关系数;
3)设定所述相关系数的阈值,当步骤2)得出的相关系数大于该阈值时,则该相关系数所对应的时域和频域坐标点为谐波成份,否则,该相关系数所对应的时域和频域坐标点为噪音成份,最后计算谐波成份与噪音成份的比值得出谐噪比。
上述技术方案中,所述步骤2)中,所述听觉模型包括中耳、外耳模型和耳蜗模型。
上述技术方案中,所述耳蜗模型是由一组Gammatone滤波器构成。
上述技术方案中,所述步骤1)中,切分所述有效语音段的方法如下:
步骤11)利用基于能量语音活动检测技术找出多段语音的起始点和终止点位置;
步骤12)对每段语音分别进行分帧,对于每一帧,计算该帧能量大小与整个能量的平均值;计算该帧的能量变化率;
步骤13)计算出能量值和能量值变化率的平均值;
步骤14)分别找出能量大小和能量变化率同时在平均值周围一定阈值范围内的帧,这些帧中的第一帧和最后一帧分别为所述有效语音段的启示帧和终止帧。
上述技术方案中,所述步骤2)中,所述能量相关系数需进行归一化处理,所述步骤3)中,所述阈值设定为0.9915。
上述技术方案中,所述步骤3)中,还包括对多个样本的谐噪比进行加权平均,得到最终的谐噪比值。
上述技术方案中,还包括:利用步骤3)所得的谐噪比进行病变嗓音评估。
本发明相对于现有的谐噪比分析方法,具有如下技术效果:
1、传统方法使用基频检测来判断谐波成份,因此计算结果的准确程度依赖于基频位置,对于一些基频检测不准甚至难以检测的病变程度严重或者比较沙哑的嗓音样本,传统方法无能为力。本发明使用自相关图表征的时域和耳蜗谱域通道之间相关性来判断谐波成份,则不受基频检测位置的影响,能够更准确更鲁棒的检测出谐波成份。
2、谐波成份是在耳蜗谱上进行的计算,与人耳的真实听觉更加匹配,与嗓音医学专家的经验打分更加吻合。
3、相对于传统的计算方法用手工选择样本中较为稳定部分的方法,本发明可以自动选择出样本稳定部分,排除了人工干预,省时省力,而且提高了评估结果的客观度。
4、相对于传统的人工选择稳定样本的方法,本发明采用了根据样本长度求加权平均的方法,排除了人为的干扰因素,提高了样本利用率,从而更符合实际特性。
附图说明附图说明
以下,结合附图来详细说明本发明的实施例,其中:
图1是25通道Gammatone滤波器组响应图;
图2是本发明的自动嗓音谐噪比分析方法的总体框图;
图3是本发明一个实施例中自动嗓音谐噪比分析方法的流程图。
具体实施方式具体实施方式
本发明的总体构思如下:在具体的录音过程中,一般出于稳定性的考虑,传统的方法会让患者反复发音3-5遍,然后由嗓音专家选取其中一个较为稳定的作为样本分析,而抛弃了其它的样本。这样不仅引入了人为因素影响结果,同时也丢弃了其它反应嗓音特征的样本。本发明将所有样本都利用起来。一般的嗓音评测录音都在很安静的环境下完成,为此本发明选择了基于能量的语音活动检测器(VAD)来找出语音的起始点和终止点,然后将它们切分出来作为此人的几个嗓音样本备用。
对于每个样本来说,由于患者发音会从开始从小变大,稳定一段时间后再由大变小,最后终止发音。传统方法一般会由嗓音专家选取此样本中间的稳定部分进行分析,这样增加了人为的干扰并且费时费力。我们利用能量大小和变化率与他们的平均值作为依据,来判断出出样本头部和尾部的稳定位置,自动选择样本中间的稳定部分进行分析。
对于样本的谐波分析来说,普通做法是利用信号的自相关性算出样本的基频位置,然后找出相应的谐波位置的成份作为谐噪比计算的谐波部份,其余的部分作为噪声部分,最后求得谐噪比。但由对谐噪比计算结果的评判一般是采取与嗓音医学专家对此的打分进行匹配度分析来进行的,而人耳的听觉谱与普通等间隔的傅立叶变换频谱有很大差别,所以常常造成评估结果的偏差。因此本发明将信号在听觉谱域进行分解,依据听觉场景分析(CASA)中听觉流的概念得出信号的相关图,在设定阈值后判断出哪些时频块属于谐波成份哪些属于噪声成份,最后计算出谐噪比。
重复上述过程,得出此人若干样本的每个谐噪比值,然后根据若干样本不同的长度做加权平均以求得最后的数值。
实施例1
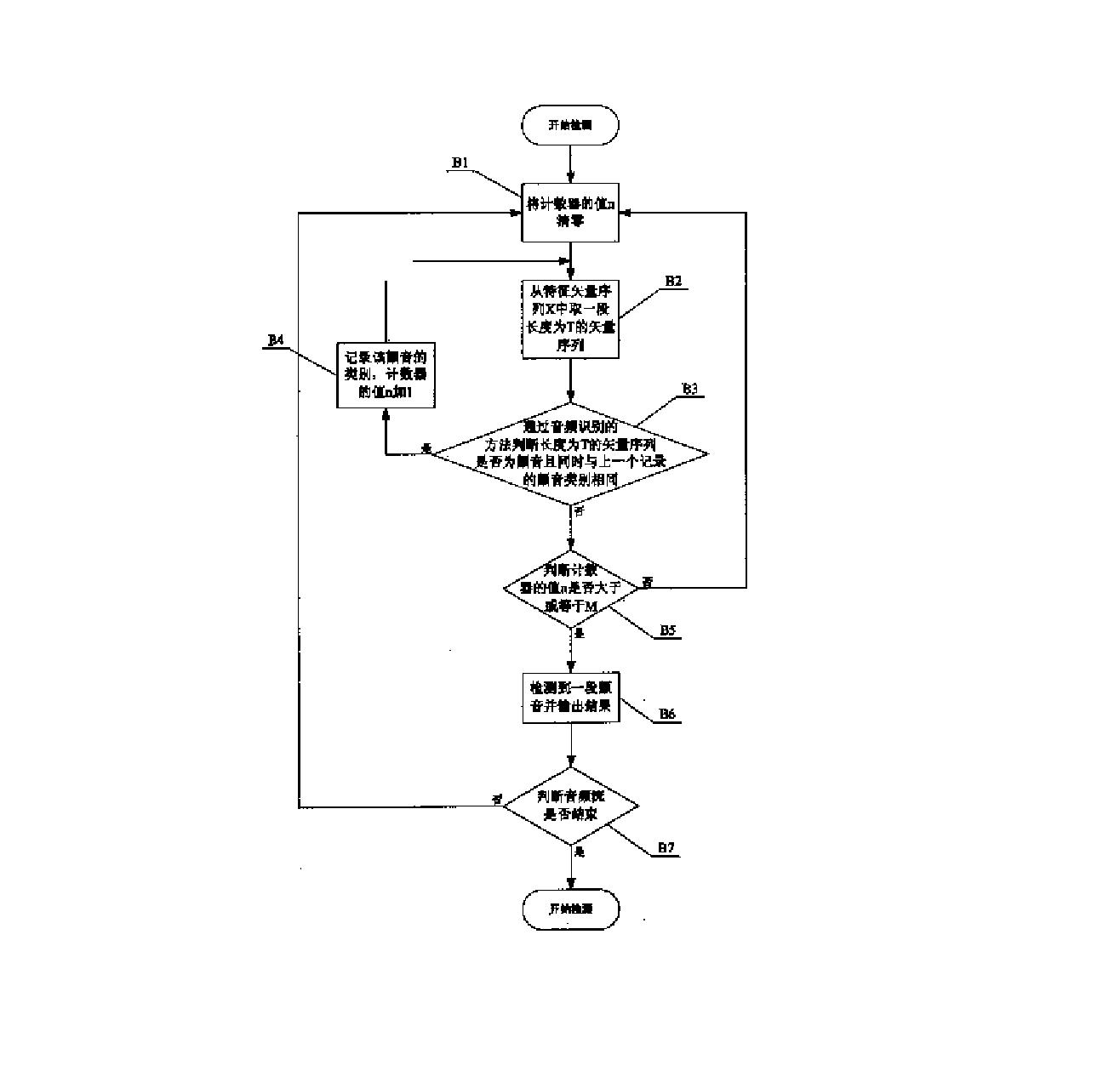
本实施例的整体流程可参考图3,下面分别描述本实施例涉及的各个技术细节。
1.切分数据,自动找出每段发音的稳定部分,包括:
1)利用基于能量语音活动检测技术(VAD)找出多段语音的起始点和终止点位置,对每段语音进行分别分析;
2)分帧,对于每一帧,计算该帧能量大小与整个能量的平均值,设信号为S,共分N帧,每帧有m个样点,则第n帧的能量E(n)为
3)计算所述帧的能量变化率,即差分值,设第n帧的能量变换率为D(n),则:
D(n)=E(n)-E(n-1)
4)计算出能量值和能量值变化率的平均值:
5)分别找出能量大小和能量变化率同时在平均值周围一定阈值范围内的帧。找出符合要求的第一帧和最后一帧即为稳定部分的启示帧和终止帧。阈值的设定经过反复试验选为10%。
2.利用人耳听觉模型分解每段信号,获得信号在耳蜗谱上的时频分布:
1)中耳和外耳模型:中耳和外耳对声音信号在1.5~5.0kHz范围内有10~20dB的提升,可以利用预加重方式来大致模拟其压力增益,设原始信号y(t),经过预加重后的信号即为:
x(t)=y(t)-0.95y(t-Δt)
式中,t为时间,Δt为采样间隔。
2)耳蜗模型:采用了由Patterson提出的一组Gammatone滤波器组来模拟耳蜗的特性。在此Gammatone滤波器组中,每个通道的Gammatone滤波器由4个半正交的二阶滤波器级联构成。下图为100-16000Hz频率范围内由25个Gammatone滤波器所构成的耳蜗滤波器组的滤波器响应图。由图可以看出,滤波器在对数轴上的峰值点的分布基本为等间隔分布,这与耳蜗模型的特点相符。我们对50-16000Hz的频带范围内划分了128个通道的Gammatone滤波器组,这样能够较好的反映此频带内语音的基频和谐波特征。
Gammatone滤波器组中每个频带的滤波器冲击响应为:
g(fc,t)=bata-1e-2πbtcos(2πfct)
式中,fc为中心频率,t为时间,a=4为滤波器阶数。
b为滤波器衰减因子,它决定了脉冲的衰减速度,与滤波器的带宽有关。耳蜗基底膜对声音信号的不同频率具有非线性选择性,所以滤波器的带宽随着中心频率的升高而增大,可以根据人耳临界频带的等效矩形带宽(ERB)确定,计算公式为:
令b=1.019×ERB(f),设x(t)为输入信号,对于每一个时刻每一个滤波器通道c,设fc为中心频率。则相应的时频单元x(c,t)为:
x(c,t)=x(t)*g(fc,t)
式中,x(t)为输入信号,g(fc,t)为相应的Gammatone滤波器,“*”代表卷积,在本步骤中,每个通道的输出向后延时(a-1)/(2πb),可以补偿滤波器的延时。
3.谐波分析:
经过模拟耳蜗模型的Gammatone滤波器处理后的x(c,t)即为在时间t和通道f的时频能量分布,这种分布是符合人耳特性的。下面再利用这种时频分布计算符合耳蜗模型的谐波成分。
为了防止不同的能量相关系数标准不同,先将系数进行归一化处理,归一化后的自相关系数为:
式中,c为相应的滤波器通道,t为时刻,τ是时延,。
式中,L为所计算的最大时延,人发声的基频一般在50Hz以上,因此L=1000ms/50Hz=20ms。 为rA(c,t,τ)归一化后的结果,CH(c,t)即为所得出的考虑到时间和频带上连续性的相关系数。
由于谐波成分之间的时域和频带相关性会大于谐波与噪声的相关性或噪声与噪声的相关性,所以通过CH(c,t)的值范围就可以判断在t时刻c通道的成份是否为谐波成份。为此必须先设定出一个阈值,然后比较CH(c,t)与阈值的大小关系来判断是否为谐波成份。
4.阈值设定:
为了选定谐噪比的阈值,本实施例选取了经过嗓音医学专家按照GRBAS评级标准评级过的典型嗓音样本40例,其中G0-G3各10例,每例发的长元音数目为3个,共120个长元音样本。手工取其中较为平稳的部分,每部分的长度都在3秒钟以上。
阈值测试区间为0.100-0.999,计算出谐噪比与嗓音专家评级之间的相关度。经测试,阈值在0.9915时相关度达到了最大值,因此最终选择了阈值UH=0.9915。
5.谐噪比计算:
在对设定一个阈值后,就可以根据这个阈值分离出谐波和噪声成分。设E(c,t)=x(c,t)2为相应时频块的能量,EH和EN分别为谐波能量和噪声能量,则:
最后得出的信噪比为:
6.多个样本加权平均:
由于人在发持续时间较长的元音时往往稳定性较好,因此有必要对发音时间长的样本采取更大的权重。因此按照切分出的每段的长度比率计算出加权系数,根据加权系数和分段数可以算出最终的谐噪比数值。设切分出的样本总数为M个,第n段样本的稳定部分长度为Ln,相应段的谐噪比为HNRn,则:
HNR′为最终计算出的谐噪比。
本发明特别适合用于病变嗓音客观评估中。谐噪比的计算是病变嗓音客观评估技术的关键之一。病变嗓音客观评估技术是利用信号处理技术对嗓音信号进行分析,从而对病人声门病变程度以及病变情况进行评估判断的技术。一般选择长元音作为病变嗓音的评估样本。谐噪比能否计算准确直接影响到了对患者的嗓音评估准确度。在中国人民解放军总医院(301医院)病变嗓音医学样本247个人共计817例长元音样本中,采用普通谐噪比计算方法计算出的谐噪比与嗓音专家打分的匹配度为-0.62(其中包含24例样本无法计算),而采用本发明中所使用的计算方法对全部的样本都可以有效计算,匹配度为-0.79。
本发明还可以用语音质量评估、信道特征分析等领域。
最后,最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
一种自动嗓音谐噪比分析方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。






动态评分
0.0