

IPC分类号 : G06K9/62,H04L12/24,H04L12/26,H04L29/06




专利摘要
本发明提出一种基于角标随机读取的Snort报警数据聚合方法,该方法包括:S1.采集原始Snort报警数据;S2.对原始Snort报警数据进行标准化得到的标准化Snort报警数据;S3.对原始Snort报警数据进行预处理操作;S4.以随机生成角标的方式对步骤S2获得的标准化Snort报警数据进行随机打散排列;S5.计算打散后的标准化Snort报警数据的各属性的相似度;S6.计算各打散后的Snort报警数据之间的全局相似度并计算每条Snort报警数据中各属性的权重值;S7.根据步骤S5得到的各属性的相似度以及步骤S6得到的各属性的权重值计算每条Snort报警数据的全局相似度;并计聚合结果。本发明采用角标随机读取算法实现报警数据按月分段,并且段内随机聚合比较,从而灵活计算相邻报警数据的属性相似度。
权利要求
1.一种基于角标随机读取的Snort报警数据聚合方法,其特征在于,该方法包括以下步骤:
S1.采集原始Snort报警数据;
S2.对原始Snort报警数据进行标准化得到标准化Snort报警数据;
S3.对标准化Snort报警数据进行预处理操作,包括根据步骤S1采集到的原始Snort报警数据出发,采用数据清理、属性选择和数据过滤方法来减少重复Snort报警数据的数量;
S4.以随机生成角标的方式对步骤S3获得精简后的Snort报警数据进行随机打散排列,通过入侵检测系统报警数据的读取方式,以随机生成角标的方式达到每条报警数据随机打散排列的目的;
S5.根据步骤S4所得到的打散后的Snort报警数据,计算打散后的标准化Snort报警数据的各属性的相似度;
S6.根据步骤S4所得到的打散后的Snort报警数据,计算每条Snort报警数据中各属性的权重值;在计算全局相似度的时候,需为每种报警属性设置一个权重W,用来衡量该属性在计算全局相似度中的重要性,采用熵值法来确定各个属性的权重值;
S7.根据步骤S5得到的各属性的相似度以及步骤S6得到的各属性的权重值计算每条Snort报警数据的全局相似度;并计聚合结果。
2.根据权利要求1所述的一种基于角标随机读取的Snort报警数据聚合方法,其特征在于,所述Snort报警数据包括由规则号、规则名称、优先级别、时间戳、原始IP、目的IP、协议类型、源端口、目的端口和报警类别10种属性构成的十元组。
3.根据权利要求1所述的一种基于角标随机读取的Snort报警数据聚合方法,其特征在于,所述步骤S3包括以下子步骤;
S31.对需预处理的标准化Snort报警数据进行集合封装;
S32.从本地MySQL数据库进行join操作生成所需的Snort报警数据表;对整个Snort报警数据文本按每两条顺序读取加载,若读取到最后一行则直接跳出循环,否则一一加载到集合;
S33.将Snort报警数据按照指定的时间属性升序排序,在排序后的数据集上移动一个的固定大小时间窗口,每次只检测时间间隔小于固定大小时间窗口内的Snort报警数据,判定它们是否匹配;
S34.以计数迭代不断循环比较,精简记录的方式减少Snort报警数据的数量。
4.根据权利要求1所述的一种基于角标随机读取的Snort报警数据聚合方法,其特征在于,所述步骤S4包括以下子步骤:
S41.对精简后的Snort报警数据进行集合封装;
S42.对整个Snort报警数据文本进行逐条顺序读取加载,若读取到最后一行则直接跳出循环,否则将加载到集合;
S43.对Snort报警数据按照时间属性进行升序排序和分月份划段处理,再对每个月内的数据进行随机打散排列。
5.根据权利要求1所述的一种基于角标随机读取的Snort报警数据聚合方法,其特征在于,在所述步骤S5中,所述各属性的相似度包括报警标识属性的相似度、报警名称属性的相似度、报警时间戳相似度和IP地址相似度。
6.根据权利要求1所述的一种基于角标随机读取的Snort报警数据聚合方法,其特征在于,所述步骤S7包括以下子步骤:
S71.计算每条报警数据的全局相似度;
S72.对计算全局相似度后的Snort报警数据进行集合封装;
S73.对整个Snort报警数据文本进行逐条顺序读取加载,若读取到最后一行则直接跳出循环,否则加载到集合;
S74.读取指定的每条报警数据相似度属性列的内容分别与期望阈值集合进行比较,并统计满足条件的报警条数;
S75.若全局相似度小于期望阈值,则该条报警数据为聚合所得到的报警数据结果;否则,则表明此条报警数据不是所期望的聚合范围。
7.根据权利要求5所述的一种基于角标随机读取的Snort报警数据聚合方法,其特征在于,在计算报警名称属性相似度时,使用Tableau Desktop进行统计分析,报警名称属性相似度计算公式设置如下:
其中,
8.根据权利要求5所述的一种基于角标随机读取的Snort报警数据聚合方法,其特征在于,
所述时间戳相似度通过以下方法计算获得:
将时间间隔
其中,
所述IP地址相似度通过以下方法计算获得,
采用无类别域间路由的格式对于IP地址的比较,将每两条报警数据相同的二进制位个数
计算公式设置如下:
其中,
9.根据权利要求4所述的一种基于角标随机读取的Snort报警数据聚合方法,在所述步骤S43中,先将每个月内随机打散后的中间报警数据用M集合存储,再统一用R集合重新存储得到最后的报警数据;其中,每遍历一次取两条报警数据所在行号得到生成的随机数与角标标记区进行比较,如果第一次出现,则将其存入并退出当层循坏,否则重新生成随机数取值再进行比较。
说明书
技术领域
本发明涉及一种数据聚合方法,具体涉及一种基于角标随机读取的Snort报警数据聚合方法。
背景技术
随着网络技术的快速发展,安全问题也越来越突出。通常,网络管理员采用多个网络安全设备同时上线工作,以应付多样化的黑客入侵方式。然而,由于各个网络安全设备工作时大多处于独立状态,很容易导致同一个攻击事件产生大量的冗余报警现象。报警数据聚合是解决网络入侵检测系统产生大量重复报警数据的重要手段,旨在将同一安全事件诱发的大量性质相同或相近的报警合并成一个超报警,能有效减少报警数据冗余,降低系统误报率,提高检测率,从而有利于网络管理员及时地掌握网络的运行状态,也便于后续的报警数据融合和关联分析。
Saad S等人为不同的攻击类型设置不同的阈值,采用顺序聚类的方法,将相似度高于阈值的报警进行合并,操作简单,适用范围广,但具有较强的次序依赖性和缺乏灵活性。
发明内容
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种基于角标随机读取的Snort报警数据聚合方法。
为实现上述目的及其他相关目的,本发明提供一种基于角标随机读取的Snort报警数据聚合方法,该方法包括以下步骤:S1.采集原始Snort报警数据;S2.对原始Snort报警数据进行标准化得到的标准化Snort报警数据;S3.对原始Snort报警数据进行预处理操作;S4.以随机生成角标的方式对步骤S2获得的标准化Snort报警数据进行随机打散排列;S5.计算打散后的标准化Snort报警数据的各属性的相似度;S6.计算各打散后的Snort报警数据之间的全局相似度并计算每条Snort报警数据中各属性的权重值;S7.根据步骤S5得到的各属性的相似度以及步骤S6得到的各属性的权重值计算每条Snort报警数据的全局相似度;并计聚合结果。
优选地,所述Snort报警数据包括由规则号、规则名称、优先级别、时间戳、原始IP、目的IP、协议类型、源端口、目的端口和报警类别10种属性构成的十元组。
优选地,所述步骤S3包括以下子步骤;
S31.对需预处理的原始Snort报警数据进行集合封装;S32.从本地MySQL数据库的相关Snort表进行join操作生成所需的报警数据表;对整个Snort报警数据文本按每两条顺序读取加载,若读取到最后一行则直接跳出循环,否则加载到集合;S33.将Snort报警数据按照指定的时间属性升序排序,在排序后的数据集上移动一个的固定大小时间窗口,每次只检测时间间隔小于固定大小时间窗口内的报警数据,判定它们是否匹配;
步骤S34.以计数迭代不断循环比较取最精简记录的方式使得重复率达到最低。
优选地,所述步骤S4包括以下子步骤:
S41.对精简后的Snort报警数据进行集合封装;S42.对整个Snort报警数据文本进行逐条顺序读取加载,若读取到最后一行则直接跳出循环,否则将加载到集合;S43.对Snort报警数据按照时间属性进行升序排序和分月份划段处理,再对每个月内的数据进行随机打散排列。
优选地,在所述步骤S5中,所述各属性的相似度包括报警名称属性相似度、报警标识属性的相似度、报警名称属性的相似度、报警时间戳相似度和IP地址相似度。
优选地,在所述步骤S6中,采用熵值法来确定各个指标的权重计算。
优选地,所述步骤S7包括以下子步骤:
S71.计算每条报警数据的全局相似度;S72.对计算全局相似度后的Snort报警数据进行集合封装;S73.对整个Snort报警数据文件进行逐条顺序读取加载,若读取到最后一行则直接跳出循环,否则加载到集合;S74.读取指定的每条报警数据总相似度属性列的内容分别与期望阈值集合进行比较,并统计满足条件的报警条数;S75.若全局相似度小于期望阈值,则该条报警数据为聚合所得到的报警数据结果;否则,则表明此条报警数据不是所期望的聚合范围。
优选地,在计算Snort报警数据名称属性相似度时,使用Tableau Desktop进行统计分析,Snort报警数据名称属性相似度计算公式设置如下:
其中,Simname(Alerti,Alertj)是报警数据的名称相似度值,Alerti和Alerti分别表示第i条和第j条报警数据,Alert_signame是报警数据的名称属性。
优选地,所述时间戳相似度通过以下方法计算获得:
将时间间隔Tinternal和预设的最小阈值tmin及最大阈值tmax进行比较,当时间间隔Tinternal小于tmin则相似度为0,当时间间隔Tinternal大于tmax则相似度为1,如果时间间隔Tinternal在tmin和tmax之间,计算公式设置如下:
其中,Simtimestamp(Alerti,Alertj)是报警数据时间戳的相似度值,Alerti和Alerti分别表示第i条和第j条报警数据;
所述IP地址相似度通过以下方法计算获得,
采用无类别域间路由的格式对于IP地址的比较,将每两条报警数据相同的二进制位个数r除以IP地址二进制位长度的值作为两个IP地址的相似度;
计算公式设置如下:
其中,Simip(Alerti,Alertj)是报警数据的IP相似度值,Alerti和Alerti分别表示第i条和第j条报警数据。
优选地,在所述步骤S43中,先将每个月内随机打散后的中间报警数据用M集合存储,再统一用R集合重新存储得到最后的报警数据;其中,每遍历一次取两条报警数据所在行号得到生成的随机数与角标标记区进行比较,如果第一次出现,则将其存入并退出当层循坏,否则重新生成随机数取值再进行比较。
如上所述,本发明所述的一种基于角标随机读取的Snort报警数据聚合方法,具有以下有益效果:
本发明打破了常规的数据顺序读取方式,采用角标随机读取算法实现报警数据按月分段,并且段内随机聚合比较,从而灵活计算相邻报警数据的属性相似度。同时,有效地提高了Snort报警数据聚合率和系统检测率,以及降低了系统误报率。
附图说明
为了进一步阐述本发明所描述的内容,下面结合附图对本发明的具体实施方式作进一步详细的说明。应当理解,这些附图仅作为典型示例,而不应看作是对本发明的范围的限定。
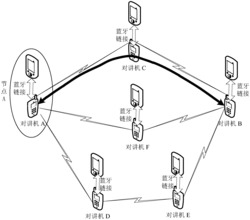
图1为实验整体采集环境架构拓扑图;
图2为原始报警数据入库后展示图;
图3为报警数据实时分析展示图;
图4为MySQL数据库中的Snort报警数据相关表;
图5为计数迭代式固定时间阈值的Snort报警数据预处理算法流程图;
图6为Snort报警数据精简前后对比,(a)为精简之前各类别的Snort报警数量,(b)为精简之前各类别的Snort报警数量占比,(c)为精简之后各类别的Snort报警数量,(d)为精简之后各类别的Snort报警数量占比;
图7为Snort报警数据角标随机读取算法流程图;
图8为Snort报警数据在Tableau工具里的展示图;
图9为Snort报警数据的名称属性在Tableau工具里的展示图;
图10为Snort聚合函数执行过程图;
图11为不同期望值下Snort报警数据聚合率对比,曲线1为发明所述方法的聚合率曲线,曲线2为“An SR-ISODATAalgorithm for IDS alerts aggregation”方法的聚合率曲线;
图12为本发明的方法流程图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
本发明提供一种基于角标随机读取的Snort报警数据聚合方法,其考虑到每对相邻报警数据若只依照常规的设置阈值检测时间窗内数据顺序比较存在缺乏灵活性。通过角标随机读取算法实现报警数据随机打散读取,从而有效地提高了Snort报警数据的聚合率,而且提高了入侵检测系统的检测性能。
如图12所示,一种基于角标随机读取的Snort报警数据聚合方法,包括步骤如下:
步骤1、搭建真实的数据采集OSSIM开源平台下的Snort分布式入侵检测系统;
步骤2、不同的IDS系统产生的报警数据格式不同,若直接聚合分析将造成很大不便。基于此,必须对报警数据进行统一的标准化,方便后续的聚合处理。本发明借鉴国际标准入侵检测消息交换格式DMEF(Intrusion Detection Message Exchange Format)来规范网络入侵检测系统NIDS(Network Intrusion Detection System)报警Snort格式。
步骤3、根据步骤1采集到的原始报警数据出发,采用数据清理、属性选择和数据过滤等方法来初步消除原始报警数据本身的缺陷,从中抽取能够用于聚合的主要属性并存储在数据库中,最后通过设置计数迭代式固定时间阈值过滤的方法来减少重复报警数据的数量。其中,重复报警数据是每两条报警数据间除了时间属性之外其他属性内容均相同的报警数据。
步骤4、根据步骤3所得到的精简后的Snort报警数据,通过改进入侵检测系统报警数据的读取方式,以随机生成角标的方式达到每条报警数据随机打散排列的目的。
步骤5、根据步骤4所得到的打散后的Snort报警数据,计算各属性的相似度。其中,考虑到自身采集的数据特点,将Snort报警数据加载到Tableau Desktop 10.04计算报警名称属性相似度。
步骤6、根据步骤4所得到的打散后的Snort报警数据,考虑到聚合关键取决于报警数据之间的全局相似度。在计算全局相似度的时候,需为每种报警属性设置一个权重W,用来衡量该属性在计算全局相似度中的重要性,通过客观的熵权计算方法计算每条报警数据的各个属性的权重值。
步骤7、根据步骤5和步骤6分别得到的Snort报警数据的各个属性相似度和权重,进行累乘加权计算得到每条报警数据的全局相似度。由于Snort收集到的大量报警数据中存在重复冗余数据,通过设置不同的期望值可以有效地去除一定的冗余达到进一步精简报警数据目的。
步骤8、验证所提出方法的有效性,还定义了误报率和检测率来作为评价系统检测性能的指标。
所述步骤1包括如下子步骤:
步骤1-1、基于集群分布式思想,通过在OSSIM环境下部署snort-agent1到snort-agent4共四个数据采集节点,snort-server作为服务端节点。实验整体采集环境架构拓扑图如图1所示。
步骤1-2、深入学习并利用Snort组件的相关报警规则,通过一系列的攻击实验,总共采集Snort报警数据63306条,并存储在MySQL数据库中。如图2所示。
所述步骤2包括如下子步骤:
步骤2-1、通过搭建入侵检测系统Snort并配合搭建LMAP、PHP、PEAR、ADOdb、BASE、HTML、MySQL、Libdnet、Libpcap、DAQ、Barnyard2的环境来直接对采集到的报警数据进行预先的查看和分析。
步骤2-2、系统搭建完成后,通过BASE登录,将实时监控网络数据包,并通过数据库输出接口将入侵日志传送到MySQL数据库中,数据分析控制台则可以通过数据库接口读取数据,并显示在BASE上,如图3所示。
并以每个Snort报警数据类别属性为分析基础,进一步细化得到的分类结果如表1所示。
表1原始Snort报警数据分类表
步骤2-3、从MySQL数据库将采集到的每条原始Snort报警数据借鉴IDMEF格式输出,每条Snort报警数据包括规则号、规则名称、优先级别、时间戳、原始IP、目的IP、协议类型、源端口、目的端口、报警类别等10种属性构成的十元组。每个属性的含义如表2所示。
表2报警数据属性含义表
所述步骤3包括如下子步骤:
步骤3-1、首先,对需预处理的Snort报警数据进行集合封装;
步骤3-2、然后,从本地MySQL数据库的相关Snort表进行join操作生成所需的报警数据表。其中,与snort产生的报警数据有关的共有7张表,分别sigature、event、icmphdr、iphdr、acid_event、sig_class、tcphdr和udphdr。本发明选取cid为主键,得到最后的数据表result_table,如图4所示。
同时,对整个Snort报警数据文本进行每两条顺序读取加载,若读取到最后一行则直接跳出循环,否则一一加载到集合。
步骤3-3、其次,将报警数据记录按照指定的时间属性升序排序,在排序后的数据集上移动一个的固定大小时间窗口(本实施例中固定大小的时间窗口为60s),每次只检测timeDiff小于窗口内的报警数据。判定它们是否匹配,以此来逐步减少比较次数,从而达到初步预处理过滤的目的。
匹配的条件是对于两条Snort报警数据,除了时间属性之外,其他的每个属性都相同,且两条数据的时间间隔小于固定大小时间窗。假设,满足上述的匹配条件,则可视为这两条snort报警数据为重复的报警数据,即取其中一条即可,达到了精简的目的。也就是后面的结果:从63306条,精简到了22162条。
步骤3-4、最后,以计数迭代不断循环比较取最精简记录的方式使得重复率达到最低。
计数迭代式固定时间阈值的Snort报警数据预处理整个执行过程如图5所示:
其中,为了衡量报警数据预处理的效果,实验分析中定义报警数据精简率来作为评价标准。假设原始报警数量为src_n个,精简后报警为dst_n个,其报警数据精简率公式如下:
ReduceRate用来反映聚合方法消除重复和冗余报警的效率,ReduceRate越大,表示精简越高,也就说明报警冗余去除的效果就越明显,提供给下一层数据聚合处理的数据源质量也就更高,精简前后各类别的报警数量和占比情况如图6所示。得到,src_n为63306条,dst_n为22162条,总的报警精简率为65%。
所述步骤4包括如下子步骤:
步骤4-1、首先,对精简后的Snort报警数据进行集合封装;
步骤4-2、然后,对整个Snort报警数据文本进行逐条顺序读取加载,若读取到最后一行则直接跳出循环,否则一一将加载到集合。
步骤4-3、最后,对数据按照时间属性进行升序排序和分月份划段处理,再对每个月内的数据进行随机打散排列。其中,先将每个月内随机打散后的中间报警数据用M集合存储,再统一用R集合重新存储得到最后的报警数据。其中,每遍历一次取两条报警数据所在行号得到生成的随机数与角标标记区进行比较,如果第一次出现,则将其存入并退出当层循坏,否则重新生成随机数取值再进行比较。
Snort报警数据角标随机读取算法整个执行过程如图7所示。
所述步骤5包括如下子步骤:
步骤5-1、考虑到自身采集的数据特点,将Snort报警数据加载到Tableau Desktop10.04计算报警名称属性相似度。Snort报警数据在Tableau工具里的展示图如图8所示。
步骤5-2、报警标识属性的相似度计算。其中,每两条Snort报警数据signature,sig_priority,ip_proto,lay4_sport和lay4_dport属性如果相同,则相似度设为0,如果不相同,那么相似度为1。
步骤5-3、报警名称属性的相似度计算。在计算Snort报警数据名称属性相似度时,使用Tableau Desktop进行统计分析,得出自定义的计算规则。Snort报警名称属性在Tableau工具里的展示图如图9所示。
其中,signame是对应于每条报警规则语句里的Msg。从每条报警数据该属性对应的字符串Snort Alert[1:2000419:0]值中提取2000419,考虑自身数据特点得知介于区间[2000334,2221030]和[2400001,2522312]。基于此,结合Tableau工具统计此属性的特点来计算出相似度值,其计算公式设置如下:
其中,Simname(Alerti,Alertj)是报警数据的名称相似度值,Alerti和Alerti分别表示第i条和第j条报警数据,Alert_signame是报警数据的名称属性。
步骤5-4、报警时间戳相似度的计算。将时间间隔Tinternal和预设的最小阈值tmin及最大阈值tmax进行比较,当时间间隔小于tmin则相似度为0,大于tmax则相似度为1,如果在tmin和tmax之间,则由公式计算得到。计算公式设置如下:
其中,Simtimestamp(Alerti,Alertj)是报警数据时间戳的相似度值。
步骤5-5、IP地址相似度的计算。对于IP地址的比较,采用无类别域间路由的格式进行分析,将每两条报警数据相同的二进制位个数r除以IP地址二进制位长度的值作为两个IP地址的相似度。计算公式设置如下:
其中,Simip(Alerti,Alertj)是报警数据的IP相似度值。
所述步骤6包括如下子步骤:
步骤6-1、选取权重计算方法。通常对于报警数据属性权重的确定计算方法,一般来说有两大类:一类是人为的主观判断来给对不同属性打分,比如基于一些专家的结论来进行打分、根据层次不同来进行分析、认为经验来进行判断等;另一类是客观方法,如熵权计算方法,主成分分析方法等。考虑到一般采用PCA需要数据比较难获取且存在相关及多重共线性问题,同时,它并不考虑因变量和自变量之间的关系,无法充分体现每个主成分的作用,因此本发明选用熵值法来确定各个指标的权重计算。
步骤6-2、选取权重计算工具MATLAB 2016a版本。
步骤6-3、各属性权重计算。在计算全局相似度的时候,需为每种报警属性设置一个权重W,用来衡量该属性在计算全局相似度中的重要性。通过MATLAB 2016计算得知,权重矩阵为[0.0001 0.0452 0.01300.0471 0.0005 0.0046 0.0353 0.2721 0.5821]。
所述步骤7包括如下子步骤:
步骤7-1、每条报警数据的全局相似度计算。结合步骤5得到的各个属性相似度和步骤6得到的各个属性权重,进行累乘加权计算。计算公式设置如下:
其中,Simsum(Alerti,Alerti+1)是报警数据的总相似度,i,j是计算属性权重时报警数据所在的行号,c是报警数据的属性所在的列号,Wc是报警数据各个属性的权重,Alert(i)attributes和Alert(j)attributes分别表示第i条和第j条报警数据的每个属性的集合,n是报警数据的条数。
步骤7-2、首先,对计算全局相似度后的Snort报警数据进行集合封装;
步骤7-3、然后,对整个Snort报警数据文件进行逐条顺序读取加载,若读取到最后一行则直接跳出循环,否则一一将加载到集合。
步骤7-4、其次,读取指定的每条报警数据总相似度属性列的内容分别与期望阈值集合进行比较,并统计满足条件的报警条数。
步骤7-5、聚合函数计算。若全局相似度小于期望阈值,则统计满足此条件的报警数据,并可视为作为聚合所得到的报警数据结果。否则,则表明此条报警数据不是所期望的聚合范围。
Snort聚合函数整个执行过程如图10所示。
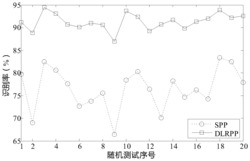
通过训练取期望值H在不同值时聚合效果对比,结果如图11所示。从图11可以看出,在H<0.6时聚合率均低于50%且有小幅度的上升,在0.7≤H≤0.9时聚合率维持在90%左右并保持平稳。同时,期间发生了一次较大幅度的增长跳跃变化,通过分析,变动期望值可以将相似度较高的报警数据合并为一类从而进行下一步分析,由此生成超报警信息库,因而将期望值设为0.7。
由此可见,在一定程度上本发明提出的方法从反向思维来计算报警数据属性相似度,相比常规手段的顺序聚合而言,更能使得聚合率提高并维持平稳。
所述步骤8包括如下子步骤:
步骤8-1、根据以下规则对收集到的报警数据进行了标定。如果一条报警数据满足以下三个条件:(1)源IP地址符合模拟的攻击IP地址;(2)目的IP地址符合模拟攻击的受害机IP地址;(3)报警的时间戳在模拟攻击所发生的时间窗之内。则该条报警被标记为真报警,否则就被称为误报警。
步骤8-2、经标定后,数据集含有45002条真报警和18004条误报警。以70%随机抽取作为训练数据集,30%作为测试数据集。类似Pietraszek定义的反映报警处理性能的指标,给出了一个混合矩阵C,如表3所示,表中“+”代表真报警(攻击报警),“-”代表误报警。
表3混合矩阵C
步骤8-3、本发明为了验证所提出方法的有效性,还定义了误报率和检测率来作为评价系统检测性能的指标。基于此,定义如下的一组反映报警处理性能的指标。
系统检测率(TP)计算公式如下所示:
TP=C11+C12/(C11+C12+C21+C22) (6)
系统误报率(FP)计算公式如下所示:
FP=C21/(C21+C22) (7)
C11表示原标定报警数据是真报警(+),做检测算法后得到分类结果还是真报警(+)的数据条数的和。C12表示原标定报警数据是真报警(+),做检测算法后得到分类结果是误报警(-)的数据条数的和。C21表示原标定报警数据是误报警(-),做检测算法后得到分类结果是真报警(+)的数据条数的和。C22都表示原标定报警数据是误报警(-),做检测算法后得到分类结果还是误报警(+)的数据条数的和。
步骤8-4、使用SPSS里的CHAID树算法作为Snort报警数据检测系统的检测方法,系统分别采用本发明的聚合方法(简称方法1)和《An SR-ISODATA algorithm for IDSalerts aggregation》的聚合方法(简称方法2)进行检测性能比较。两者的系统检测率和误报率对比情况如表4所示。
表4系统检测率与误报率对比
由表4可知,方法1的检测率为89.64%,高出方法2的检测率13%左右,在一定程度上说明对真报警还是误报警的判定有着明显的作用,而且误报率也有所降低。
步骤8-5、同时,为了对比两种方法的运行效率,定义了系统检测平均运行时间(TA)如下所示:
TA=T/n (8)
其中,T为检测方法运行的总时间(ms),n为测试数据样本总数,两种方法的平均运行时间对比见表5所示。
表5平均运行时间对比
由表5实验得出,相比于方法2,方法1的系统检测平均运行时间略少,可以稍微加快系统检测运行效率。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
一种基于角标随机读取的Snort报警数据聚合方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。














动态评分
0.0