

IPC分类号 : G10L15/24,G10L21/0208,G10L21/0224,G10L13/00





专利摘要
本发明公开了一种基于听觉感知特性的数字语音实时分解/合成方法,涉及语音信号处理领域。本方法包括用N级级联的二阶带通滤波器构成一个N阶的伽马通滤波器再构建任意阶的伽马通数字滤波器模型及其参数,语音分解阶段用M路伽马通滤波器采用浮点算法或定点算法将输入语音分解为M路信号;语音合成阶段在伽马通滤波器组中引入延时,以更加符合人耳特性,人耳基底膜延时与频率成反比关,最后进行语音合成操作。本发明参考了人耳的等响度曲线特性,改进了语音分解合成方法,使得最终语音合成效果接近了理想带通滤波器的效果。本发明可应用在手机、人工耳蜗、助听器等语音设备中。
权利要求
1.一种基于听觉感知特性的数字语音实时分解/合成方法,其特征在于,该方法具体步骤如下:
1)构建任意阶的伽马通数字滤波器模型:
假设滤波器组数目为M,该M组滤波器对应着人耳基底膜上的M个位置,并在人耳基底膜上是均匀分布的,在频域上是对数分布的;具体包括:
1.1)已知输入语音的采样率为f
设通过滤波器的语音频率范围为[f
1.2)根据表达式(1-2):
其中,m∈[1,M],代表通道号;
1.3)根据式(1)的计算结果得到M组滤波器的中心频率f
1.4)针对b(f
其中,b代表函数的带宽,N为任意正整数;
1.5)用N级级联的二阶带通滤波器构成一个N阶的伽马通滤波器;对每个伽马通滤波器的时域表达式(1-3):
将式(2b)分解成零极点相乘得到如表达式(2c)所示:
使用冲激响应不变法得到N阶伽马通数字滤波器的z域表达式(2d):
其中n=1,2,…,N,s
a
1.6)计算归一化参数g
归一化参数g
1.7)根据步骤1.5)中得到的N级级联的二阶带通滤波器来构成任意阶的伽马通数字滤波器模型,并获取模型的各参数值:用m表示第m组伽马通滤波器组,则由表达式(1-10)、(1-11)、(2e)和(2f)分别得出各个滤波器组的参数
2)语音分解阶段;
利用步骤1)构建的伽马通数字滤波器模型,模仿人耳基底膜对语音进行分解:将输入语音实时地分解到M个子带上,使用M路伽马通滤波器采用浮点算法或定点算法将输入语音分解为M路信号;
3)语音合成阶段;
在伽马通滤波器组中引入延时,以更加符合人耳特性,人耳基底膜延时与频率成反比关系,伽马通滤波器的群延时用表达式(16)来描述:
式中,m通道群延时t
具体步骤包括:
3.1)计算各通道延时:语音的采样率为f
d
其中D为[f
3.2)对各个通道在总滤波器中所占比重进行加权,则合成语音用表达式(8)来计算;设m通道的权重为w
此时,最终合成语音输出如式(20)所示:
其中,当k≤d
2.如权利要求1所述数字语音实时分解/合成方法,其特征在于,所述步骤2)用于软件仿真时采用浮点算法,具体包括:
将输入语音依次通过M路伽马通滤波器得到M组语音输出信号,如式(7)-式(10)所示:
其中,m∈[1,M]代表通道号,n∈[1,4]指明表达式描述的是四级级联结构中的具体级数;y
3.如权利要求1所述数字语音实时分解/合成方法,其特征在于,所述步骤2)用于硬件实现时采用定点算法将输入语音依次通过M路伽马通滤波器得到M租语音输出信号,具体包括以下步骤:
2.1)对各个滤波器组的各参数进行定点化处理,即使参数扩大E=2
各式中[·]表示最接近·的整数;
2.2)对分别表示第m路伽马通滤波器中第n级的输入语音信号和输入语音信号的中间运算数据
Q=L+[log
其中[·]代表取不小于Q的最小整数;由此得到每一路语音的输入输出。
说明书
技术领域
本发明属于数字语音信号处理领域,具体涉及一种基于听觉感知特性的数字语音实时分解/合成方法。
背景技术
在日常生活中,存在各种各样的噪声。语音增强和语音识别等设备的性能在噪声环境下会明显恶化,限制了其应用场景。由于人耳在噪声环境下仍能正常工作,且对声音具有较强的灵敏度和抗干扰能力。因此在语音信号处理系统中迫切需要实现人耳尤其是基底膜的听觉感知特性。人耳基底膜的感知特性有:
1.频率选择特性:不同的频率在基底膜上都有相应的共振点,频率较高的声音,在靠近基底膜底部位置会引起较大幅度的振动;对于频率较低的声音,响应最强烈的位置在基底膜的顶部。
2.频率分析特性:它能够将声音中的各种频率分解映射到基底膜的不同位置来感知,得到频率分布图;同时还能够将声音强度转化为对应基底膜位置上的振动幅度。最终,基底膜将声音中具有不同幅度不同频率的声音分离出来,并产生相应的神经信息,相当于对频率和强度等进行了编码,这样大脑就能够对这些信息进行分析归纳,形成不同的听觉感受。
3.带宽特性:人耳基底膜每个位置的滤波特性各不相同。人耳基底膜顶部对低频比较敏感,且在低频的分辨率较高、带宽小;基底膜底部对高频敏感,且在高频的分辨率高、带宽大。
人耳基底膜每个位置的滤波特性都可以用一个听觉滤波器来描述,于是听觉系统处理语音的过程可以用一组听觉滤波器来模拟,听觉滤波器是通过拟合听觉系统的心理声学实验数据而被提出来的一类滤波器。使用上述听觉滤波器组可以将语音分解到不同的子带上面,进而实现对语音的分解和合成。
为了描述听觉滤波器的带宽,研究中经常使用等价矩形带宽(ERB)这一概念,ERB是指:对于相同的白噪声输入,当矩形滤波器和被测滤波器通过相同能量时,矩形滤波器的带宽即为等价矩形带宽。ERB与听觉滤波器的中心频率fc大致呈线性关系,具体关系可用表达式如式(1-1)所示来描述:
ERB(fc)=24.7(1+4.37fc/1000)(1-1)
M组滤波器的中心频率fc对应着人耳基底膜上的M个位置,它们在基底膜上是均匀分布的。为了更好的描述这种分布,ERB域(ERBs)的概念,首先通过表达式如式(1-2)所示得到ERBs域上的值,再将ERBs值均分,最后在回推出中心频率fc的值。
一种典型的听觉滤波器组是由M个伽马通滤波器(Gammatone Filterbank)构成,每个伽马通滤波器的时域表达式为:
其中,u(t)是阶跃函数;参数A一般是固定值,主要用于归一化处理;N代表滤波器的阶数,控制着Gammatone函数包络的相对形状,一般设置N=4;b代表函数的带宽,控制着函数时域的波动越大,函数波动的范围就越小,b=ERB(fc)。fc代表滤波器的中心频率; 代表初始相位,由于 对滤波器性能影响较小,并且人耳对相位不敏感,因此 一般被设置为0。
将表达式(1-3)中进行Laplace变换,得到s域表达式为:
其中,Bc=2πb,wc=2πfc;
gn为归一化参数;
对表达式(1-4)使用冲激响应不变法,
可得到数字滤波器的z域表达式:
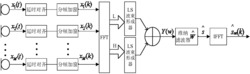
由表达式(1-9)可得到其时域迭代方程式(1-13),滤波器结构如图1所示,由四级级联结构组成,其中a1~a4,b1,b2分别为各级滤波器的抽头系数,g1~g4分别为各级的归一化系数,方框中表示在变换域Z域进行延时操作,每一级的输入信号经过各抽头系数的加权、延时、相加等操作后传入下一级。
x1(k)=x(k)(1-12)
yn(k)=xn(k)+anx(k-1)-b1y(k-1)-b2y(k-2)(1-13)
xn+1(k)=gnyn(k)(1-14)
y(k)=g4y4(k)(1-15)
经过上述M个伽马通滤波器,输入语音被分解为M路语音信号,每路输出为y
在实际应用中,系统有时还需要将分解后的语音(已经过降噪、识别等处理)恢复原始语音。由于每个通道都有群延时,因此可以获取群延时Dm,然后调整各通道延时,最后合成语音,计算表达式如下:
该方法的转移函数的幅度响应特性如图2所示,可以看到在低频阶段幅度较高,随着频率的升高幅度缓慢下降,其中合成语音中的各通道权重均相同,通道数目M=64,通道中心频率分布为50Hz~7500Hz。
上述方法的缺点是:
1.该方法限制了伽马通函数的阶数N=4,它仅仅是伽马通滤波器的一个特例,没有给出伽马通滤波器在N为其它值时的实现方法。
2.该方法的一些关键参数是通过仿真获取的,缺乏理论计算依据,主要包括参数b、归一化参数gn和通道群延时Dm,这降低了方法可操作性和可重复性。
3.该方法中的各个伽马通滤波器的幅度是相等,即合成语音时各个通道的权值均设成了1。然而人耳对于不同通道上的语音感知到的响度是不同,如图3中的人耳等响度曲线所示,横坐标为频率,单位是Hz,纵坐标为声压等级,单位为dB,要达到相同的响度,高频需要较高的幅值,低频需要较低的幅值。这样最终就导致合成语音有些频率上的语音被抑制了。
发明内容
本发明的目的是针对现有技的不足,提出一种基于听觉感知特性的数字语音实时分解/合成方法。该方法给出了任意阶数的伽马通滤波器的实现方法,同时推导出了伽马通滤波器中的归一化参数gn;并根据人耳基底膜延时特性,给出了各个的通道延时Dm。最后本发明参考了人耳的等响度曲线特性,改进了语音分解合成方法,使得最终语音合成效果接近了理想带通滤波器的效果。
本发明提出的一种基于听觉感知特性的数字语音实时分解/合成方法,其特征在于,该方法具体步骤如下:
1)构建任意阶的伽马通数字滤波器模型:
假设滤波器组数目为M,该M组滤波器对应着人耳基底膜上的M个位置,并在人耳基底膜上是均匀分布的,在频域上是对数分布的;具体包括:
1.1)已知输入语音的采样率为fs;
设通过滤波器的语音频率范围为[fL,fH],0≤fL<fH≤fs/2;
1.2)根据表达式(1-2): 得出中心频率fc在ERBs域上的值分布为[ERBs(fL),ERBs(fH)],将其均分成M-1份得到等间距的M个ERBs值如式(1)所示:
其中,m∈[1,M],代表通道号;
1.3)根据式(1)的计算结果得到M组滤波器的中心频率fc在ERBs域上的值如式(2)所示:
1.4)针对b(fc)与ERB(fc)的关系:基于b=ERB(fc),根据帕塞瓦尔(Paseval)定理,得出N阶伽马通滤波器中滤波器的中心频率fc的带宽函数b(fc)表达式如式(2a)所示:
其中,b代表函数的带宽,N为任意正整数;
1.5)用N级级联的二阶带通滤波器构成一个N阶的伽马通滤波器;对每个伽马通滤波器的时域表达式(1-3): 进行Laplace变换得到s域表达式如式(2b)所示:
将式(2b)分解成零极点相乘得到如表达式(2c)所示:
使用冲激响应不变法得到N阶伽马通数字滤波器的z域表达式(2d):
其中n=1,2,…,N,sn为表达式分子的零点,an、b1、b2的含义分别为各级滤波器的抽头系数;
an的表达式如(1-10)所示: b1、b2的表达式如(1-11)所示:
1.6)计算归一化参数gn:伽马通滤波器各级的二阶滤波器的最大增益如式(2e)所示:
归一化参数gn如式(2f)所示:
1.7)根据步骤1.5)中得到的N级级联的二阶带通滤波器来构成任意阶的伽马通数字滤波器模型,并获取模型的各参数值:用m表示第m组伽马通滤波器组,则由表达式(1-10)、(1-11)、(2e)和(2f)分别得出各个滤波器组的参数 的值,其中 是各个通道的滤波器抽头系数, 为各个通道的归一化系数,如式(3)-式(6)所示:
2)语音分解阶段;
利用步骤1)构建的伽马通数字滤波器模型,模仿人耳基底膜对语音进行分解:将输入语音实时地分解到M个子带上,使用M路伽马通滤波器采用浮点算法或定点算法将输入语音分解为M路信号;
3)语音合成阶段;
在伽马通滤波器组中引入延时,以更加符合人耳特性,人耳基底膜延时与频率成反比关系,伽马通滤波器的群延时用表达式(16)来描述:
式中,m通道群延时tm的单位是秒,第m组滤波器的中心频率fc的单位是Hz;
具体步骤包括:
3.1)计算各通道延时:语音的采样率为fs,则采样后的各个通道的延时dm用如表达式(17)、(18)来进行计算:
dm=D-[fstm](17)
其中D为[fstm]中的最大值;
3.2)对各个通道在总滤波器中所占比重进行加权,则合成语音用表达式(8)来计算;设m通道的权重为wm,该权重合并到gN中,调增后的gN用如下表达式计算:
此时,最终合成语音输出如式(20)所示:
其中,当k≤dm时y
本发明的特点及有益效果在于:
1)本发明有系统详细的理论推导过程,给出了各参数的理论计算方法,增强了算法实现的可操作性。
2)本发明不仅能完成语音分解操作,而且还提供了语音分解的逆变换过程,即支持后续对语音的合成操作。
3)本发明的所有操作均在时域上完成,避免了使用傅里叶变换以及逆变换等操作。
4)本发明解决了实时性问题,能实时对语音进行分解、综合操作,扩大了其应用范围。
5)针对计算复杂度过高、不利于算法硬件实现的问题,本发明提出了一套完整的定点化方案,为算法的硬件实现节约了大量资源。此外还使用了流水线技术,降低了关键路径延时,降低了方法的计算复杂度。
附图说明
图1为现有方法中语音分解阶段使用的伽马通数字滤波方框图。
图2为现有方法中合成语音阶段的总幅度响应曲线。
图3为人耳的等响度曲线。
图4为本发明使用的定点化滤波算法的方框图
图5本发明中合成语音阶段的总幅度响应曲线。
具体实施方式
本发明提出的一种基于听觉感知特性的数字语音实时分解/合成方法,下面结合附图及具体实施例进一步说明如下:
本方法的与已有技术的主要区别是使用一组伽马通滤波器来模拟人耳的基底膜,基底膜上每个位置的滤波特性都可以用一个伽马通滤波器来描述,同时该方法参考了人耳基底膜延时特性和等响度曲线特性,进而实现对语音的分解和合成。
该方法的具体步骤如下:
1)构建任意阶的伽马通数字滤波器模型(包括每个滤波器的带宽、中心频率即位置参数信息):
假设滤波器组数目为M,该M组滤波器对应着人耳基底膜上的M个位置,并在人耳基底膜上是均匀分布的,在频域上是对数分布的;具体包括:
1.1)已知输入语音的采样率为fs;
设通过滤波器的语音频率范围为[fL,fH],0≤fL≤fH≤fs/2;
1.2)由表达式(1-2): 得出中心频率fc在ERBs域上的值分布为[ERBs(fL),ERBs(fH)],将其均分成M-1份得到等间距的M个ERBs值如式(1)所示:
其中,m∈[1,M],代表通道号;
1.3)根据式(1)的计算结果得到M组滤波器的中心频率fc在ERBs域上的值如式(2)所示:
1.4)针对b(fc)与ERB(fc)的关系:基于b=ERB(fc),根据帕塞瓦尔(Paseval)定理,得出N阶伽马通滤波器中滤波器的中心频率fc的带宽函数b(fc)表达式如式(2a)所示:
其中,b代表函数的带宽,N为任意正整数;
1.5)用N级级联的二阶带通滤波器构成一个N阶的伽马通滤波器;对每个伽马通滤波器的时域表达式(1-3): 进行Laplace变换得到s域表达式如式(2b)所示:
将式(2b)分解成零极点相乘得到如表达式(2c)所示:
使用冲激响应不变法得到N阶伽马通数字滤波器的z域表达式(2d):
其中n=1,2,…,N,sn为表达式分子的零点,an、b1、b2的含义分别为各级滤波器的抽头系数;
an的表达式如(1-10)所示: b1、b2的表达式如(1-11)所示:
由此将表达式(1-4)和(1-9)推广到了N为任意正整数的情况。以上结果将一个N阶的伽马通滤波器用N级级联的二阶带通滤波器来构成。
1.6)计算归一化参数gn:(由于伽马通滤波器的幅度响应曲线是近似对称的,伽马通滤波器的幅度最大值在中心频率fc处取得,)因此伽马通滤波器各级的二阶滤波器的最大增益如式(2e)所示:
归一化参数gn如式(2f)所示:
1.7)根据步骤1.5)中得到的N级级联的二阶带通滤波器来构成任意阶的伽马通数字滤波器模型,并获取模型的各参数值:用m表示第m组伽马通滤波器组,则由表达式(1-10)、(1-11)、(2e)和(2f)分别得出各个滤波器组的参数 的值,其中 是各个通道的滤波器抽头系数, 为各个通道的归一化系数,如式(3)-式(6)所示:
2)语音分解阶段;
利用步骤1)构建的伽马通数字滤波器模型,模仿人耳基底膜对语音进行分解:将输入语音实时地分解到M个子带上,最小处理单位是单个语音采样点,同时该处理过程均是在时域上进行的(不需要将语音变换到频域上),得到M路的语音数据;
首先假设输入语音为x(k),采样率为fs,使用M路伽马通滤波器采用浮点算法或定点算法将输入语音分解为M路信号,每一路的输出信号用y
用于软件仿真时采用浮点算法将输入语音依次通过M路伽马通滤波器得到M组语音输出信号,如式(7)-式(10)所示:
其中,m∈[1,M]代表通道号,n∈[1,4]指明表达式描述的是四级级联结构中的具体级数;y
用于硬件实现时采用定点算法将输入语音依次通过M路伽马通滤波器得到M租语音输出信号
(针对计算复杂度过高、不利于算法硬件实现的问题,本发明提出了一套完整的定点化方案,为算法的硬件实现节约了大量资源;该算法同样将输入语音依次通过M路伽马通滤波器得到M租语音输出信号。图4为本发明使用的定点化滤波算法的方框图,流程与图1相似,但其中所有参数均为定点化处理后的结果,改进后,算法的计算时间周期缩短到原来的1/4,将算法的计算能力提升了4倍,从而达到减少运算资源消耗、降低功耗的目的。具体包括以下步骤:
2.1)对各个滤波器组的各参数进行定点化处理,即使参数扩大E=2
各式中[·]表示最接近·的整数;
2.2)对分别表示第m路伽马通滤波器中第n级的输入语音信号和输入语音信号的中间运算数据 进行定点化处理:即根据表达式(2e)得到最大增益Gain值随着中心频率fc的变化关系,由此得出最大增益Gainmax,因此当输入语音为L比特时,中间运算结果的位宽设为Q比特,则Q的值为:
Q=L+[log2(Gainmax)](15)
其中[·]代表取不小于Q的最小整数;由此得到如图4所示的定点化滤波算法,以及每一路语音的输入输出;
3)语音合成阶段;
在步骤2)中语音信号通过N阶Gammatone滤波器,被分解到N个子带上,可对分解后的语音信号进行语音增强、语音识别等处理(例如使用波束形成、计算听觉场景分析等常用语音增强算法);处理后各路信号可通过直接叠加的操作重新合成,进而更好地还原语音。
本发明在合成阶段参考了人耳基底膜神经延时特性,给出了伽马通滤波器的通道延时(时域延时)。人耳基底膜神经延时是指人耳基底膜接收语音信号,到将语音信号传递给大脑所需时间对于不同频率的声音是不一样的,因此在伽马通滤波器组中引入一定量的延时,更加符合人耳特性,人耳基底膜延时与频率成反比关系,基于以上分析,伽马通滤波器的群延时(相位变化随着频率变化的快慢程度)用表达式(16)来描述:
式中,m通道群延时tm的单位是秒,第m组滤波器的中心频率fc的单位是Hz。
本发明的语音合成过程参考了人耳基底膜的延时特性,在语音合成前对各通道的输出分别引入适当的延时,然后再直接相加,这样可以极大地减弱各通道间的相互干扰,使得语音能够逐点计算各个数字语音的合成与分解,从而到达实时处理的目的。具体步骤包括:
3.1)计算各通道延时:语音的采样率为fs,则采样后的各个通道的延时dm用如表达式(17)、(18)来进行计算:
dm=D-[fstm](17)
其中D为[fstm]中的最大值。
3.2)(根据图3所示的人耳的等响度曲线,要达到相同的响度,高频需要较高的幅值,低频需要较低的幅值。)对各个通道在总滤波器中所占比重进行加权,则合成语音用表达式(8)来计算;设m通道的权重为wm,在实际操作中,该权重可以合并到gN中,调增后的gN用如下表达式计算:
此时,最终合成语音输出如式(20)所示:
其中,当k≤dm时y
图5为采用本发明方法改进后语音合成阶段的幅度响应曲线。根据人耳等响度曲线调整通道权重后,合成语音方法的总幅度响应曲线接近理想带通滤波器效果,其中通道数目M=64,通道中心频率分布为50Hz~7500Hz,在7500Hz以内的频率范围内幅度响应较大,超过频率上限之后幅度衰减较快。
一种基于听觉感知特性的数字语音实时分解/合成方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。













动态评分
0.0