





专利摘要
本发明公开了一种基于多核转发的负载均衡方法、装置及虚拟交换机,属于网络技术领域。方法包括:对于多个CPU中的每一个CPU,竞争多个接收端口的收包权限;在竞争到任一接收端口的收包权限后,通过任一接收端口接收第一数据包;竞争与第二数据包匹配的目的发送端口的发包权限;在竞争到目的发送端口的发包权限后,通过目的发送端口发送第二数据包。由于端口与CPU之间不进行绑定,而是CPU公平竞争各个端口的收包权限和发包权限,在竞争到收包权限或发包权限后进行数据的收发,因此不会出现多个大流量的Port绑定至同一个CPU的情况,确保了CPU之间的负载均衡,且突破单个Port的处理能力受单个CPU处理能力的限制,大大降低了时延增加甚至丢包等情况的出现。
权利要求
1.一种基于多核转发的负载均衡方法,应用于虚拟交换机,所述虚拟交换机包括多个中央处理器CPU、多个接收端口和多个发送端口,其特征在于,所述方法包括:
对于多个CPU中的任一个CPU,竞争多个接收端口的收包权限,所述收包权限指代接收数据包的权限;
在竞争到任一接收端口的收包权限后,通过所述任一接收端口接收第一数据包;
竞争与第二数据包匹配的目的发送端口的发包权限,所述第二数据包指代已经过所述任一个CPU处理完成的数据包,所述发包权限指代发送数据包的权限;
在竞争到所述目的发送端口的发包权限后,通过所述目的发送端口发送所述第二数据包。
2.根据权利要求1所述的方法,其特征在于,所述方法还包括:
在所述第一数据包接收完毕后,释放所述任一接收端口的收包权限;
在通过所述目的发送端口发送所述第二数据包后,释放所述目的发送端口的发包权限。
3.根据权利要求1所述的方法,其特征在于,所述通过所述任一接收端口接收第一数据包之后,所述方法还包括:
将所述第一数据包放入所述任一接收端口的保序队列中,所述保序队列中存储了不同CPU从所述任一接收端口接收到的数据包。
4.根据权利要求3所述的方法,其特征在于,所述竞争与第二数据包匹配的目的发送端口的发包权限,包括:
判断所述保序队列中可发送数据包的序列号是否与所述第二数据包中起始数据包的序列号一致,所述起始数据包指代在所述第二数据包中最先通过所述任一接收端口接收到的子数据包;
若所述保序队列中可发送数据包的序列号与所述第二数据包中起始数据包的序列号一致,则竞争所述目的发送端口的发包权限;
其中,每一个数据包的序列号由对其进行处理的CPU分配,并存储在与接收所述数据包的接收端口匹配的保序队列中。
5.根据权利要求3所述的方法,其特征在于,所述方法还包括:
在所述第一数据包接收完毕后,释放所述任一接收端口的收包权限;
在释放对所述任一接收端口的收包权限之后,所述方法还包括:
将所述保序队列中已经过所述任一个CPU处理完成的所述第二数据包放入对应的端口发送序列中。
6.根据权利要求5所述的方法,其特征在于,所述将所述保序队列中已经过所述任一个CPU处理完成的所述第二数据包放入对应的端口发送序列中,包括:
将已经过所述任一个CPU处理完成的数据包从所述保序队列中移出,并将所述数据包存储在中转缓存中;
在所述保序队列中需经所述任一个CPU处理的数据包均处理完成后,按照先进先出规则,依次将存储在所述中转缓存中的数据包放入所述端口发送序列中。
7.根据权利要求1所述的方法,其特征在于,所述方法还包括:
若未竞争到所述目的发送端口的发包权限,则至少记录所述第二数据包中每一个数据包的发送端口、包类型和包状态。
8.一种基于多核转发的负载均衡装置,其特征在于,所述装置包括:
第一竞争模块,用于对于多个CPU中的任一个CPU,竞争多个接收端口的收包权限,所述收包权限指代接收数据包的权限;
接收模块,用于在竞争到任一接收端口的收包权限后,通过所述任一接收端口接收第一数据包;
第二竞争模块,用于竞争与第二数据包匹配的目的发送端口的发包权限,所述第二数据包指代已经过所述任一个CPU处理完成的数据包,所述发包权限指代发送数据包的权限;
发送模块,用于在竞争到所述目的发送端口的发包权限后,通过所述目的发送端口发送所述第二数据包。
9.根据权利要求8所述的装置,其特征在于,所述装置还包括:
释放模块,用于在所述第一数据包接收完毕后,释放所述任一接收端口的收包权限;在通过所述目的发送端口发送所述第二数据包后,释放所述目的发送端口的发包权限。
10.根据权利要求8所述的装置,其特征在于,所述装置还包括:
处理模块,用于将所述第一数据包放入所述任一接收端口的保序队列中,所述保序队列中存储了不同CPU从所述任一接收端口接收到的数据包。
11.根据权利要求10所述的装置,其特征在于,所述第二竞争模块,用于判断所述保序队列中可发送数据包的序列号是否与所述第二数据包中起始数据包的序列号一致,所述起始数据包指代在所述第二数据包中最先通过所述任一接收端口接收到的子数据包;若所述保序队列中可发送数据包的序列号与所述第二数据包中起始数据包的序列号一致,则竞争所述目的发送端口的发包权限;
其中,每一个数据包的序列号由对其进行处理的CPU分配,并存储在与接收所述数据包的接收端口匹配的保序队列中。
12.根据权利要求10所述的装置,其特征在于,所述处理模块,还用于将所述保序队列中已经过所述任一个CPU处理完成的所述第二数据包放入对应的端口发送序列中。
13.根据权利要求12所述的装置,其特征在于,所述处理模块,用于将已经过所述任一个CPU处理完成的数据包从所述保序队列中移出,并将所述数据包存储在中转缓存中;在所述保序队列中需经所述任一个CPU处理的数据包均处理完成后,按照先进先出规则,依次将存储在所述中转缓存中的数据包放入所述端口发送序列中。
14.根据权利要求8所述的装置,其特征在于,所述装置还包括:
记录模块,用于若未竞争到所述目的发送端口的发包权限,则至少记录所述第二数据包中每一个数据包的发送端口、包类型和包状态。
15.一种虚拟交换机,所述虚拟交换机包括多个中央处理器CPU、多个接收端口、多个发送端口和存储器,所述存储器与所述处理器连接,所述存储器存储有程序代码,所述多个CPU用于调用所述程序代码,执行以下操作:
对于多个CPU中的任一个CPU,竞争多个接收端口的收包权限,所述收包权限指代接收数据包的权限;在竞争到任一接收端口的收包权限后,通过所述任一接收端口接收第一数据包;竞争与第二数据包匹配的目的发送端口的发包权限,所述第二数据包指代已经过所述任一个CPU处理完成的数据包,所述发包权限指代发送数据包的权限;在竞争到所述目的发送端口的发包权限后,通过所述目的发送端口发送所述第二数据包。
说明书
技术领域
本发明涉及网络技术领域,特别涉及一种基于多核转发的负载均衡方法、装置及虚拟交换机。
背景技术
对于移动运营商来说,为了向用户提供更好的网络服务,逐步实行了网络功能虚拟化。这样诸如防火墙、流量计费、路由服务等网络吞吐量较大的服务会迁移到虚拟机(英文:Virtual Machine;简称:VM)中运行,以取代通信网中的私有专用网元设备。由于上述服务的网络吞吐量较大,因此引入了虚拟交换机(英文:Virtual-Switch;简称:vSwitch)来提升VM的流量处理能力。
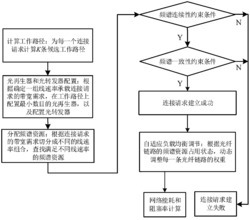
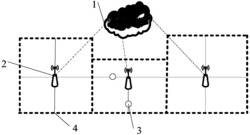
目前业界通常采用在非特权状态下进行网络流量转发的vSwitch方案。由于vSwitch负责网络流量转发,而时下随着用户业务的蓬勃发展,转发的网络流量呈大幅攀升趋势,因此使用单个中央处理器(英文:Central Processing Unit;简称:CPU)时会存在瓶颈,所以需要引入多个CPU,即通过多核并行处理来提高转发性能。参见图1,由于vSwitch使用了多核机制,因此会同时使用多个CPU进行流量转发处理。此时每个VM的端口(Port)和物理网卡的级联端口(uplink port)交给多个CPU处理。
关于一个CPU需要处理哪些Port上的流量,即如何进行多个CPU之间的负载均衡,详见图2。在图2中,P0-Pn表示不同Port,T0-Tm表示多个CPU。在进行负载均衡时,预先配置各个Port与CPU之间的绑定关系。即,首先提前对各个VM的流量状态进行评估,结合每个CPU的处理能力和每个port的流量需求,将有大流量需求的Port尽量平均分布在各个CPU上。在创建vSwitch时,在配置文件或命令行中指定多核转发所使用的CPU范围。例如,0xf表示CPU0~CPU3用于转发。在添加Port时,通过配置文件或命令行指定当前Port使用哪个CPU进行处理。例如,config(P1,CPU2)表示Port1的流量在CPU 2上进行处理,其中P1为Port1的缩写。
在实现本发明的过程中,发明人发现现有技术至少存在以下问题:
由于提前预测各个VM的流量很困难,因此采取将Port与CPU预先进行绑定的方式,很可能会出现多个大流量的Port绑定至同一个CPU的情况。这会导致CPU之间的负载不均,进而导致流量转发的时延增加甚至出现丢包的情况。此外,由于一个Port仅能被一个CPU独占处理,因此单个Port的处理能力存在瓶颈,其处理能力受与其绑定CPU的处理能力的限制。
发明内容
为了解决现有技术的问题,本发明实施例提供了一种基于多核转发的负载均衡方法、装置及虚拟交换机。所述技术方案如下:
第一方面,提供了一种基于多核转发的负载均衡方法,应用于虚拟交换机,所述虚拟交换机包括多个CPU、多个接收端口和多个发送端口,所述方法包括:
对于多个CPU中的每一个CPU,竞争多个接收端口的收包权限,所述收包权限指代接收数据包的权限;
在竞争到任一接收端口的收包权限后,通过所述任一接收端口接收第一数据包;
竞争与第二数据包匹配的目的发送端口的发包权限,所述第二数据包指代已经过所述CPU处理完成的数据包,所述发包权限指代发送数据包的权限;
在竞争到所述目的发送端口的发包权限后,通过所述目的发送端口发送所述第二数据包。
需要说明的是,本发明中端口与CPU之间不设定绑定关系,而是CPU公平竞争端口;竞争到收包或发包权限的CPU进行收包操作或发包操作。
在第一方面的第一种可能的实现方式中,所述方法还包括:
在所述第一数据包接收完毕后,释放所述任一接收端口的收包权限;
在通过所述目的发送端口发送所述第二数据包后,释放所述目的发送端口的发包权限。
竞争到收包或发包权限的CPU在本次操作完成后,需要立即释放收包权限或发包权限。其中,所述收包权限指代接收数据包的权限;所述发包权限指代发送数据包的权限。同时,将转发处理流程拆分为收包、包处理和发包三个阶段,三个阶段可并发。
结合第一方面,在第一方面的第二种可能的实现方式中,所述通过所述任一接收端口接收第一数据包之后,所述方法还包括:
将所述第一数据包放入所述任一接收端口的保序队列中,所述保序队列中存储了不同CPU从所述任一接收端口接收到的数据包。
为了保证包的原有顺序,本发明还引入了保序队列,保序队列逻辑上为先进先出队列,从而保证先收到的数据包先被发出去。其中,保序队列与端口一一对应。不同CPU从同一端口接收到的数据包均被保存在同一个保序队列中。每一个CPU在对自身的数据包进行处理过程中,业务逻辑便会设定该数据包的目的发送端口。在该数据包处理完成后,该CPU竞争目的发送端口的发送权限。
结合第一方面的第二种可能的实现方式,在第一方面的第三种可能的实现方式中,所述竞争与第二数据包匹配的目的发送端口的发包权限,包括:
判断所述保序队列中可发送数据包的序列号是否与所述第二数据包中起始数据包的序列号一致,所述起始数据包指代在所述第二数据包中最先通过所述任一接收端口接收到的子数据包;
若所述保序队列中可发送数据包的序列号与所述第二数据包中起始数据包的序列号一致,则竞争所述目的发送端口的发包权限;
其中,每一个数据包的序列号由对其进行处理的CPU分配,并存储在与接收所述数据包的接收端口匹配的保序队列中。
各个接收到的数据包本身并不是真正存储在保序队列中,而是将各个数据包的序列号存储在保序队列中的相应位置,这样通过序列号便可以获取到各个数据包。
对于竞争发包权限的方式,举一个简单例子来说,假如当前保序队列中有10个已经处理完成的数据包,序号为10-20;t1时刻CPU1从接收端口P1收到了10个数据包,其在保序队列中的位置为21-30,t4时刻处理完成;t2时刻CPU2从接收端口P1也收到了10个数据包,其在保序队列中的位置为31-40,t3时刻处理完成。此时,保序队列中可发送数据包的序列号便为21。其中,t1时刻<t2时刻<t3时刻<t4时刻。由于CPU2先处理完成,但是保序队列中可发送数据包的序号为21,起始数据包的序列号31与序列号20不连续,因而CPU2会将数据包信息保存,而不去竞争端口发送权限。而t4时刻,CPU1处理完成,起始数据包的序列号21因与序列号20连续,因此会去竞争端口发送权限。
结合第一方面的第二种可能实现的方式,在第一方面的第四种可能的实现方式中,所述释放对所述任一接收端口的收包权限之后,所述方法还包括:
将所述保序队列中已经过所述CPU处理完成的所述第二数据包放入对应的端口发送序列中。
处理完成的数据包具体放入哪一个端口发送序列,是在对保序队列中的数据包进行处理过程中,由业务逻辑规定。其中,一个端口可对应一个或多个端口发送序列。
结合第一方面的第四种可能的实现方式,在第一方面的第五种可能的实现方式中,所述将所述保序队列中已经过所述CPU处理完成的所述第二数据包放入对应的端口发送序列中,包括:
将已经过所述CPU处理完成的数据包从所述保序队列中移出,并将所述数据包存储在中转缓存中;
在所述保序队列中需经所述CPU处理的数据包均处理完成后,按照先进先出规则,依次将存储在所述中转缓存中的数据包放入所述端口发送序列中。
结合第一方面,在第一方面的第六种可能的实现方式中,所述方法还包括:
若未竞争到所述目的发送端口的发包权限,则至少记录所述第二数据包中每一个数据包的发送端口、包类型和包状态。
其中,包类型可包括广播包、单播包和可忽略包等等,本发明实施例对此不进行具体限定。包状态表征数据包是未进行包处理、还是正在处理过程中或已处理完成。
第二方面,提供了一种基于多核转发的负载均衡装置,所述装置包括:
第一竞争模块,用于对于多个CPU中的每一个CPU,竞争多个接收端口的收包权限,所述收包权限指代接收数据包的权限;
接收模块,用于在竞争到任一接收端口的收包权限后,通过所述任一接收端口接收第一数据包;
第二竞争模块,用于竞争与第二数据包匹配的目的发送端口的发包权限,所述第二数据包指代已经过所述CPU处理完成的数据包,所述发包权限指代发送数据包的权限;
发送模块,用于在竞争到所述目的发送端口的发包权限后,通过所述目的发送端口发送所述第二数据包。
在第二方面的第一种可能的实现方式中,所述装置还包括:
释放模块,用于在所述第一数据包接收完毕后,释放所述任一接收端口的收包权限;在通过所述目的发送端口发送所述第二数据包后,释放所述目的发送端口的发包权限。
结合第二方面,在第二方面的第二种可能的实现方式中,所述装置还包括:
处理模块,用于将所述第一数据包放入所述任一接收端口的保序队列中,所述保序队列中存储了不同CPU从所述任一接收端口接收到的数据包。
结合第二方面的第二种可能的实现方式,在第二方面的第三种可能的实现方式中,所述第二竞争模块,用于判断所述保序队列中可发送数据包的序列号是否与所述第二数据包中起始数据包的序列号一致,所述起始数据包指代在所述第二数据包中最先通过所述任一接收端口接收到的子数据包;若所述保序队列中可发送数据包的序列号与所述第二数据包中起始数据包的序列号一致,则竞争所述目的发送端口的发包权限;
其中,每一个数据包的序列号由对其进行处理的CPU分配,并存储在与接收所述数据包的接收端口匹配的保序队列中。
结合第二方面的第二种可能实现的方式,在第二方面的第四种可能的实现方式中,所述处理模块,还用于将所述保序队列中已经过所述CPU处理完成的所述第二数据包放入对应的端口发送序列中。
结合第二方面的第四种可能的实现方式,在第二方面的第五种可能的实现方式中,所述处理模块,用于将已经过所述CPU处理完成的数据包从所述保序队列中移出,并将所述数据包存储在中转缓存中;在所述保序队列中需经所述CPU处理的数据包均处理完成后,按照先进先出规则,依次将存储在所述中转缓存中的数据包放入所述端口发送序列中。
结合第二方面,在第二方面的第六种可能的实现方式中,所述装置还包括:
记录模块,用于若未竞争到所述目的发送端口的发包权限,则至少记录所述第二数据包中每一个数据包的发送端口、包类型和包状态。
第三方面,提供了一种虚拟交换机,所述虚拟交换机包括多个CPU、多个接收端口、多个发送端口和存储器,所述存储器与所述处理器连接,所述存储器存储有程序代码,所述多个CPU用于调用所述程序代码,执行以下操作:
对于多个CPU中的每一个CPU,竞争多个接收端口的收包权限,所述收包权限指代接收数据包的权限;
在竞争到任一接收端口的收包权限后,通过所述任一接收端口接收第一数据包;
竞争与第二数据包匹配的目的发送端口的发包权限,所述第二数据包指代已经过所述CPU处理完成的数据包,所述发包权限指代发送数据包的权限;
在竞争到所述目的发送端口的发包权限后,通过所述目的发送端口发送所述第二数据包。
在第三方面的第一种可能的实现方式中,所述多个CPU用于调用所述程序代码,执行以下操作:
在所述第一数据包接收完毕后,释放所述任一接收端口的收包权限;
在通过所述目的发送端口发送所述第二数据包后,释放所述目的发送端口的发包权限。
结合第三方面,在第三方面的第二种可能的实现方式中,所述多个CPU用于调用所述程序代码,执行以下操作:
将所述第一数据包放入所述任一接收端口的保序队列中,所述保序队列中存储了不同CPU从所述任一接收端口接收到的数据包。
结合第三方面的第二种可能的实现方式,在第三方面的第三种可能的实现方式中,所述多个CPU用于调用所述程序代码,执行以下操作:
判断所述保序队列中可发送数据包的序列号是否与所述第二数据包中起始数据包的序列号一致,所述起始数据包指代在所述第二数据包中最先通过所述任一接收端口接收到的子数据包;
若所述保序队列中可发送数据包的序列号与所述第二数据包中起始数据包的序列号一致,则竞争所述目的发送端口的发包权限;
其中,每一个数据包的序列号由对其进行处理的CPU分配,并存储在与接收所述数据包的接收端口匹配的保序队列中。
结合第三方面的第二种可能实现的方式,在第三方面的第四种可能的实现方式中,所述多个CPU用于调用所述程序代码,执行以下操作:
将所述保序队列中已经过所述CPU处理完成的所述第二数据包放入对应的端口发送序列中。
结合第三方面的第四种可能的实现方式,在第三方面的第五种可能的实现方式中,所述多个CPU用于调用所述程序代码,执行以下操作:
将已经过所述CPU处理完成的数据包从所述保序队列中移出,并将所述数据包存储在中转缓存中;
在所述保序队列中需经所述CPU处理的数据包均处理完成后,按照先进先出规则,依次将存储在所述中转缓存中的数据包放入所述端口发送序列中。
结合第三方面,在第三方面的第六种可能的实现方式中,所述多个CPU用于调用所述程序代码,执行以下操作:
若未竞争到所述目的发送端口的发包权限,则至少记录所述第二数据包中每一个数据包的发送端口、包类型和包状态。
本发明实施例提供的技术方案带来的有益效果是:
由于端口与CPU之间不进行绑定,而是CPU公平竞争各个端口的收包权限和发包权限,在竞争到收包权限或发包权限后进行数据的收发,因此不会出现多个大流量的Port绑定至同一个CPU的情况,确保了CPU之间的负载均衡,且突破单个Port的处理能力受单个CPU处理能力的限制,达到了流量自适应,大大降低了时延增加甚至丢包等情况的出现。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是背景技术提供的一种基于多核转发的虚拟交换机的结构示意图;
图2是背景技术提供的一种端口与CPU的绑定示意图;
图3是本发明实施例提供的一种基于多核转发的负载均衡架构示意图;
图4是本发明实施例提供的一种转发处理流程的阶段示意图;
图5是本发明实施例提供的第一种保序队列的示意图;
图6是本发明实施例提供的一种基于多核转发的负载均衡方法的流程图;
图7是本发明实施例提供的第二种保序队列的示意图;
图8是本发明实施例提供的一种时序图;
图9是本发明实施例提供的一种业务链示意图;
图10是本发明实施例提供的一种基于多核转发的负载均衡方法的流程图;
图11是本发明实施例提供的一种基于多核转发的负载均衡装置的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
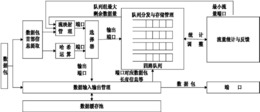
图3为本发明实施例提供的一种基于多核转发的负载均衡架构示意图,应用于虚拟交换机。参见图3,虚拟交换机包括多个CPU,对应图3中RxT1至RxTn,多个接收端口(In_port),对应图3中A1至Am,多个发送端口(Out_port),对应图3中B1至Bm。其中,多核代表具有多个CPU。多个CPU指代至少两个CPU。通常情况下,多核为几个或几十个CPU,本公开实施例对此不进行具体限定。为了保证包的原有顺序,该架构中还引入了保序队列,对应图3中保序队列A至保序队列M。其中,保序队列与接收端口为一一对应关系,即不同CPU从同一接收端口接收到的数据包均会按顺序进入相应端口的保序队列。数据包处理完成后,会按照先进先出的原则,将数据包放入对应的端口发送队列。其中,端口发送序列对应图3中TxQ1至TxQm。
综上所述,针对如图1所示的采用多核转发的虚拟交换机来说,本发明实施例不配置物理网卡和VM连接在虚拟交换机上的各个Port的CPU亲和性,即不预先配置各个端口与CPU的绑定关系,不同CPU之间公平竞争端口。在本发明实施例中,虚拟交换机将转发流程拆分为图4所示的收包(RX)、包处理(PROC)和发包(TX)三个阶段,且三个阶段可并发。参见图5,保序队列的长度为2的n次方,这样保证不会因为保序过程中的等待导致队列溢出而丢包,每一个接收端口对应一个保序队列,保序队列逻辑上为一个首尾相连的先进先出队列,可以视为环形队列。图5中列举的保序队列长度为2的12次方。由于保序队列的存在,使得不同CPU从相同端口接收到的数据包能够按照收包的时间先后顺序将包发出,避免了出现数据包乱序的情况。
参见图1,本发明实施例提供的虚拟交换机包括多个CPU、多个接收端口、多个发送端口和存储器,存储器与处理器连接,存储器存储有程序代码,多个CPU用于调用程序代码,执行以下操作:
对于多个CPU中的每一个CPU,竞争多个接收端口的收包权限,收包权限指代接收数据包的权限;
在竞争到任一接收端口的收包权限后,通过任一接收端口接收第一数据包;
竞争与第二数据包匹配的目的发送端口的发包权限,第二数据包指代已经过CPU处理完成的数据包,发包权限指代发送数据包的权限;
在竞争到目的发送端口的发包权限后,通过目的发送端口发送第二数据包。
在另一个实施例中,多个CPU用于调用程序代码,执行以下操作:
在第一数据包接收完毕后,释放任一接收端口的收包权限;
在通过目的发送端口发送第二数据包后,释放目的发送端口的发包权限。
在另一个实施例中,多个CPU用于调用程序代码,执行以下操作:
将第一数据包放入任一接收端口的保序队列中,保序队列中存储了不同CPU从任一接收端口接收到的数据包。
在另一个实施例中,多个CPU用于调用程序代码,执行以下操作:
判断保序队列中可发送数据包的序列号是否与第二数据包中起始数据包的序列号一致,起始数据包指代在第二数据包中最先通过任一接收端口接收到的子数据包;
若保序队列中可发送数据包的序列号与第二数据包中起始数据包的序列号一致,则竞争目的发送端口的发包权限;
其中,每一个数据包的序列号由对其进行处理的CPU分配,并存储在与接收数据包的接收端口匹配的保序队列中。
在另一个实施例中,多个CPU用于调用程序代码,执行以下操作:
将保序队列中已经过CPU处理完成的第二数据包放入对应的端口发送序列中。
在另一个实施例中,多个CPU用于调用程序代码,执行以下操作:
将已经过CPU处理完成的数据包从保序队列中移出,并将数据包存储在中转缓存中;
在保序队列中需经CPU处理的数据包均处理完成后,按照先进先出规则,依次将存储在中转缓存中的数据包放入端口发送序列中。
在另一个实施例中,多个CPU用于调用程序代码,执行以下操作:
若未竞争到目的发送端口的发包权限,则至少记录第二数据包中每一个数据包的发送端口、包类型和包状态。
本发明实施例提供的虚拟交换机,由于端口与CPU之间不进行绑定,而是CPU公平竞争各个端口的收包权限和发包权限,并在一次收包操作或发包操作完成后,立即释放对端口的收包权限或发包权限,因此不会出现多个大流量的Port绑定至同一个CPU的情况,确保了CPU之间的负载均衡,且突破单个Port的处理能力受单个CPU处理能力的限制,达到了流量自适应,大大降低了时延增加甚至丢包等情况的出现。
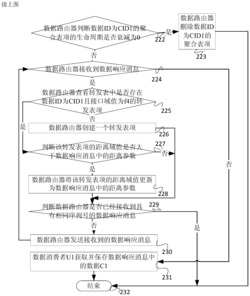
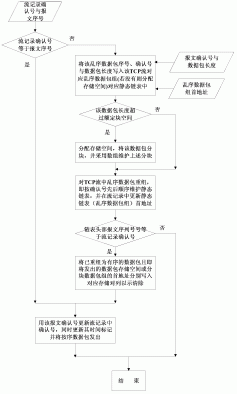
图6是本发明实施例提供的一种基于多核转发的负载均衡方法的流程图。以描述CPU的逻辑处理流程为例,该逻辑处理流程与图3所示的系统架构相对应,参见图6,方法流程包括:
601、对于多个CPU中的一个CPU,分别竞争每一个接收端口的收包权限。
以图3中端口A1至Am表征接收端口为例,则该CPU可依次按照A1、A2、A3、……、Am的顺序依次竞争对各个接收端口的收包权限,本发明实施例对此不进行具体限定。在对当前接收端口的收包权限竞争失败后,该CPU可立即转换到竞争下一个接收端口的收包权限。
602、在竞争到在竞争到任一接收端口的收包权限后,通过该接收端口接收第一数据包。
该CPU在竞争到任一接收端口的收包权限后,便可通过该接收端口接收从VM发送过来的数据包。其中,第一数据包中包括多个数据包,本发明实施例仅以第一数据包指代该批数据包。
603、获取第一数据包中每一个数据包的序列号,将该序列号存储到该接收端口的保序队列中。
其中,第一数据包中每一个数据包均由该CPU为其分配了一个序列号,序列号越大,表明该数据包被接收到的时间越晚。在本发明实施例中,第一数据包泛指当前通过该接收端口接收到的全部数据包。也即,随着时间的增加,对于一个保序队列中的数据包来说,序列号是递增的。举个简单例子来说,t1时刻早于t2时刻,在t1时刻和t2时刻分别从端口A1接收到了10个数据包,则t1时刻对应的10个数据包的序列号要大于t2时刻对应的10个数据包。比如,t1时刻接收到的数据包的序列号对应为1至10,t2时刻接收到的数据包的序列号对应为11至20。综上所述,每一个数据包的序列号由对其进行处理的CPU分配,并存储在与接收数据包的接收端口匹配的保序队列中。
604、释放对该接收端口的收包权限。
在本发明实施例中,为了不让该CPU长时间对该接收端口进行占用,进而可能出现负载不均衡的情况,在一次收包操作后,该CPU需立即释放对该接收端口的收包权限。再次对端口的收包权限进行竞争。
605、将第一数据包放入该接收端口的保序队列中。
其中,保序队列中存储了不同CPU从任一端口接收到的数据包。各个接收到的数据包本身并不是真正存储在保序队列中,而是将各个数据包的指针存储在保序队列中的相应位置,这样通过指针便可以获取到各个数据包。
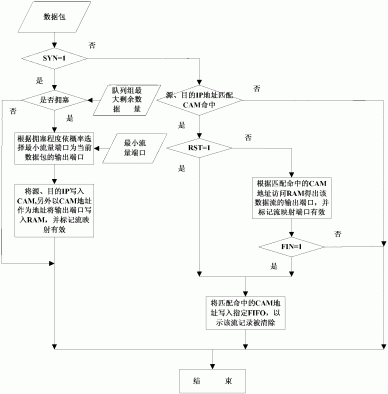
606、竞争与第二数据包匹配的目的发送端口的发包权限。
每一个CPU在对自身的数据包进行处理过程中,业务逻辑便会设定该数据包的目的发送端口。在该数据包处理完成后,该CPU便可竞争目的发送端口的发送权限。需要说明的是,本发明实施例中发送端口的发送权限抢占还需依据下述规则进行:
判断该接收端口对应保序队列中可发送数据包的序列号是否与第二数据包中起始数据包的序列号一致;若该保序队列中可发送数据包的序列号与第二数据包中起始数据包的序列号一致,则竞争目的发送端口的发包权限。
其中,可发送数据包指代保序队列中当前第一个待发送的数据包。第二数据包指代保序队列中已经处理完成的数据包。起始数据包指代在第二数据包中最先通过任一接收端口接收到的子数据包。在本发明实施例中,第二数据包泛指当前已经过CPU处理完成的全部数据包。在第二数据包中包括多个子数据包。需要说明的是,上述发送权限抢占规则的制定原理是:从同一端口接收到的数据包,先被接收到的数据包先被发送出去。具体的解释说明详见下述举例:
参见图7和图8,假如当前保序队列中有10个已经处理完成的数据包,序号为10-20;t1时刻CPU1从接收端口P1收到了10个数据包,其在保序队列中的位置为21-30,t4时刻处理完成;t2时刻CPU 2从接收端口P1也收到了10个数据包,其在保序队列中的位置为31-60,t3时刻处理完成。此时,保序队列中可发送数据包的序列号便为21。其中,t1时刻<t2时刻<t3时刻<t4时刻。由于CPU2先处理完成,但是保序队列中可发送数据包的序号为21,此时的10个数据包中起始数据包的序列号31与序列号20不连续,因而CPU2会将数据包信息保存,而不去竞争端口发送权限。而t4时刻,CPU1处理完成,此时的10个数据包中起始数据包的序列号21因与序列号20连续,因此会去竞争端口发送权限。
607、在竞争到目的发送端口的发包权限后,通过目的发送端口,发送保序队列中已经过该CPU处理完成的第二数据包。
在发送数据包之前,好包括保序队列中数据包的出列操作,详细如下:
按照预设规则,将保序队列中已经过该CPU处理完成的第二数据包放入对应的端口发送序列中。
其中,预设规则在本发明实施例中指代先进先出规则,以保证先被接收到的数据包先被发出去。即,将已经过该CPU处理完成的数据包从保序队列中移出,并将该批数据包存储在中转缓存中;在保序队列中需经该CPU处理的数据包均处理完成后,将存储在中转缓存中的全部数据包作为第二数据包,按照先进先出规则将第二数据包放入端口发送序列中。处理完成的数据包具体放入哪一个端口发送序列,是在对保序队列中的数据包进行处理过程中,由业务逻辑规定。其中,一个端口可对应一个或多个端口发送序列。
608、释放对目的发送端口的发包权限。
在本发明实施例中,为了不让该CPU长时间对该发送端口进行占用,进而可能出现负载不均衡的情况,在一次发包操作后,该CPU需立即释放对该发送端口的发包权限。再次对端口的发包权限进行竞争。
609、若未竞争到目的发送端口的发包权限,则至少记录第二数据包中每一个数据包的发送端口、包类型和包状态。
其中,包类型可包括广播包、单播包和可忽略包等等,本发明实施例对此不进行具体限定。包状态表征数据包是未进行包处理、还是正在处理过程中或已处理完成。
本发明实施例提供的方法,由于端口与CPU之间不进行绑定,而是CPU公平竞争各个端口的收包权限和发包权限,并在一次收包操作或发包操作完成后,立即释放对端口的收包权限或发包权限,因此不会出现多个大流量的Port绑定至同一个CPU的情况,确保了CPU之间的负载均衡,且突破单个Port的处理能力受单个CPU处理能力的限制,达到了流量自适应,大大降低了时延增加甚至丢包等情况的出现。
上述实施例所示的基于多核转发的负载均衡方法主要应用于如图9所示的场景中。在NFV领域,有一种技术ServiceChain(业务链)。在移动、固定宽带和数据中心网络边缘,特定用户的特定业务流需要按顺序通过图9中所示的多个VAS进行逐个处理。例如超文本传输协议(英文:HyperText Transfer Protocol,简称:HTTP)网站上网络业务流需要依次串接内容过滤、缓存服务和防火墙三个VAS处理,然后再进入网络(Internet)。在运营商看来,每个用户对应一个业务套餐,一个业务套餐可对应一个ServiceChain,其内容可以更改,即使用的服务或VAS序列可以变更,这样可以达到灵活控制的目的。
在图9中,某台服务器运行了三台VM,对应三个VAS,分别用于处理内容过滤、缓存服务和防火墙三个服务,这三台VM连接到虚拟交换机上完成流量交换。用户A的业务流会经过内容过滤、缓存服务和防火墙三个VAS依次处理。而用户B的业务流只经过内容过滤和缓存服务两个VAS处理。这样一来,用户A和用户B的套餐不同,那么ServiceChain的规则就不同,其对应的数据流便由不同的VAS序列处理。如果要修改用户B的套餐,增加防火墙服务,则只需要修改其对应的ServiceChain规则即可,便可以达到与用户A享受相同套餐的目的。
当用户套餐发生变化时,其所经过的VAS序列也会发生变化,那么每个VAS所处理的流量也会发生变化,这样很可能影响到其相关port所在CPU。而采用本发明实施例提供的负载均衡方法,会保证业务稳定的运行,尽可能降低时延增加和丢包情况的出现概率,不会出现用户看视频卡住或者电话语音效果变差等现象,提升了用户体验。
图10是本发明实施例提供的一种基于多核转发的负载均衡方法的流程图。参见图10,该方法流程包括:
1001、对于多个CPU中的每一个CPU,竞争多个接收端口的收包权限。
其中,收包权限指代接收数据包的权限。
1002、在竞争到任一接收端口的收包权限后,通过任一接收端口接收第一数据包。
1003、竞争与第二数据包匹配的目的发送端口的发包权限。
其中,第二数据包指代已经过CPU处理完成的数据包,发包权限指代发送数据包的权限。
1004、在竞争到目的发送端口的发包权限后,通过目的发送端口发送第二数据包。
在另一个实施例中,该方法还包括:
在第一数据包接收完毕后,释放任一接收端口的收包权限;
在通过目的发送端口发送第二数据包后,释放目的发送端口的发包权限。
在另一个实施例中,通过任一接收端口接收第一数据包之后,该方法还包括:
将第一数据包放入任一接收端口的保序队列中,保序队列中存储了不同CPU从任一接收端口接收到的数据包。
在另一个实施例中,竞争与第二数据包匹配的目的发送端口的发包权限,包括:
判断保序队列中可发送数据包的序列号是否与第二数据包中起始数据包的序列号一致,起始数据包指代在第二数据包中最先通过任一接收端口接收到的子数据包;
若保序队列中可发送数据包的序列号与第二数据包中起始数据包的序列号一致,则竞争目的发送端口的发包权限;
其中,每一个数据包的序列号由对其进行处理的CPU分配,并存储在与接收数据包的接收端口匹配的保序队列中。
在另一个实施例中,释放对任一接收端口的收包权限之后,该方法还包括:
将保序队列中已经过CPU处理完成的第二数据包放入对应的端口发送序列中。
在另一个实施例中,将保序队列中已经过CPU处理完成的第二数据包放入对应的端口发送序列中,包括:
将已经过CPU处理完成的数据包从保序队列中移出,并将数据包存储在中转缓存中;
在保序队列中需经CPU处理的数据包均处理完成后,按照先进先出规则,依次将存储在中转缓存中的数据包放入端口发送序列中。
在另一个实施例中,该方法还包括:
若未竞争到目的发送端口的发包权限,则至少记录第二数据包中每一个数据包的发送端口、包类型和包状态。
本发明实施例提供的方法,由于端口与CPU之间不进行绑定,而是CPU公平竞争各个端口的收包权限和发包权限,并在一次收包操作或发包操作完成后,立即释放对端口的收包权限或发包权限,因此不会出现多个大流量的Port绑定至同一个CPU的情况,确保了CPU之间的负载均衡,且突破单个Port的处理能力受单个CPU处理能力的限制,达到了流量自适应,大大降低了时延增加甚至丢包等情况的出现。
图11是本发明实施例提供的一种基于多核转发的负载均衡装置。参见图11,该装置包括:第一竞争模块1101、接收模块1102、第二竞争模块1103、发送模块1104。
其中,第一竞争模块1101与接收模块1102连接,用于对于多个CPU中的每一个CPU,竞争多个接收端口的收包权限,收包权限指代接收数据包的权限;接收模块1102与第二竞争模块1103连接,用于在竞争到任一接收端口的收包权限后,通过任一接收端口接收第一数据包;第二竞争模块1103与发送模块1104连接,用于竞争与第二数据包匹配的目的发送端口的发包权限,第二数据包指代已经过CPU处理完成的数据包,发包权限指代发送数据包的权限;发送模块1104,用于在竞争到目的发送端口的发包权限后,通过目的发送端口发送第二数据包。
在另一个实施例中,该装置还包括:
释放模块,用于在第一数据包接收完毕后,释放任一接收端口的收包权限;在通过目的发送端口发送第二数据包后,释放目的发送端口的发包权限。
在另一个实施例中,该装置还包括:
处理模块,用于将第一数据包放入任一接收端口的保序队列中,保序队列中存储了不同CPU从任一接收端口接收到的数据包。
在另一个实施例中,第二竞争模块,用于判断保序队列中可发送数据包的序列号是否与第二数据包中起始数据包的序列号一致,起始数据包指代在第二数据包中最先通过任一接收端口接收到的子数据包;若保序队列中可发送数据包的序列号与第二数据包中起始数据包的序列号一致,则竞争目的发送端口的发包权限;
其中,每一个数据包的序列号由对其进行处理的CPU分配,并存储在与接收数据包的接收端口匹配的保序队列中。
在另一个实施例中,处理模块,还用于将保序队列中已经过CPU处理完成的第二数据包放入对应的端口发送序列中。
在另一个实施例中,处理模块,用于将已经过CPU处理完成的数据包从保序队列中移出,并将数据包存储在中转缓存中;在保序队列中需经CPU处理的数据包均处理完成后,按照先进先出规则,依次将存储在中转缓存中的数据包放入端口发送序列中。
在另一个实施例中,该装置还包括:
记录模块,用于若未竞争到目的发送端口的发包权限,则至少记录第二数据包中每一个数据包的发送端口、包类型和包状态。
本发明实施例提供的装置,由于端口与CPU之间不进行绑定,而是CPU公平竞争各个端口的收包权限和发包权限,并在一次收包操作或发包操作完成后,立即释放对端口的收包权限或发包权限,因此不会出现多个大流量的Port绑定至同一个CPU的情况,确保了CPU之间的负载均衡,且突破单个Port的处理能力受单个CPU处理能力的限制,达到了流量自适应,大大降低了时延增加甚至丢包等情况的出现。
需要说明的是:上述实施例提供的基于多核转发的负载均衡装置在进行基于多核转发的负载均衡处理时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的基于多核转发的负载均衡装置与基于多核转发的负载均衡装置方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
基于多核转发的负载均衡方法、装置及虚拟交换机专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。






动态评分
0.0