








专利摘要
异步电路和异步技术被描述为用于无需同步到共用时钟的异步处理。作为示例,提供了两种基于单轨握手协议的用于高吞吐量异步电路的具体节能流水线模板。每条流水线包括多个逻辑级。通过消除用于所有输入令牌和用于所有中间逻辑节点的有效的和中立的检测逻辑门而最小化握手开销。这两种模板都能够在显著压缩每个流水线块内的逻辑的重要量的同时维持快速循环时间。
权利要求
1.一种无需同步到公共时钟的用于异步处理的设备,其包括:
彼此连接以形成异步处理流水线的两个或更多个异步电路,每个异步电路包括:
第一输入导线,接收并传送第一输入信号;
第一输入确认导线,接收来自产生所接收到的第一输入信号的另一个异步电路的第一输入确认信号;
第一异步处理模块,处理所述第一输入信号以产生第一输出信号;
第一完成检测处理模块,接收所述第一输入确认信号和来自所述第一异步处理模块的所述第一输出信号,并可被操作以产生第一输出确认信号,所述第一输出确认信号指示完成对接收到的所述第一输入信号的处理以及所述第一输出信号的生成;
第一输出确认导线,接收来自所述第一完成检测处理模块的所述第一输出确认信号,并且输出所述第一输出确认信号;和
第一输出导线,接收并传送由所述第一异步处理模块生成的所述第一输出信号。
2.根据权利要求1所述的设备,其中:
由所述第一输入导线传送的所述第一输入信号是通过每次仅使所述第一输入导线的单个线生效而编码的;和
由所述第一输出导线传送的所述第一输出信号是通过每次仅使所述第一输出导线的单个线生效而编码的。
3.根据权利要求1所述的设备,其中:
所述第一输入导线的数量不同于所述第一输出导线的数量。
4.根据权利要求1所述的设备,其中:
所述第一输入导线的数量等于所述第一输出导线的数量。
5.根据权利要求1所述的设备,其中:
所述第一异步处理模块包括:
第一下拉逻辑电路,其被连接到所述第一输入导线;和
第一上拉逻辑电路,其被连接以接收所述第一下拉逻辑电路的输出,并可被操作以产生生成所述第一输出信号所基于的输出。
6.根据权利要求5所述的设备,其中:
所述第一异步处理模块进一步包括:
第二下拉逻辑电路,其被连接以接收所述第一上拉逻辑电路的输出;和
第二上拉逻辑电路,其被连接以接收所述第二下拉逻辑电路的输出,并可被操作以产生生成所述第一输出信号所基于的输出。
7.根据权利要求1所述的设备,其中:
所述第一异步处理模块包括:
第一下拉逻辑电路,其被连接到所述第一输入导线;
第一反相器电路,其被连接以接收所述第一下拉逻辑电路的输出;
第二下拉逻辑电路,其被连接以接收所述第一反相器电路的输出;和
上拉晶体管,连接以接收所述第二下拉逻辑电路的输出,并可被操作以产生生成所述第一输出信号所基于的输出。
8.根据权利要求1所述的设备,其中每个异步电路进一步包括:
第二输入导线,接收并传送第二输入信号;
第二输入确认导线,接收来自产生所述接收到的第二输入信号的另一个异步电路的第二输入确认信号;
第二异步处理模块,处理所述第二输入信号以产生第二输出信号;和
第二输出导线,接收并传送由所述第二异步处理模块生成的所述第二输出信号。
9.根据权利要求8所述的设备,其中:
所述第一输入信号和所述第二输入信号不同。
10.根据权利要求8所述的设备,其中:
彼此连接以形成所述处理流水线的所述两个或更多个异步电路包括第一下游异步电路,其被连接到所述第一输出导线以接收所述第一输出信号;
其中所述设备进一步包括第二下游异步电路,其被连接到所述第二输出导线以接收所述第二输出信号;
其中所述第一完成检测处理模块被耦接以进一步接收来自所述第二异步处理模块的所述第二输出信号,并且其可被操作以产生所述第一输出确认信号,所述第一输出确认信号指示完成由所述第二异步处理模块对所述接收到的第二输入信号的处理和由所述第一异步处理模块对所述接收到的第一输入信号的处理以及所述第一和第二输出信号的生成;和
其中所述第一和第二下游异步电路被耦接以接收所述第一输出确认信号的拷贝。
11.根据权利要求1所述的设备,其包括:
所述第一完成检测处理模块被耦接到所述第一输入导线,并可被操作以在完成由所述第一异步处理模块对所述接收到的第一输入信号的处理以及生成所述第一输出信号后重置所述第一输入导线上的信号。
12.根据权利要求11所述的设备,其中:
所述第一完成检测处理模块包括放电电路,其被耦接到所述第一输入导线以产生重置所述第一输入导线的放电信号;
其中所述放电电路包括NOR门,其产生作为所述放电信号的NOR门输出,并且接收由所述第一完成检测处理模块生成的、并且与所述第一输出确认信号相关联的第一信号,以及由所述第一完成检测处理模块生成的、并且与所述第一输出确认信号相关联的的第二信号,所述第二信号相对于所述第一信号具有延迟。
13.根据权利要求12所述的设备,其中:
所述放电电路包括产生具有所述延迟的所述第二信号的放电脉冲生成器。
14.根据权利要求13所述的设备,其中:
所述放电脉冲生成器包括一系列反相器,以通过提供用于提高时间裕度和所述异步处理的稳健性的额外延迟的方式生成所述延迟。
15.根据权利要求1所述的设备,其中:
所述异步处理流水线中的两个相邻连接的异步电路通过这两个相邻连接的异步电路中的相对另一异步电路更上游的一个异步电路的第一输出确认导线以及第一输出导线来进行通信,且不需要从所述下游异步电路到所述上游异步电路的确认反馈。
16.一种无需同步到公共时钟的用于异步处理的方法,其包括:
串联连接多个异步电路来形成异步处理流水线,以允许一个异步电路与下一个相邻的异步电路进行通信,从而在每个异步电路执行信号处理的同时,无需公共时钟也可进行通信;
通过引导来自两个相邻连接的异步电路中的相对于另一异步电路更上游的一个异步电路的信号,来操作所述异步处理流水线中的两个相邻连接的异步电路进行通信,并且不需要从所述下游异步电路到所述上游异步电路的确认反馈;
通过使用多个导线来传送输入或输出信号,以及通过每次仅使多个导线中的单个线有效来操作每个异步电路以编码所述输入或输出信号;和
操作每个异步电路以使用单个导线来发送确认信号到所述下游异步电路,所述单个导线是用于传送从所述上游异步电路到所述下游异步电路的输出信号的导线之外的导线。
17.根据权利要求16所述的方法,其中:
每个异步电路包括:
输入导线,接收并传送输入信号;
输入确认导线,接收来自产生接收到的输入信号的上游异步电路的输入确认信号;
异步处理模块,处理所述输入信号以产生输出信号;
完成检测处理模块,接收所述输入确认信号和来自所述异步处理模块的所述输出信号,并可被操作以产生输出确认信号,所述输出确认信号指示完成对所述接收到的输入信号的处理以及所述输出信号的生成;
输出确认导线,接收来自所述完成检测处理模块的所述输出确认信号,并且输出所述输出确认信号;和
输出导线,接收并传送由所述异步处理模块生成的所述输出信号;
其中所述方法进一步包括:
在完成所述异步处理模块对所述接收到的输入信号的处理以及所述输出信号的生成之后,重置所述输入导线上的信号。
18.根据权利要求17所述的方法,其包括:
在重置所述输入导线上的信号时引发延迟以提高时间裕度和所述异步处理的稳健性。
19.根据权利要求17所述的方法,其中:
所述输入导线的数量不同于所述输出导线的数量。
20.根据权利要求16所述的方法,其包括:
配置所述异步处理流水线中的异步电路,使其包括两个或更多异步处理级。
21.根据权利要求20所述的方法,其中:
所述异步电路的所述异步处理模块包括:
第一下拉逻辑电路,其被连接到所述输入导线;
第一上拉逻辑电路,其被连接以接收所述第一下拉逻辑电路的输出,并且其可被操作以产生生成所述输出信号所基于的输出;
第二下拉逻辑电路,其被连接以接收所述第一上拉逻辑电路的所述输出;和
第二上拉逻辑电路,其被连接以接收所述第二下拉逻辑电路的输出,并且其可被操作以产生生成所述输出信号所基于的输出。
22.根据权利要求20所述的方法,其中:
所述异步电路的所述异步处理模块包括:
第一下拉逻辑电路,其被连接到所述第一输入导线;
第一反相器电路,其被连接以接收所述第一下拉逻辑电路的输出;
第二下拉逻辑电路,其被连接以接收所述第一反相器电路的输出;和
上拉晶体管,其被连接以接收所述第二下拉逻辑电路的输出,并且其可被操作以产生生成所述输出信号所基于的输出。
说明书
优先权及相关申请
根据35U.S.C.§119的规定,本专利申请要求于2011年8月3日提交的,题为“用于高性能异步电路的节能流水线模板”的美国临时申请No.61/514,589的优先权,以及于2011年8月5日提交的,题为“用于高性能异步电路的节能流水线模板”的美国临时申请No.61/515,387的优先权。以上两件申请的全部公开内容都通过引用方式作为本专利文献的一部分并入本文。
联邦赞助研究或开发
本发明得到了由国家科学基金(NSF)授予的CNS-0834582和CCF-042827的拨款的政府资助。政府对本发明享有一定的权利。
背景技术
用于信号处理的集成电路可被配置为同步电路和异步电路。同步电路基于控制时钟信号进行操作以使得同步电路内的不同处理组件的操作同步。同步电路内的不同处理组件通常操作于不同的速度。这些不同处理组件的同步倾向于要求控制时钟信号的时钟速度适应这些处理组件的最低处理速度。许多数字处理器都是这样的同步处理设备,其包括用于个人计算机、移动电话、移动计算设备和其他执行数字信号处理的设备中的各种微处理器。可以通过加快时钟速度来增加同步处理器的速度,其中该时钟速度强制加快指令的执行。
大多数同步数字处理器都是基于CMOS技术构建的。将CMOS技术缩小到超深亚微米范围内对于数字电路设计者来说是严峻的挑战。随着晶体管阈值电压被固定[Horowitz2007],VDD随着晶体管尺寸的减小缓慢降低。因此,电路性能的提升伴随着能量消耗的增加。节能问题已经成为当代芯片设计的主要设计约束。此外,深亚微米范围内的工艺变化使得设备不太稳健,并且这个问题使得同步设计者越来越难以克服与时钟电压转换率(clock skew rate)和时钟分配相关的一些问题[Dally和Poulton1998]。
在另一方面,通过将不同的处理组件操作于其结构和操作环境或条件所允许的最快速度下,异步电路不需要将不同处理组件同步到公共时钟信号。异步电路内的流水线中的两个处理组件通过握手信令进行相互间的通信。这种异步处理器可以通过基于异步处理特有特性的流水线技术来被优化以进行快速处理,并可被配置为具有更低的设计复杂度、更高的能量效率、更好的平均情况下的性能。康奈尔大学的Raiit Manohar于2000年出版的题为“异步计算机架构的案例”的文章中已经描述了异步电路的一些特点和优势(http://vlsi.cornell.edu/~rajit/PS/async~case.pdf)。
发明内容
本发明描述了异步电路和异步技术。
在一个方面,提供了一种用于无需同步到公共时钟的异步处理的方法,其包括串联连接多个异步电路来形成异步处理流水线,以允许一个异步电路与下一个相邻的异步电路进行通信,从而在每个异步电路执行信号处理的同时,无需公共时钟也可进行通信。该方法进一步包括通过引导来自两个相邻连接的异步电路中的相对于另一异步电路更上游的一个异步电路的信号,来操作异步处理流水线中的两个相邻连接的异步电路进行通信,并且不需要从下游异步电路到上游异步电路的确认反馈;通过使用多个导线来传送输入或输出信号,以及通过每次仅使多个导线中的单个线有效来操作每个异步电路以编码输入或输出信号;和操作每个异步电路以使用单个导线来发送确认信号到下游异步电路,该单个导线是用于传送从所述上游异步电路到所述下游异步电路的输出信号的导线之外的导线。
在另一个方面,提供了一种用于无需同步到公共时钟的异步处理的设备,其包括串联形成异步处理流水线的两个或更多个异步电路。每个异步电路包括接收并传送输入信号的输入导线,接收来自产生接收到的输入信号的上游异步电路的输入确认信号的输入确认导线,处理输入信号以生成输出信号的异步处理模块,接收输入确认信号和输出信号、并且可被操作以产生输出确认信号的完成检测处理模块,该输出确认信号指示完成对接收到的输入信号的处理以及生成输出信号;接收来自完成检测处理模块的输出确认信号并输出输出确认信号的输出确认导线;和接收并传送由异步处理模块生成的输出信号的输出导线。
已描述了以上和其他方面的多种实现方式。例如,提供了用于高吞吐量异步电路的节能流水线模板的两个例子。这些教导的两个模板(被称为N-P和N-反相器流水线)使用单轨握手协议(single track handshake protocol)。在每个流水线内都具有多个逻辑级。这些教导的技术限制了与输入令牌和流水线模板内的中间逻辑节点相关联的握手管理开销(overheads)。每个模板将大量的逻辑打包在单个级内,同时保持仅有18次转换的快速循环时间。我们流水线电路的噪声和时间稳健性约束被针对所有工艺范围(process corner)进行了量化。提供了一种基于宽NOR门的完成检测方案,该方案特别是随着输出数量的增加可导致可观的延迟和节能。为了完全量化所有的设计权衡,提供了一种8×8位布斯编码(Booth encoded)的阵列乘法器的三个单独流水线实现方式。相比于其他的QDI流水线实现方式,N-反相器和N-P流水线实现方式能够分别降低38.5%和44%的能量延迟乘积。使用N-反相器和N-P流水线模板,整体乘法器延迟可以分别降低20.2%和18.7%,同时可以降低35.6%和46%的总晶体管宽度。
在附图、说明书和权利要求中更详细的描述了所描述的异步处理的这些和其他方面以及它们的实现方式。
附图说明
图1表示异步流水线:发送方-接收方握手协议。
图2表示双入单出的PCeHB模板。
图3表示单轨握手协议。
图4表示N-P流水线模板。
图5表示确保正确性的Ack信号。
图6表示N-反相器流水线模板。
图7表示用于大量输出的多级c-元件树型完成检测逻辑。
图8表示用于大量输出的完成检测逻辑。
图9表示多种完成检测方案的延迟比较。
图10比较针对所选择信号的不同达到顺序的完成检测能耗。
图11表示针对具有最新信号的变化延迟的12个输出的C-元件与宽NOR比较。
图12表示针对具有最近信号的变化延迟的15个输出的C-元件与宽NOR比较。
图13比较C-元件与宽NOR:总晶体管宽度对比。
图14表示具有两个输出复制的8选1多路选择器。
图15表示针对不同流水线类型的8选1多路选择器设计权衡。
图16表示依赖于输出数量的吞吐量。
图17表示噪声裕量分析。
图18表示关于流水线吞吐量的串并转换器强度的效果。
图19表示关于每次操作能量的串并转换器强度的效果。
图20表示使用PCeHB流水线的8×8位乘法器架构。
图21表示使用N-P流水线的8×8位乘法器。
图22表示N-P和N-反相器流水线的功率消耗的明细。
图23表示三个不同流水线类型的8×8位乘法器吞吐量与能量对比。
图24表示三个不同流水线类型的8×8位乘法器能量-延迟分析。
具体实施方式
具有对工艺变化的稳健性、没有全局时钟依赖和固有的完美时钟门控的异步准延迟无关(Quasi-Delay-insensitive,QDI)电路代表了未来芯片设计的可行设计替代方案。QDI电路已被用于多种高性能、节能异步设计[Sheikh和Manohar2010][D.Fang和Manohar2005],其包括完全实现和制造的异步微处理器[Martin等1997]。在实现不同的并行流水线处理之间的握手时,QDI电路会损失一些能效增益。为了确保用于每次握手的QDI行为,流水线内的每次上游和下游转换被检测,这导致大量的握手电路和能量开销。高吞吐量QDI流水线的每一级仅包括少量逻辑。高吞吐量所需要的大量流水线级使得握手开销占总功耗的一大部分。可以通过提高高性能异步流水线的能效而不牺牲稳健性的方式来实现本文档中所描述的技术。为了规避高握手开销的问题,提供了两种示例性流水线模板,以通过采取一些易于满足的定时假设的优点来最小化握手电路。这些教导的流水线使用单轨握手协议[van Berkel和Blik1996]。可在保持具有18次转换的超快循环时间的同时,通过在单个流水线中打包多个逻辑级来增加逻辑密度。为了量化这些教导的流水线模板的实际性能和能效,提供了8×8位布斯编码的阵列乘法器的三种分别的流水线模板。相比于标准QDI流水线实现方式,我们的流水线实现方式分别降低38.5%和44%的能量延迟乘积。整体乘法器延迟降低了20.2%和18.7%,同时总晶体管宽度降低了35.6%和46%。
高性能异步电路由许多并行进程组成。相对于使用全局时钟来同步不同流水线级之间的数据令牌的同步电路,这些异步并行进程使用握手协议来与彼此通信。这些并行进程经常被表示为细粒度流水线电路。细粒度流水线电路使用用于进程之间通信的指定通道。通道包括一束导线和通信协议以从发送器传输数据到接收器。存在多种异步细粒度流水线实现方式[Lines1995][Williams1991][Sutherland和Fairbanks2001][Ferretti和Beerel2002]。这些电路模板的稳健族(robust family)被称为准延迟无关(QDI)电路。
QDI电路模板使用N选1(1-of-N)编码通道以在不同并行进程之间进行通信。在一个N选1通道中,全部的N个导线被用来编码数据,但每次仅有一个导线有效。大多数高吞吐量QDI电路使用2选1(双轨)或4选1编码。在如图1所示的4选1编码通道通信中,通过设置四个数据道中的一个来指示有效性,并且通过重置所有四个数据道来指示中性。在大多数高速QDI电路所使用的四相握手进程中,发送方进程通过在道上发送数据,也就是使数据道中的一个有效,来启动通信。接收方进程检测数据的存在,并且在一旦不再需要该数据时发送确认。此时,发送方进程重置其所有数据道。接收方进程检测输入令牌的中性(neutrality)。一旦它准备好接收新数据令牌,其就消除确认信号。重复循环。
预充电使能半缓存(Pre-Charge enable Half-Buffer,PCeHB)[Fang和Manohar2004]模板是在[Line1995][Williams1991]中所提出的预充电半缓存(Pre-Charge Half-Buffer,PCHB)模板的略微修改版本,其主要用于大多数高吞吐量QDI电路中。它具有18次转换的循环时间,并且既小又快。在PCeHB流水线中,可通过下拉NMOS堆栈来实现逻辑函数的计算。使用单独的逻辑门来检查输入和输出有效性和中性。实际计算与数据锁存相结合,从而避免了显式寄存器(explicit register)的开销。PCeHB模板可以采用多个输入并且产生多个输出。图2表示简单的双入单出PCeHB模板。L0和L1是输入到模板的两个道,R是双轨输出。PCeHB模板具有两次转换的前向延迟。每个流水线级通过使用NMOS下拉堆栈驱动来计算逻辑,该NMOS下拉堆栈后接有用于驱动输出的反相器。为了理解PCeHB模板中的18次转换的循环时间,我们假设串联的两个PCeHB流水线随着时间(t)递增而发生的逻辑转换。
-t=0时,输入令牌到达第一PCeHB流水线块。
-t=2时,第一流水线块产生其输出。
-t=4时,第二流水线块产生其输出。
-t=5时,第一个块中的L.e变低。
-t=7时,下一个块中的L.e,也就是第一块的R.e变低。这表示不再需要来自第一流水线块的输出,可以进行重置。
-t=9时,使第一个块中的en信号失效。
-t=10时,对第一个块中的R道预充电。
-t=11时,重置第一个块的输出,即R道。
-t=12时,对第二个块中的R道预充电。
-t=14时,第一个块中的L.e变高。
-t=16时,第二流水线级中的L.e变高。这指示第二流水线级中的输入的中性。
-t=18时,设置第一流水线块中的en,这指示该流水线准备好接收新的输入令牌并计算新的输出。
图2中高亮的逻辑门没有用于实际计算,仅仅是握手协议所需要的。这包括完成检测信号(L.e)和en信号的生成,该en信号被用于使能流水线级中的计算或锁存。随着输入到PCeHB流水线级的输入数量的增加,输入有效性树变得更加复杂,并且可能需要额外的级进行计算,这将导致循环时间的增加。随着输出数量的增加,情况也是一样。因此,对于高吞吐量电路,每个PCeHB级仅包括具有少量输入和输出的少量逻辑。由于可能需要复制令牌以供各个进程使用,而每个进程执行其自身的有效性和中性检查,因此在功耗和晶体管数量方面,这导致明显的握手开销。表格1表示使用PCeHB模板实现的简单的全加器电路的功耗明细。实际逻辑仅消耗了31%的总功耗,而其余的都用在实现握手协议了。这是明显的功率开销,而随着PCeHB模板的输入和输出增加更多,这会变得更加糟糕。表格1中的结果是主要的激励因素之一,其提示我们考虑具有更少握手电路的可替换的流水线方案。
相对于QDI流水线,细粒度捆绑数据流水线具有即时区域(instant area)的优势,这是因为它们使用单道编码数据通道[Sutherland和Fairbanks2001]。然而,捆绑数据流水线具有比QDI电路多得多的时间消耗,这使得它们不够稳健。捆绑数据流水线包括单独的控制电路,其用以同步不同流水线级之间的数据令牌。控制电路包括匹配的延迟线,这些延迟线的延迟被设置为大于流水线的逻辑延迟与一定裕度的和。在[Sutherland和Fairbanks2001]中,为了正确的操作,设计师必须保证控制电路的延迟满足所有设置,并保持如同同步设计中那样的时间需求。由于我们的目标是设计一流水线模板,其具有与预充电逻辑类似的稳健定时和前向延迟,因此在我们的工作中我们没有考虑任何捆绑数据流水线实现方式。
表1:PCeHB全加法器流水线:功率明细
QDI电路可被配置得稳健,这是因为可以检测QDI流水线模板内的每个上和下转换。但是这样的稳健性的代价是如表格1所示的流水线握手电路中的功率消耗。较高握手开销是限制QDI电路大范围使用的严重约束之一,尤其是用于具有大量输入和输出信号的逻辑操作(诸如32位乘法器)。在这项工作中,我们试图提高高性能异步流水线的能效而不牺牲稳健性。为此,我们为最终的流水线模板保留以下目标:
-保持每级的循环时间在18次转换内。
-增加逻辑与握手的比率。握手功率开销必须小于总流水线功率的50%。
-不允许增加总晶体管数量。
-所有定时假设要么是等时分岔假设(isochronic fork assumption)[Martin1990],要么是具有与半循环定时假设[LaFrieda和Manohar2009]至少相同的定时裕度,根据半循环定时假设,任意两个延迟竞争之间的转换数量的差必须至少为4.5次转换。
-输入和输出的停止不应该影响正确操作。我们设想这些电路被用于被QDI接口封装的大量本地逻辑(例如乘法器),而非被全局地使用。在过去,研究者已经尝试通过增加额外的逻辑级来增加QDI流水线的逻辑密度[Beerel等2009],但是这仍然没有得到期望的握手开销的降低,而且还导致循环时间的增加。为了分析这种影响,我们假设通过增加额外逻辑级来增加流水线的逻辑深度。为了顺应QDI行为,必须确认所有新近创建的内部信号的上和下转换。这既可以通过使用完成检测逻辑明确地检查每次转换来实现,正如PCeHB模板中所采用地,也可以通过使用弱条件[Seitz1980]来实现,使用弱条件也即输出有效表明输入有效(通过逻辑堆栈中的附加N-FETS来检查),而输出中立表明输入中立(通过逻辑堆栈中的附加P-FETS来检查)。[Seitz1980][Lines1995]中阐述了弱条件的性能局限性。在显式检查的情况下,由于所有的额外有效性和中性检测逻辑门的存在,产生了与其相关的高握手开销。与新增加的逻辑门和完成检测逻辑门相关联的所有这些额外转换限制了能效增益。
因此明显地需要超越仅为每个流水线级增加额外逻辑门的方式。为了提高高吞吐量异步流水线的能效,我们公开了QDI电路中替代的握手协议和一些定时假设。
在一种四相握手协议中,流水线级需要检测输入和输出这两者的有效性和中性。在四相协议的后半段期间,当流水线等待重置输入和输出时,没有实际逻辑正被计算,但是其仍然消耗大约一半的循环时间。此外,消耗在检测输入和输出中性的功率与消耗在检测输入和输出有效性的功耗相当。因为这些特性,四相握手协议显然不是针对节能考虑的理想选择。单道握手[van Berkel和Bink1996]协议试图通过实际地消除中性阶段来克服四相握手协议的缺点。图3表示单道握手协议的概述。发送方进程通过发送数据令牌启动通信。接收方使用这些数据来计算其逻辑。一旦不再需要这些数据,接收方进程就通过使用如图3所示的NMOS晶体管将数据线拉低而重置输入令牌本身,以取代发送确认信号回到发送方进程。有多少数据线就有多少NMOS放电晶体管,但为了简明,图3中我们仅示出了一个放电晶体管。随着数据线被拉低,发送方检测令牌消耗,并且准备好发送下一个令牌。因此,消除了与四相协议的第二部分相关联的转换。
对于单道握手模板,一些现有工作专注于使用单道握手协议来将异步流水线的循环时间降低到10次转换以下,而不是使用这些额外的转换来提高逻辑密度和能效。Ferretti等[2002]提供基于单道握手协议的异步流水线模板的族。与高吞吐量QDI电路相似,它们的流水线模板的每一个都仅包括少量的逻辑。此外,他们的6转换循环时间流水线使用一些非常紧张的定时裕度,这可能需要大量的布图后模拟验证(post-layout analog verification)。单道电路已被用于Gasp[Sutherland和Fairbanks2001]捆绑数据流水线的控制路径。然而,流水线的实际数据路径并不适用单道握手协改。
此处所描述的例子采用用于流水线模板的单道握手协议来增加每个流水线级的逻辑密度和能效。
QDI电路对过程变化是高容忍的,这是因为QDI流水线内的每次转换都将被检测。等时分岔假设[Martin1990]是QDI设计唯一允许的定时假设,其中等时分岔假设指出,导线分支之间的延迟差相比于读取它们值的逻辑的门延迟来说是微不足道。最近,LaFrieda等人[2009]提出了另一种常用于QDI实现方式的定时假设,其可被称为半循环定时假设(HCTA)。根据HCTA,用于PCeHB类型模板的任意两个延迟竞争之间的转换数量之差必须至少为4.5次转换。所得到的模板被称为松弛QDI模板(Relaxed QDI template),其被证明是非常稳健的。LaFrieda等人[2009]利用HCTA来提高他们的四相握手协议流水线的能效。在此描述的技术可以通过下述方式实现,该方式通过引入在任意两个相关延迟竞争之间具有至少5次门转换的裕度的定时假设来提高单道握手协议流水线的能效。
图4和图6表示异步处理模板的两个例子。这两个例子是用于无需同步到公共时钟的异步处理的设备设计的实现方式。这样的设备包括两个或更多个异步电路,其串联以形成异步处理流水线。每个异步电路包括接收并传送输入信号的输入导线,接收来自产生所接收到的输入信号的上游异步电路的输入确认信号的输入确认导线,处理输入信号以产生输出信号的异步处理模块,接收输入确认信号和输出信号的完成检测处理模块,该完成检测处理模块可被操作以产生输出确认信号,输出确认信号指示完成对接收到的输入信号的处理和输出信号的生成。该设备还包括接收来自完成检测处理模块的输出确认信号并输出输出确认信号的输出确认导线,和接收并传送由异步处理模块生成的输出信号的输出导线。
在这些实现方式中,异步电路的输入导线的数量可以不同于输出导线的数量,只要输入或输出导线的数量匹配于流水线中的下一个异步电路。另外,每个异步电路可包括两个或更多个处理流水线。因此,例如在上述设备中,每个异步电路可包括接收并传送第二输入信号的第二输入导线,接收第二输入确认信号的第二输入确认导线,该第二输入确认信号来自产生所接收到的第二输入信号的另一个上游异步电路;处理第二输入信号以产生第二输出信号的第二异步处理模块;和接收并传送由第二异步处理模块生成的第二输出信号的第二输出导线。第二异步处理模块可以独立于异步处理模块地被操作。在图5的例子中,异步处理电路A包括两个异步电路,其处理相同的输入以产生用于两个下游异步电路B和C的两个不同的输出。
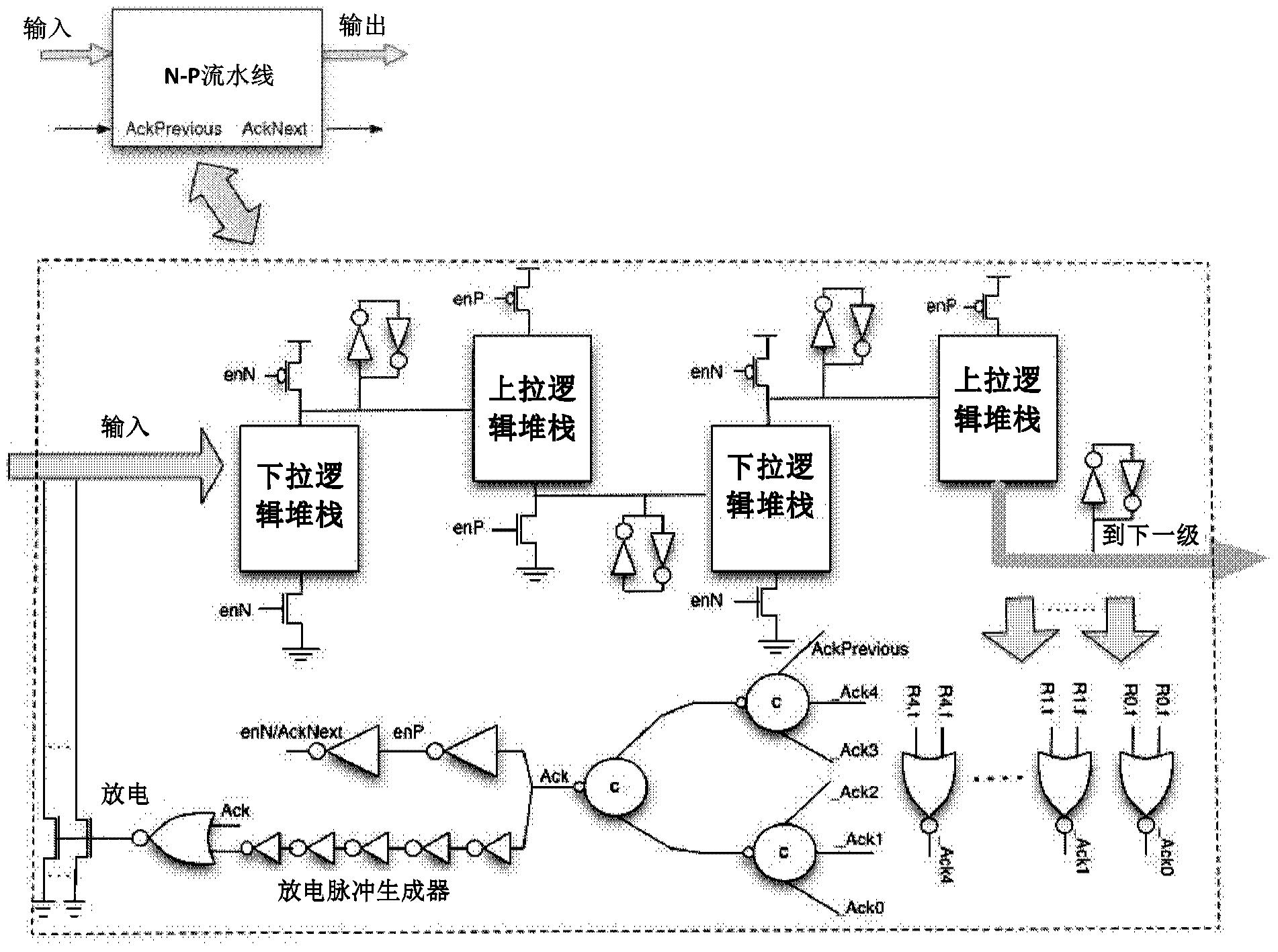
图4表示我们的第一模板的更详细描述的例子,第一模板具有基于单道握手协议的由信号R0-R4标示的5个任意双道输入。该异步模板被称为模板N-P流水线,这是因为其使用NMOS下拉和PMOS上拉堆栈来计算逻辑。每个NMOS和PMOS级可包括多个逻辑堆栈。然而,为了简明起见,图4中并未示出多个逻辑堆栈和全局重置信号。
PCeHB模板中每个流水线包括两个逻辑级,第二逻辑级包括反相器以驱动输出道。因此,每个流水线块仅有一个有效的逻辑计算。相比之下,N-P模板具有N个任意级的实际逻辑计算。然而,为了便于解释以及将循环时间保持在18次转换内,我们使用具有四个逻辑级的N-P流水线。在重置状态,对流水线中的NMOS逻辑节点预充电,而对PMOS节点预放电。每个状态保持门包括串并转换器,其包括看门狗(keeper)和弱反馈反相器,以保证即使流水线停止在任意状态,充电也不会漂移。如图4所示,该串并转换器被表示为用于中间节点和最终输出节点的两个交叉耦接的反相器。当N选1编码的输入令牌到达时,通过下拉预充电节点而在第一级中计算逻辑。这与QDI模板中如何计算逻辑类似。我们将一个NMOS堆栈中的串联晶体管数量限制为总共四个。第二逻辑级通过上拉预放电节点来使用PMOS晶体管的堆栈计算逻辑。由于PMOS晶体管具有较慢的上升时间,因此出于吞吐量目的,我们将一个PMOS堆栈中的串联晶体管数量限制为总共三个(包括使能)。随着来自第二级的输出节点上拉,第三级中的下拉堆栈通过下拉它们的输出节点而被激活,并计算逻辑。最后,第四级通过使用其PMOS晶体管的上拉堆栈而计算逻辑。在我们的流水线中的四级级联的逻辑级类似于级联的多米诺逻辑,但是在动态逻辑级之间没有任何静态反相器。
对于到达的输入令牌或者所产生的任意中间输出,不存在显式的有效性检测门。AckPrevious(在本节后面介绍)表示进入流水线的输入令牌的有效性,并减少了显式检查有效性的需要。对于在模板内产生的中间输出,有效性被嵌入到上拉或下拉逻辑堆栈中,该上拉或下拉逻辑堆栈使用中间输出来计算下一级逻辑输出。取决于正在执行的功能,这可能会产生额外的成本。然而,对于本身就嵌入有输入有效性的逻辑堆栈(例如计算两个输入之和的堆栈),不存在有效性检测开销。消除用于输入令牌和中间输出节点的显式有效性检测门可以节省可观的功率,并且最小化握手开销。在第二级或第四级的最后,存在用于最终离开流水线的所有输出的显式完成检测逻辑。最终输出的完成检测自动地表示所有中间输出的有效性,以及所有进入N-P流水线的初始输入令牌的有效性。如图4所示,完成检测逻辑包括一组NOR门和c组件树(c-element tree)。每个c组件树包括并行的串并转换器。为了简明起见并没有示出这些串并转换器。使用c组件树来组合来自NOR门的输出,其中一旦所有的输出都有效,这些c组件树就使Ack信号失效。这导致放电信号变高,从而启动所有输入令牌的重置。放电信号仅被设置为短脉冲持续时间。失效的Ack信号还设置enP信号为高,这使得逻辑级二中的所有上拉节点放电。enN信号被设置为低,其对逻辑级一和三中的所有下拉节点预充电。因为没有检测内部节点的中性,所以我们对它们的转换引入了定时假设。具有短脉冲信号的输入令牌的放电引入了另一个定时假设。这两种定时假设需要以下约束:
-下拉节点必须在enN变高之前被完全预充电,上拉节点必须在enP变为低之前被完全放电。这转换为1个上拉/下拉转换相比9个门转换的竞争条件,当两个N-P流水线串联时,在enN和enP都翻转之前,最小转换计数。
-所有输入令牌必须在短脉冲放电周期内被完全放电。脉冲具有5个门转换的最小周期。有多少输入数据道就有多少NMOS放电转换。我们的流水线模板的稳健性不会受到影响,因为这些定时假设满足在任意两个相关路径延迟竞争之间至少5个门转换的最小定时限制。在已经确认了所有其他输出的有效性之前,任意输出的放电可以使得流水线永远停止。为了分析该影响,如图5所示,我们假设我们具有三个N-P流水线A、B和C。A产生两个输出,一个到B,另一个到C。B使用来自A的输出以计算它的输出。因为A已经计算了它的输出,因此现在它可以对它从A接收到的输入进行放电。如果A朝向C的另一输出还没有产生或还未经A的完成检测逻辑确认,那么B对它输入的放电将使得A的完成检测逻辑不稳定。为了防止这种情况出现,我们为我们的流水线模板增加了AckNext信号。这个信号将被发送到消耗来自当前N-P流水线输出的所有后继的流水线级。该信号在图4所示的目标流水线中被称为AckPrevious。它可以防止在已经确认发送方中所有输出的有效性之前对来自发送方级的令牌进行放电。如前所述,AckPrevious还表示进入到流水线中的输入令牌的有效性,因此减少了在NMOS下拉堆栈中检查输入令牌有效性的需求。在输入来自于不止一个流水线块的情况下,需要将来自所有对应流水线块的AckPrevious信号增加到完成检测逻辑,从而确保不会对输入数据道进行任何过早的放电。
为了确保这些教导的N-P流水线的循环时间,我们假设串联的两个N-P流水线随着时间(t)递增而发生逻辑转换。
-t=0时,输入令牌到达第一流水线块。
-t=4时,第一流水线块产生其输出。
-t=7时,使第一个块中的Ack信号失效,以表示所有输出信号的有效性。
-t=8时,第二流水线块产生其输出。
-t=9时,对第一流水线块中的输入令牌放电。对内部PMOS逻辑节点放电。
-t=10时,对第一流水线中的NMOS逻辑节点预充电。
-t=13时,通过第二流水线对来自第一流水线块的输出令牌放电。
-t=16时,使得第一个块中的Ack信号有效,以表示所有输出信号的重置。
-t=18时,设置enN,流水线准备好接收新的输入令牌。
因此,我们的N-P流水线具有18次转换的循环时间。停止在输入和输出处不会影响正确的操作。如果输入在不同的时间到达,那么模板在其当前状态等待。对于在不同时间计算的输出也是如此。相关的路径延迟假设具有根源(root)Ack,其仅在所有输入都已到达并且所有输出都已计算之后才发生改变。因此,正确操作不是信号到达时间的函数,这使得N-P模板非常稳健。
我们可以通过改变N-P流水线内的逻辑堆栈顺序来反相输入和输出的检测。在带有反相输入的情况下,第一级包括PMOS逻辑堆栈,而最终逻辑级包括NMOS逻辑堆栈,该NMOS逻辑堆栈包括以反相检测形式产生的输出。这可以提高输出信号的驱动强度,尤其在高扇出的情况下。
我们的第二流水线模板使用反相器代替级2中的PMOS上拉逻辑堆栈,因此其被称为N-反相器模板,如图6所示,其仅包括级4中的单个上拉PMOS晶体管。因为PMOS逻辑堆栈具有较慢的上升时间和相对较弱的驱动强度,因此N-P模板循环时间可能引起性能打击。N-反相器模板通过使用具有较快切换时间和强驱动强度的反相器来解决这个问题。这还得到了如第5部分中详细讨论的更好的噪声裕度。然而,这些提高的代价是降低逻辑密度,因为级2和级4不再执行任何有效的逻辑计算。除去这些变化,N-反相器和N-P模板使用几乎相同的定时假设。完成检测和握手电路也是相同的。
由于N-P和N-反相器流水线模板可以将重要逻辑打包在单个流水线块中,因此在流水线块具有非常多输出时这可能存在问题。为了检测这么多输出的有效性,我们可能需要通过如图7所示的一对额外的级来扩展c组件有效性树。由于在完成检测有效性树中多了这两个额外的级,因此N-P和N-反相器模板的循环时间不再是18次转换。多了四个额外的转换,其中两个用于输出信号的有效性检测,两个用于输出信号的中性检测,因此循环时间增加到了22次转换。因为我们的目标是保持循环时间在18次转换之内,因此我们开发了一些其他的完成检测电路[Schuster和Cook2003][Cheng1998]。为了将循环时间降回到18次转换,我们使用了基于[Cheng1998]中提出的完成检测电路的宽NOR门,但是还做出了一些优化以使得该电路适用于我们的流水线模板。如图8所示,这些优化包括仅使用去往相同的后续流水线块的输出集合中的一个输出,以用于中性检测,以及在DONE和RST电路的上拉堆栈中增加enP和enN晶体管。在本节的最后部分将详细叙述这些优化及其益处。
之前是使用静态NOR门来生成Ack信号。通过设置Done,输出的有效性被信号化。为了确保仅在一旦所有Ack信号变低的时候设置Done信号,当仅有一个下拉晶体管导通时,Done电路的上拉路径阻抗被设置为至少四倍于下拉路径阻抗。为了防止VDD和GND之间的直接通路,来自最近(最慢)输出中的一个的Ack被用于上拉堆栈。RST信号被用于感测所有输出的重置。多个R.t和R.f信号对应于所产生的实际双道输出。将要被重置的最近(最慢)的信号被放置到上拉堆栈中。RST电路中的上拉路径阻抗被设置为确保一旦关闭了RST电路中的所有下拉晶体管,也就是重置了所有输出信号,该上拉路径阻抗仅会变高。RST电路具有两个下拉晶体管,其用于每个双道输出,以及四个用于4选1输出的四个下拉晶体管。随着输出数量的增加,RST上升时间明显被影响。我们对流水线模板进行了仔细检查,这使得我们意识到对于去往相同流水线块的输出,我们仅需要检查这些输出中的一个、而非所有的重置,这是因为它们都使用了相同的放电脉冲。我们假设双道输出R0-R3都是去往相同的流水线块。我们通过仅使用相应于R0输出的下拉晶体管来使得RST电路最小化。如图8所示,对应于R1、R2和R3双道输出的晶体管被取消了。
在DONE和RST电路的上拉堆栈中增加enP和enN晶体管是我们引入的另一种优化。在该流水线还在等待输出被重置时,enP信号切断在DONE电路中的上拉通道。这防止了在Ackslow之外的任何其他Ack首先变高的情况下在VDD和GND之间出现直接通路。同样的,在RST的上拉堆栈中引入enN切断了评估阶段VDD和GND之间的直接通路。
异步处理模板的以上例子提供了用于多种异步处理操作方法的结构。例如,异步处理的一个例子可被实现为包括:串联多个异步电路以形成异步处理流水线以允许一个异步电路与下一个相邻的异步电路进行通信,从而在每个异步电路执行信号处理的同时,无需公共时钟也可进行通信。该方法进一步包括通过引导来自两个相邻连接的异步电路中的相对于另一异步电路更上游的一个异步电路的信号,来操作异步处理流水线中的两个相邻连接的异步电路进行通信,并且不需要从下游异步电路到上游异步电路的确认反馈;通过使用多个导线来传送输入或输出信号,以及通过每次仅使多个导线中的单个线有效来操作每个异步电路以编码输入或输出信号;和操作每个异步电路以使用单个导线来发送确认信号到下游异步电路。该单个导线是用于传送从上游异步电路到下游异步电路的输出信号的导线之外的导线。
基于以上示例性设计,在每个节点具有估计导线负载的情况下进行了SPICE级仿真,以量化两种完成检测方案之间的权衡。在这些仿真中,假设每个输出去往单独的流水线块,因此,可以检查每个信号的放电。如图9所示,相对于多级c组件树检测完成方案,宽NOR完成检测电路在较宽输出范围内得到较小的延迟。延迟差异随着输出数量的增加而增加,这是因为c组件完成可能需要多个额外的级。对于15个输出信号,宽NOR完成得到少了30%的延迟。
如图10所示,在能耗方面,完成检测方案的选择不仅取决于输出的数量,还取决于到达顺序和所选择的最新信号的延迟。X轴对应于所选择的最新信号的到达顺序。例如,对应于到达顺序为9的数据点表示我们所选择的最新输出是要被设置或重置的第九个输出。所有的剩余信号在任意2-FO4延迟后到达。这对应于用于基于宽NOR的完成检测方案的VDD和GND之间的直接通路的周期。不管到达顺序如何,基于c组件的完成方案消耗相同的能量。当输出数量为9或更少时,则更加节能。然而,某些N-P和N-反相器流水线模板可能需要更多数量的输出,基于宽NOR的完成检测方案消耗明显更少的能量。图10中另一个值得观察的地方在于仅当最新信号是最后几个信号中的一个时,到达顺序对于能耗的影响才是严重的。
当所选择的最新信号不是最后一个时,VDD和GND之间直接通路的周期的长度可能导致基于宽NOR的完成检测方案的显著能耗。为了探索这种效果,如图11和图12所示,我们通过改变晚到达的信号的延迟来模拟用于12和15个输出的宽NOR完成电路。这些图表还包括相应的基于c组件树的完成检测方案的结果。对于12个输出,除非任何输出是在所选择的最新信号之后3个或更多FO4延迟后到达,宽NOR完成相比于基于c组件的完成方案消耗更少的能量,不管最新信号的到达顺序如何。对于15个输出,裕度增加到5个或更多个F04门延迟,宽NOR完成相比于相应的基于c组件的完成检测方案消耗更多的能量。
如图13所示,在晶体管区域方面,随着输出数量的增加,宽NOR完成检测电路变得更加高效。因此选择具体的完成检测电路是一种设计选择,其取决于多个因素:流水线级的输出数量,延迟和吞吐量目标,功率预算,面积约束,以及所选择的最新输出的延迟可变性。
吞吐量、能量和面积是电路设计者的关键设计考量。如图14所示,我们选择8选1多路选择器设计,其产生输出的多个复制,以突出我们的模板中的一些权衡。实现了所选择电路的PCeHB、N-P和N-反相器流水线版本。在每个节点带有估计的导线负载的情况下,进行了基于65纳米体硅CMOS工艺的最高精度SPICE仿真。
尽管所有这三个模板都具有18次转换的循环时间,但是N-P实现方式导致吞吐量降低8.5%。N-P实现方式较慢,这是因为其在PMOS堆栈中应用了一些逻辑计算,而PMOS堆栈具有比NMOS堆栈慢的电压转换率以及较弱的驱动强度。在PCeHB实现方式中,每个2选1多路选择器代表一个单独的流水线级,每个级引起了显著的握手开销(如之前表格1所示)。还有用于复制逻辑的单独的流水线块。反之,在N-P和N-反相器实现方式中,包括复制逻辑的完整的8选1多路选择器电路可被分别完全地打包到一个或两个流水线块中。该逻辑对能效和总晶体管宽度的影响相当深远。我们的N-反相器实现方式,操作于与PCeHB设计相同的吞吐量下,每次操作消耗的能量减少52.6%,同时使用的晶体管宽度少了48%。在使用N-P流水线的情况下,尽管只有8.5%的吞吐量损失,但是能量和晶体管宽度分别节省超过71.2%和65%。
这些教导的N-P和N-反相器模板使得我们可以在单个流水线级内打包更多逻辑计算,同时维持非常高的吞吐量。这种灵活性是标准PCeHB设计所不具备的,标准PCeHB由多个流水线级组成,在单个级中仅有一个有效逻辑计算。如图16所示,在我们的模板中,每个单级具有更多逻辑创造了每个流水线具有大量输出的可能性,这可能不利于整体吞吐量。绝对吞吐量对输出数量的依赖性凸显一个重要的设计权衡。对于更多输出的情况,尽管转换的数量保持与宽NOR完成检测逻辑所使用的数量相同,但是这些转换的每一个都引起更高的延迟,如图9之前所示的。如果使用了基于c组件的完成逻辑这将更加糟糕,因为其将给每个循环带来4次额外的转换。
当涉及到使用动态门时,噪声馈通是主要关注的问题之一。由于我们的流水线模板使用级联的动态门用于逻辑计算,因此我们执行电路的综合噪声裕度分析。使用具有最高精度SPICE配置的65nm体硅CMOS技术在1V额定VDD和85摄氏度操作环境下在所有工艺范围:典型-典型(TT)、慢-快(SF)、快-慢(FS)、慢-慢(SS)和快-快(FF)上对每个流水线模板的动态门进行了仿真。由于SPICE仿真不考虑导线电容,因此我们在用于电路每个门的SPICE文件中加入额外的导线负载。对于每个流水线模板,选择所有工艺范围中噪声裕度的最低值。对于N-P模板的噪声馈通分析,我们分析了全加器NMOS逻辑堆栈,该全加器NMOS逻辑堆栈后接着一个PMOS上拉堆栈中的两输入AND门。如[Weste和Harris2004]中所定义的级联N-P结构的噪声裕度是指,单位增益点处多个输入中的一个输入上的、被NMOS逻辑堆栈识别的低输入电压最小值与驱动PMOS上拉堆栈的低输出电压最大值之间的幅度差。对于N-反相器和PCeHB模板,我们分析了全加器NMOS逻辑堆栈,该全加器NMOS逻辑堆栈后接着一个静态CMOS反相器,其噪声裕度被定义为在多个输入中的一个输入上的NMOS逻辑堆栈所识别的低输入电压最小值与驱动输出反相器的低输出电压最大值之间的幅度差。结果如图17所示,图17还表示了两输入静态CMOS NOR门的噪声裕度以用于比较。
N-P模板具有最低的噪声抑制能力。然而,可以通过增加串并转换器给动态逻辑堆栈的相关驱动强度来显著提高噪声裕度。但是这样的提高是以牺牲吞吐量和略微增加每次操作的能量为代价的(分别如图18和19所示)。每次操作的能量的结果被归一化到串并转换器强度为0.1的每次操作的PCeHB实现能量。从这些结果可以看出,对用于串并转换器的确切强度值的选择表示电路应用的设计权衡。
N-P和N-反相器流水线模板包括多种定时假设,违反这些定时假设可能影响正确操作或使流水线停止。在第4节中,我们讨论了确保正确性所必须的定时裕度,但是这些定时裕度是依据门转换而给出的。为了确保我们的模板有足够的稳健性,我们使用具有最高精度SPICE配置的65nm体硅CMOS技术在1V额定VDD和85摄氏度操作环境下分析我们的流水线的全晶体管级实现方式的确切定时约束,并且估计每个门的导线负载。用于对内部节点进行预充电和放电的9个门转换的定时约束针对N-P和N-反相器流水线分别转换为14.8FO4和12.2FO4延迟,相反地,相应于内部节点的预充电或放电的最坏情况转换不超过2.67FO4延迟。这将带来非常安全的定时裕度,其对于N-P和N-反相器流水线分别超过12FO4和9.5FO4延迟。
N-P和N-反相器流水线中的第二定时假设是关于在短脉冲放电周期内所有输入令牌的完全放电。5次转换放电脉冲对于N-P和N-反相器模板均转换为5FO4延迟。放电脉冲定时裕度是输入负载的函数,而输入负载又是输入门和导线电容的函数。由于我们设想我们的模板是用于大块的本地计算而并非用于全局通信,因此我们发现短脉冲周期足以用于完全输入令牌放电,包括对每个节点增加的导线电容的放电,这相应于12.5m导线长度。在最坏的情况下,输入令牌花费不超过2.5FO4延迟来完全放电,这将产生2.5F04的定时裕度。由于对于前向延迟和吞吐量,放电脉冲周期均不在流水线关键路径上,因此可以通过向脉冲生成器反相器链增加两个额外的反相器来提高定时裕度,而不会影响性能。在使用这两个额外的反相器的情况下,定时安全缓冲从2.5FO4增加到4.5FO4,这使得模板更加稳健。
高性能乘法器电路是现代微处理器[Schmookler等1999][Trong等2007]和数字信号处理器[Tian等2002]的重要组成部分。为了获得高吞吐量和低延迟,大多数高性能芯片使用多种形式的布斯编码阵列乘法硬件[Booth1951]。阵列乘法器架构需要大量同时传送(in flight)的令牌。每个乘法操作产生一定数量的部分积,这部分积接着被加到一起以产生最终积。根据其对于较宽应用范围的有用性以及可观的电路复杂度,高吞吐量阵列乘法器是有效地突出PCeHB和我们的流水线模板之间权衡的合适候选。在这个案例研究中,我们着眼于通过将大量逻辑打包在每个流水线级内来提高能效,即使代价是相比于PCeHB类型流水线有高达25%的吞吐量下降。我们使用PCeHB流水线作为我们的基线,实现了8x8位基4(radix-4)布斯编码阵列乘法器(晶体管级)。图20表示我们的8×8位乘法器的顶层规格(top-level specification)。图20的顶部表示用于阵列乘法器的部分积生成。每一个Y输入都是基4格式。被乘数位被用来生成用于每个部分积行的布斯控制信号。由于PCeHB流水线仅可计算少量逻辑,因此标记为PP的每个矩形框表示单独的流水线级。布斯控制信号和乘法器输入位被从一个流水线级发送到另一个,同时每个流水线级产生两位部分积。图20的下半部分表示生成并累加部分积的顺序。水平虚线分隔开不同的时间段。每个虚线多边形代表单独的PCeHB流水线级。每个多边形内的项(entries)表示将被加在一起以产生和的多个输入,以及用于下一个流水线级的进位输出。PP表示两位部分积项,C’相应于用于每个部分积行的符号位,SS表示来自上一级的两位和输出,C表示来自上一级求和计算的单位进位输出。最终积位以位倾斜方式(bit-skewed fashion)生成,其由符号RR表示。因此,我们需要在输出以及一些输入上增加松弛匹配缓冲(slack-matching buffer)以优化乘法器吞吐量[Cummings等1994]。为了简明起见,在图20中我们并未示出这些松弛匹配缓冲。我们的基线乘法器是典型的流水线,但是每个流水线级中仅包括非常少量的逻辑。虽然这有助于实现每周期18次转换的极高吞吐量,但是每个流水线级具有大的握手开销。
为了量化我们的低握手流水线模板的能效和其他特点,我们使用N-P和N-反相器流水线模板实现了类似的全晶体管级8×8位基4布斯编码阵列乘法器。图21表示用于8×8位阵列乘法器的N-P流水线以及它们的逻辑堆栈的概览。这两个N-P流水线都具有四级逻辑。第一流水线的第一级生成所有部分积项。因为仅需要生成一次布斯控制信号和乘法器输入,而非如PCeHB实现那样为每个单独的流水线块生成布斯控制信号和乘法器输入,因此这明显是巨大的功率节省。每个虚线多边形表示代表一个逻辑堆栈而非单独的流水线级,这导致每个流水线块具有非常高的逻辑密度。每个RR、SS和C信号代表单个输出通道,其转换成用于第一N-P流水线块的14个输出和用于第二N-P流水线块的4个输出。受限于空间未示出的N-反相器流水线实现方式需要两倍于N-P实现方式的流水线级,这是因为在其PMOS上拉堆栈中没有执行有效的逻辑计算。然而,该设计的其余部分类似于每个流水线级内具有大量逻辑的N-P流水线实现方式。
与PCeHB实现方式中具有大量细粒度流水线块不同,我们仅需要两个N-P和四个N-反相器流水线来实现批量8×8位乘法逻辑。用于N-P和N-反相器这两种实现方式的第一流水线的输入是四个基4乘法器位项,以及用于所有行的布斯控制信号,该布斯控制信号是使用PCeHB类型流水线分别生成的。由于PCeHB流水线遵循四相握手协议,因此我们在单道转换模板中使用类似于[FerrettiBeerel2002]提出的四相,但是做了少量修改。因为空间限制,我们不讨论这些变换模板。对于具有超过九个输出的流水线块,我们使用宽NOR完成检测方案。对于去往相同流水线块的多个输出,我们仅跟踪去往第二流水线多个输出中的一个的中性。该优化极大地降低RST电路的复杂度,降低了功率消耗,还为我们的流水线模板增加了高达6.3%的吞吐量。为了突出任意四相握手环境下的N-P和N-反相器流水线的无缝集成,我们将所得到的的积输出变换为四相4选1编码。
使用标准晶体管定尺寸技术[Weste和Harris2004]来为我们的基线PCeHB乘法器实现方式和我们的NP及N-反相器流水线实现方式中的晶体管定尺寸。慢速且耗电的状态保持完成组件被限制为一次最多三个输入。针对每个状态保持门,增加了看门狗和弱反馈反相器以确保即使流水线停止在任意状态充电也不会偏移。由于HSIM/HSPICE仿真不考虑导线电容,因此我们在用于电路中每个门的SPICE文件中增加了额外的导线负载。基于制造芯片和布图后仿真的先前经验,我们发现我们的导线负载估计是保守的,并且预测的能量和延迟量一般比布图后仿真高出10%。我们的仿真针对典型-典型角(TT)使用65nm体硅CMOS工艺。测试向量被加载到使用组合VCS/HISM仿真的SPICE仿真中,该仿真使用Verilog模型实现在测试环境中的异步握手。以最高精度设置来执行所有仿真。图22表示我们的流水线模板的功耗细目分类。不同于在握手开销上消耗了超过69%功率的PCeHB流水线,在我们的流水线中握手和完成检测逻辑仅占用总功率的26%。握手相关开销降低的主要原因是在每个流水线中消除了针对大量中间节点的有效性和中性检测逻辑。为了完全量化和估计我们的流水线模板,我们跨越大范围电压来仿真所有的三种8×8位阵列乘法器实现方式。本节中所呈现的所有实验结果包括转换模板的明显开销。这些模板将输入令牌从四相协议转换为单道协议,并将输出由单道协议转换回四相协议。
图23中,所有这三个流水线实现方式的吞吐量和能耗对应于间隔为0.1V的0.6V到1.1V的数据点(从左到右)。如前所述,N-反相器和N-P实现方式是从能效角度设计的,同时相比于PCeHB设计,允许多至25%的吞吐量减少。为了最小化握手电路,每个N-反相器和N-P流水线块打包可观的逻辑计算,并产生大量的输出,这降低了整体吞吐量。因此,在吞吐量方面,PCeHB流水线实现方式在所有电压上都获得最佳结果。但是该性能提升的代价是,相比于N-反相器和N-P流水线实现方式,其每次操作分别增加了45.4%和59.5%的能量。图23中的另一个重要发现时:对于任意单个吞吐量目标,无论是诸如400-500MHz的低吞吐量范围,还是诸如1.3-1.5GHz的高吞吐量范围,我们的模板每次操作消耗的能量远少于PCeHB实现方式。
我们的流水线可以工作于较宽的电压范围而无需晶体管重定尺寸,这样的事实凸显了我们模板的稳健性。实验数据包括,在模板中消耗的、将输入由四相协议转换为单道协议并将输出由单道协议转换回四相协议所需要消耗的功率。可以节约能量主要是因为:
-握手电路被大量减少,这是因为消除了用于所有中间节点的有效性和中性检测门。
-相同流水线块内的输入和中间输出的共享。在PCeHB实现方式中,输入和输出被从一个级复制到另一个级,并且需经每个流水线块内单独的有效性和中性检查。
-使用了更节能的完成检测方案。为了综合考虑性能和能耗,我们使用两个指标:如图24所示的能量-延迟乘积以及能量延迟平方的乘积。结果被归一化到PCeHB实现方式中。N-反相器和N-P流水线将能量延迟乘积分别降低了38.5%和44%。对于能量延迟平方的乘积,相比于PCeHB实现方式,N-反相器实现方式降低了30.3%,而N-P流水线降低了22.2%。
如表格II所示,N-反相器和N-P实现方式将总体乘法器延迟分别降低了20.2%和18.7%。这两个流水线模板可以将大量逻辑打包在单个流水线块,这减少了所需的流水线级的总数,并且因此导致延迟降低。虽然N-反相器实现方式需要的流水线级是N-P实现方式的两倍,但是其还是能导致1.85%的总体延迟降低。这可以归因于在N-P模板中使用较慢的上拉逻辑堆栈。
表格II:8x8位阵列乘法器延迟
如表格III所示,在晶体管总的数量方面,N-反相器和N-P实现方式比PCeHB实现方式使用的晶体管分别减少42.2%和54.2%。N-反相器和N-P设计的总晶体管宽度比PCeHB实现方式分别减少35.6%和46%。晶体管数量和宽度极大的节省可直接归因于在单个流水线块中打包了大量逻辑,以及取消了用于所有中间节点的握手逻辑。
表格III:8x8位阵列乘法器晶体管数量和宽度
对特定流水线实现方式的选择代表一种设计权衡。在选择特定流水线实现方式之前,可能会同时考虑诸如吞吐量、逻辑复杂度、功率预算、延迟范围、总晶体管数量、噪声裕度和定时稳健性等关键因素。N-P和N-反相器模板代表了对QDI模板的良好节能替代,尤其是对于需要大量输入或输出或者具有多个中间逻辑级的逻辑计算而言。我们设想这些电路将被用于由QDI接口包围着的大块的本地逻辑(例如在浮点单元中的阵列乘法器)而不是全局逻辑。
以上的例子包括用于高吞吐量异步电路的两种具体节能流水线模板。这两个模板是基于单轨握手协议的N-P和N-反相器流水线。每个流水线包括多个逻辑级。通过消除用于所有输入令牌和用于所有中间逻辑节点的有效性和中性检测逻辑门,握手开销被最小化。这两个模板可将大量逻辑打包在每个流水线块中,同时还能保持仅18次转换的快速循环时间。输入和输出的停止不会影响正确操作。在我们的模板内的动态门的综合噪声分析显示在所有工艺范围上都有足够的噪声裕度。由于我们的模板引入了多种定时假设,因此我们还分析了流水线的定时稳健度。呈现了一种基于宽NOR门的完成检测方案,能够获得充分的延迟和功率节约,尤其是在输出数量增加的情况下。呈现了8x8位布斯编码阵列乘法器的三种全晶体管级流水线实现方式。相比于PCeHB实现方式,N-反相器和N-P流水线实现方式将能量延迟乘积分别降低了38.5%和44%。对于N-反相器和N-P流水线模板,总体乘法器延迟分别降低了20.2%和18.7%,同时总晶体管宽度降低了35.6%和46%。
以下公开文献提供了所描述的技术的额外技术信息,出于各种目的,将这些文献通过引用方式全部并入本申请:
BEEREL,P.,LINES,A.,和DAVIES,M.2009.多级多米诺异步流水线的逻辑合成。支点微系统(Fulcrum Microsystems),US7584449B2,2009年。
BOOTH,A.D.1951.带符号的二进制乘法技术,力学与应用数学季刊,4,2,236-240。
CHENG,F.C.1998.完成检测电路的实际设计和性能估计。关于计算机设计的国际会议论文集,1998年。
CUMMINGS,U.V.,LINES,A.M.,和MARTIN,A.J.1994.异步流水线晶格结构滤波器。关于异步电路和系统的先进研究的国际研讨会论文集,1994年。
D.FANG,J.T.和MANOHAR,R.2005.高性能异步FPGA:测试结果。关于现场可编程自定义计算机的IEEE研讨会论文集,2005年4月。
DALLY,W.J.和POULTON,J.1998.数字系统引擎。剑桥大学出版社,剑桥,UK。
FANG,D.和MANOHAR,R.2004.非均匀接入异步寄存器文件。关于异步电路和系统的IEEE国际研讨会论文集,2004年。
FERRETTI,M.和BEEREL,P.2002.使用1/n编码的单通道异步流水线模板。关于设计、自动化和测试(DATE)的欧洲会议的论文集,2002年。
HOROWITZ,M.2007.CMOS的尺寸变化、功率和未来。关于VLSI设计的第20界国际会议的论文集,2007年。
LAFRIEDA,C.和MANOHAR,R.2009.使用宽松的准延迟不敏感电路降低功率消耗。关于异步电路和系统的IEEE国际研讨会的论文集,2009年。
LINES,A.1995.流水式异步电路。硕士论文,加州理工大学。
MARTIN,A.J.1990.在VLSI中编程:从通信处理到延迟不敏感电路。艾迪生维斯理(Addison-Wesley)出版社。
MARTIN,A.J.,LINES,A.,MANOHAR,R.,NYSTROM,M.,PENZES,P.,SOUTHWORTH,R.,CUMMINGS,U.V.,和LEE,T.-K.1997.异步MIPS R3000的设计。关于VLSI先进研究的会议的论文集,1997年。
SCHMOOKLER,M.,PUTRINO,M.,MATHER,A.,TYLER,J.,NGUYEN,H,ROTH,C.,PHAM,M.,LENT,J.,和SHARMA,M.1999.一种PowerPC微处理器向量扩展的低功率、高速度实现方式。关于计算机架构的国际研讨会的论文集,1999年。
SCHUSTER,S.AND COOK,P.2003.操作与3.3-4.5GHz的低功率同步至异步互锁流水线CMOS电路。固态电路IEEE期刊38,4,622-630。
SEITZ,C.L.1980.对VLSI系统的介绍。C.A.Mead and L. A.Conway编,艾迪生维斯理出版社。
SHEIKH,B.R.AND MANOHAR,R.2010.操作优化的异步IEEE754双精度浮点加法器。关于异步电路和系统的IEEE国际研讨会论文集,2010年。
SUTHERLAND,I.和FAIRBANKS,S.2001.Gasp:最小FIFO控制。关于异步电路和系统的IEEE国际研讨会论文集,2001年。
TIAN,Z.,YU,D.,和QIU,Y.2002.在DPS应用中的32位乘法器的高效算法和MAC指令以及具有32x8乘法器-累加器的VLSI实现方式。关于信号处理的国际会议论文集,2002年。
TRONG,S.D.,SCHMOOKLER,M.,SCHWARZ,E.M.,和KROENER,M.2007.P6二进制浮点单元。关于计算机架构的国际研讨会论文集,2007年。
VAN BERKEL,K.AND BINK,A.1996.应用到微流水线的单轨握手信令和握手电路。关于异步电路和系统的国际研讨会论文集,1996年。
WESTE,N.和HARRIS,D.2004.CMOS VLSI设计:电路和系统方面。Addison-Wesley出版社。
WILLIAMS,T.E.1991.自定时环以及除法的应用。博士论文,计算机系统实验室,斯坦福大学。
虽然该专利文献包含了很多细节,但是这些不应被理解为对任一发明或者其要求的权利的范围的限制,而应当作为特定于特定发明的特定实施例的特征描述。还可以以组合或在单个实施例中的方式来实现本专利文献中在单独实施例的上下文中描述的特定特征。相反的,还可以单独在多个实施例或在任意核实的子组合中实现在单个实施例的上下文中描述的多种特征。此外,尽管一些特征可能在以上被描述为特定的组合,或者一开始就要求为诸如来自所要求的组合的一个或多个特征,在一些情况下,可从该组合中分离出去,并且所要求的组合可以针对子组合或子组合的变化。
类似的,虽然在附图中按照特定顺序描述了多种操作,但是这不应当被理解为需要以所示的特定顺序或者以连续顺序来执行这些操作,或者需要执行所示的所有操作以获得期望的结果。此外,在本专利文献中描述的实施例中的多种系统组件的分离不应当被理解为所有实施例中都需要这样的分离。
本申请仅描述了少数实现方式和例子,可以基于在本专利文献中所描述的和所表示的内容来实现其他实现方式、改进和变化。
用于高性能异步电路的节能流水线电路模板专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。








动态评分
0.0