








专利摘要
本发明提出了一种高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法。该方法在分析烧炉过程空燃比设定值对炉内工况和送风结果影响的基础上,构建状态参数(拱顶温度、烟气温度、拱顶温变速率、烟气温变速率、煤气压力、空气压力和空燃比)与操作参数(煤气阀门开度和空气阀门开度)的历史数据库,提出结合送风结果的热风炉烧炉过程能效评价方法,挖掘优良烧炉炉次。融合密度峰值快速搜索聚类和相关性分析方法,建立模式匹配空间,根据状态参数的相似度衡量进行分时段多级匹配,搜寻烧炉各阶段最优的操作参数,达到节约煤气用量、提高送风温度和保障送风时长的目的。
权利要求
1.高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法,其特征在于,包括以下步骤:
采集高炉热风炉的工况数据,建立烧炉操作样本集,其中工况数据包括状态参数和操作参数;
根据所述烧炉操作样本集建立高炉热风炉烧炉过程能效评价模型,并根据所述能效评价模型从所述烧炉操作样本集中筛选出优良烧炉炉次;
采用密度峰值快速搜索聚类算法,对所述优良烧炉炉次进行聚类分类,获得聚类类别并根据预定义的综合评价指标,对所述优良烧炉炉次进行匹配优先级分类,获得匹配优先级类别;
根据所述优良烧炉炉次的工况数据、聚类类别以及优先级类别,建立模式匹配空间;
基于相似度衡量将高炉热风炉的当前工况数据与所述模式匹配空间进行分时段多级匹配,搜寻高炉热风炉烧炉各阶段最优的空燃比及与所述空燃比对应的当前操作参数。
2.根据权利要求1所述的高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法,其特征在于,构建高炉热风炉烧炉过程能效评价模型包括以下步骤:
对所述烧炉操作样本集的样本数据进行预处理;
选择评价烧炉炉次的工况数据;
根据所选评价烧炉炉次的工况数据,建立高炉热风炉烧炉过程能效评价模型,所述高炉热风炉烧炉过程能效评价模型的计算公式为:
其中T、t1、t2、L分别表示送风温度、烧炉时长、送风时长和煤气总用量, 和 分别是对各个烧炉炉次所有煤气用量和送风温度的统计平均值。
3.根据权利要求2所述的高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法,其特征在于,根据所述能效评价模型筛选出优良烧炉炉次的具体方式为:
4.根据权利要求1所述的高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法,其特征在于,所述获得聚类类别包括以下步骤:
根据所述优良烧炉炉次空燃比曲线的二维统计特征,计算各烧炉炉次空燃比曲线之间的距离;
根据各烧炉炉次空燃比曲线之间的距离,计算各烧炉炉次空燃比曲线间规整路径距离以及各烧炉炉次空燃比曲线样本的局部密度和距离;
确定预聚类中心,根据所述预聚类中心确定非预聚类样本的归类属性并对非预聚类中心的样本点进行归类;
提取预聚类中心样本数据和非预聚类样本数据中各烧炉阶段初始拱顶温度、初始烟气温度以及对应温升数据并计算欧式距离,根据欧式距离计算预聚类中心样本和非预聚类样本数的局部密度以及距离得到聚类中心以及对应类别的非中心样本从而获得所述优良烧炉炉次的聚类类别。
5.根据权利要求1所述的高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法,其特征在于,所述综合评价指标的计算公式为:
其中 Li分别表示第i段的初始拱顶温度、拱顶温升、烟气温升、煤气用量;TG、ΔTY、L0分别为其相对应的期望值,设置TG、ΔTY、L0为第i段燃烧阶段所属类别中对应特征的统计平均值,a1、a2、a3为权重,且a1+a2+a3=1。
6.根据权利要求1所述的高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法,其特征在于,基于相似度衡量对当前工况与所述模式匹配空间进行分时段多级匹配包括以下步骤:
采集高炉热风炉烧炉过程的当前状态参数,并基于所述聚类中心获得所述当前状态参数所属的聚类类别;
在所述当前状态参数所属的聚类类别对应的模式匹配空间中,按匹配优先级类别逐一匹配获得匹配度最高的操作模式以及与所述操作模式对应的空燃比给定曲线;
定时采集高炉热风炉烧炉过程的状态参数,判断所述状态参数与已匹配操作模式的匹配相似度是否超出设定阈值,若未超出设定阈值,继续按照当前已获得空燃比给定曲线进行煤气阀门开度和空气阀门开度的设定,否则,重新搜索聚类中心选择聚类类别。
7.根据权利要求6所述的高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法,其特征在于,获得所述当前状态参数所属的聚类类别是根据聚类相似度指标来确定的,所述聚类相似度指标为:
其中, 是向量Pi和向量Pj的相似度,其范围在(0,1], 越靠近1,则向量Pi和向量Pj越相似;当 时,向量Pi和向量Pj一致;将相似度指标最大的类别中心Ci作为当前状态参数所属类别。
8.根据权利要求6所述的高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法,其特征在于,所述匹配相似度的模型为:
其中,Ψ(Pi,t,Pj,t)是向量Pi,t和向量Pj,t的相似度,当Ψ(Pi,t,Pj,t)=0时,向量Pi,t和向量Pj,t一致;其中t为当前烧炉时间,uik,t为t时刻第k个参数,分别为拱顶温度、烟气温度、拱顶温变速率、烟气温变速率、煤气压力、空气压力、空燃比。
说明书
技术领域
本发明涉及高炉热风炉优化控制技术领域,尤其涉及一种高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法。
背景技术
大型热风炉是现代高炉炼铁系统的重要组成部分之一,主要为高炉提供持续稳定的高温热风。据统计,热风温度每提高100℃,可提高风口燃烧温度20~300℃,可增产3%~5%,可降低焦比4%~7%,还可允许增加喷吹煤粉15~40Kg/t。即提高热风炉的风温,对高炉炼铁过程实现低碳高效生产具有非常重要的意义。高炉煤气经过干法除尘等处理,输送至热风炉顶部与预热后的空气按照设定的空燃比进行燃烧,在炉内的蓄热室储存热量以完成送风目标。故空燃比设置的合理与否不仅是决定烧炉过程燃烧效率和蓄热效率的关键因素,而且也是拱顶温度和烟气温度变化及其变化速率的直接影响因素。因此,如何优化确定燃烧时期的空燃比是提高热风温度、减少高炉焦比以及节约煤气用量的关键问题。
目前国内外对热风炉燃烧控制方案研究主要集中于建立基于机理的数学模型和基于数据的人工智能方式。对热风炉炉内建立机理模型对分析热风炉内部复杂炉况有巨大的作用,在设计控制方案和优化控制能够有效提供思路,但建立精确的数学模型难度大,需要完备的检测设备。不同的热风炉系统具有各自独特的特性参数,无法建立统一的数学模型,通用性差。基于数据的人工智能控制方案主要有模糊控制、神经网络控制、专家系统等。专家系统可靠性高,易于维护,充分利用现有的设备和数据,但制造成本高,提取规则的过程繁琐困难。模糊控制不需建立精确的数学模型,抗干扰能力强,但难以保证控制效果最优。神经网络自主学习能力和非线性映射能力强,但热风炉烧炉过程影响因素众多,神经网络容易丢失有用信息。这些因素导致了现有技术无法确定高炉热风炉烧炉过程各阶段最优的空燃比及操作参数。
发明内容
本发明目的在于提供一种高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法,以解决传统方法无法建立精确数学模型从而计算最佳空燃比及操作参数的现有技术问题。
为实现上述目的,本发明提供了一种高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法,包括以下步骤:
采集高炉热风炉的工况数据,获得烧炉操作样本集,其中工况数据包括状态参数和操作参数;
根据烧炉操作样本集建立高炉热风炉烧炉过程能效评价模型,并根据能效评价模型从烧炉操作样本集中筛选出优良烧炉炉次;
采用密度峰值快速搜索聚类算法,对优良烧炉炉次进行聚类分类,获得聚类类别并根据预定义的综合评价指标,对优良烧炉炉次进行匹配优先级分类,获得匹配优先级类别;
根据优良烧炉炉次的工况数据、聚类类别以及优先级类别,建立模式匹配空间;
基于相似度衡量将当前工况数据与模式匹配空间进行分时段多级匹配,搜寻高炉热风炉烧炉各阶段最优的空燃比及与空燃比对应的当前操作参数。
进一步地,构建高炉热风炉烧炉过程能效评价模型包括以下步骤:
对烧炉操作样本集的样本数据进行预处理;
选择评价烧炉炉次的工况数据;
根据所选评价烧炉炉次的工况数据,建立热风炉烧炉过程能效评价模型,高炉热风炉烧炉过程能效评价模型的计算公式为:
其中T,t1,t2,L分别表示送风温度、烧炉时长、送风时长和煤气总用量, 和 分别是对各个烧炉炉次所有煤气用量和送风温度的统计平均值。
进一步地,根据能效评价模型筛选出优良烧炉炉次的具体方式为:
进一步地,获得聚类类别包括以下步骤:
根据所述优良烧炉炉次空燃比曲线的二维统计特征,计算各烧炉炉次空燃比曲线之间的距离;
根据各烧炉炉次空燃比曲线之间的距离,计算各烧炉炉次空燃比曲线间规整路径距离以及各烧炉炉次空燃比曲线样本的局部密度以及距离;
确定预聚类中心,根据所述预聚类中心确定非预聚类样本的归类属性并对非预聚类中心的样本点进行归类;
提取预聚类中心样本数据和非预聚类样本数据中各烧炉阶段初始拱顶温度、初始烟气温度以及对应温升数据并计算欧式距离,根据欧式距离计算预聚类中心样本和非预聚类样本数的局部密度以及距离得到聚类中心以及对应类别的非中心样本从而获得所述优良烧炉炉次的聚类类别。
进一步地,综合评价指标的计算公式为:
其中 Li分别表示第i段的初始拱顶温度,拱顶温升、烟气温升、煤气用量;TG,ΔTY,L0分别为其相对应的期望值,设置TG,ΔTY,L0为第i段燃烧阶段所属类别中对应特征的统计平均值,a1、a2、a3为权重,且a1+a2+a3=1。
进一步地,基于相似度衡量对当前工况与模式匹配空间进行分时段多级匹配包括以下步骤:
采集高炉热风炉烧炉过程的当前状态参数,并基于聚类中心获得当前状态参数所属的聚类类别;
在当前状态参数所属的聚类类别对应的模式匹配空间中,按匹配优先级类别逐一匹配获得匹配度最高的操作模式以及与操作模式对应的空燃比给定曲线;
定时采集高炉热风炉烧炉过程的状态参数,判断状态参数与已匹配操作模式的匹配相似度是否超出设定阈值,若未超出设定阈值,继续按照当前已获得空燃比给定曲线进行煤气阀门开度和空气阀门开度的设定,否则,重新搜索聚类中心选择聚类类别。
进一步地,获得当前状态参数所属的聚类类别是根据聚类相似度指标来确定的,聚类相似度指标:
其中, 是向量Pi和向量Pj的相似度,其范围在(0,1], 越靠近1,则向量Pi和向量Pj越相似;当 时,向量Pi和向量Pj一致;将相似度指标最大的类别中心Ci作为当前状态参数所属类别。
进一步地,匹配相似度的模型为:
其中,Ψ(Pi,t,Pj,t)是向量Pi,t和向量Pj,t的相似度,当Ψ(Pi,t,Pj,t)=0时,向量Pi,t和向量Pj,t一致。其中t为当前烧炉时间,uik,t为t时刻第k个参数,分别为拱顶温度,烟气温度,拱顶温变速率,烟气温变速率,煤气压力,空气压力,空燃比。
本发明基于采样数据以及热风炉工艺特点,挖掘优良烧炉炉次,采用密度峰值快速搜索聚类算法确定对复杂工况的类别,并根据综合评价指标划分样本优良等级,确立模式匹配空间,定时采集工况数据进行分时段多级匹配实现烧炉过程空燃比寻优的目的。本发明充分利用热风炉可检测到的工况数据,利用数据挖掘从海量历史数据中挖掘规律,有效地在实现节能和降低成本的目标上完成送入高炉热风的温度要求,对热风炉烧炉过程操作现场具有更好的指导作用,对实现热风炉自动烧炉意义重大。
除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照附图,对本发明作进一步详细的说明。
附图说明
构成本申请的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
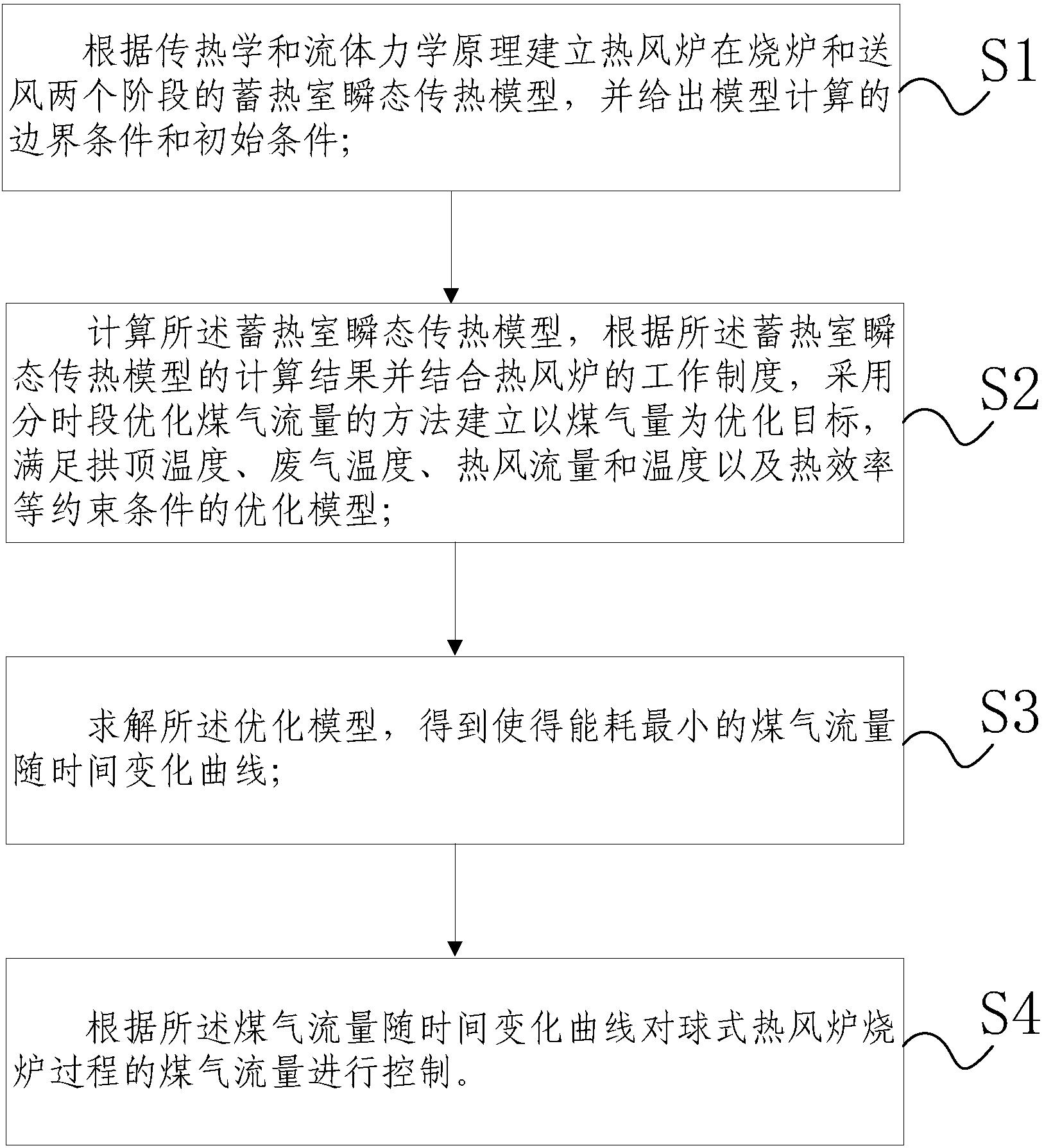
图1是本发明优选实施例的高炉热风炉烧炉过程操作参数寻优方法流程图;
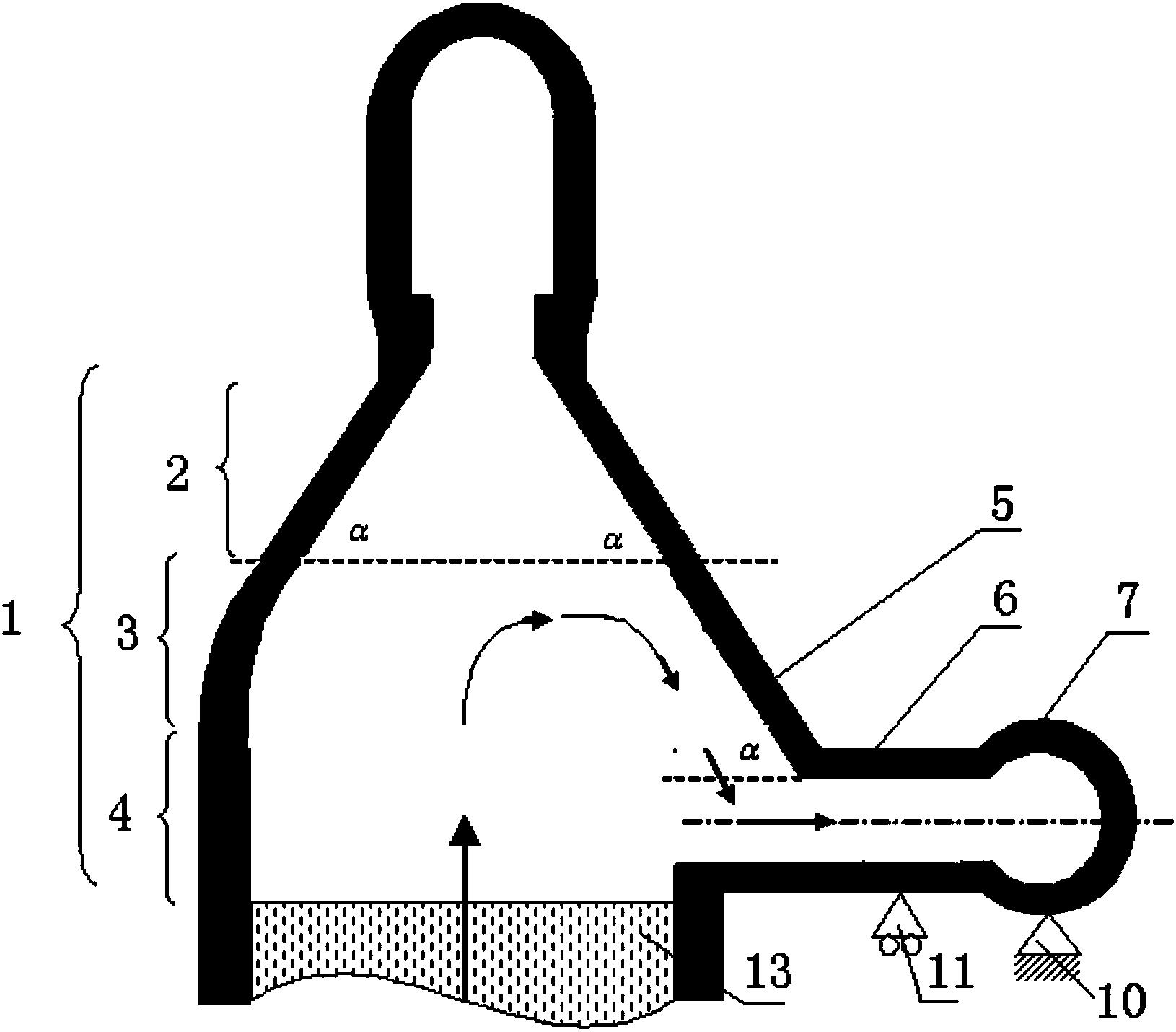
图2是本发明优选实施例的高炉热风炉烧炉过程示意图;
图3是本发明优选实施例的模式匹配空间建立流程图;
图4是本发明优选实施例的操作模式多级匹配流程图;
图5是本发明优选实施例的烧炉过程各阶段操作模式匹配流程图。
具体实施方式
以下结合附图对本发明的实施例进行详细说明,但是本发明可以由权利要求限定和覆盖的多种不同方式实施。
图2为高炉热风炉烧炉过程,高炉煤气经过干法除尘等处理,输送至热风炉顶部与预热后的空气按照设定的空燃比进行燃烧,顶部燃烧的燃气与蓄热室内的蓄热球进行热交换在炉内的蓄热室储存热量以完成送风目标。故空燃比设置的合理与否不仅是决定烧炉过程燃烧效率和蓄热效率的关键因素,而且也是拱顶温度和烟气温度变化及其变化速率的直接影响因素。
本发明提出了如图1所示的高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法,包括:
S1、采集高炉热风炉的工况数据,建立烧炉操作样本集,其中工况数据包括状态参数和操作参数。
采集高炉热风炉烧炉阶段和送风阶段的温度、压力等数据,对采集的数据进行分析后,构建烧炉操作样本集,烧炉操作样本中包括高炉热风炉烧炉过程中的操作经验以及对应的工况数据。工况数据包括状态参数和操作参数。状态参数包括拱顶温度、烟气温度、拱顶温变速率、烟气温变速率、煤气压力、空气压力和空燃比。操作参数包括煤气阀门开度、空气阀门开度。
S2、根据烧炉操作样本集建立高炉热风炉烧炉过程能效评价模型,并根据能效评价模型从烧炉操作样本集中筛选出优良烧炉炉次。
由于存在人工失误等情况,在烧炉过程中热风炉出现欠烧或者过烧等问题,导致热风温度过低、送风时长短或煤气用量过大,造成烧炉操作样本集中既包含优良操作样本又包含非优良操作样本,而非优良操作样本会影响影响后续匹配。因此建立了高炉热风炉过程能效评价模型,以筛选出优良的烧炉炉次,从而能够保存热风炉烧炉过程中的优良操作样本,即保存大量专家操作经验以及对应的工况数据来指导现场操作。
S3、采用密度峰值快速搜索聚类算法,对优良烧炉炉次进行聚类分类,获得聚类类别并根据预定义的综合评价指标,对优良烧炉炉次进行匹配优先级分类,获得匹配优先级类别。
通过分段聚合特征表得到各烧炉过程空燃比曲线的二维统计特征,即整体趋势变化特征。再基于相似度衡量原理计算各组特征间的规整路径距离。然后规整路径距离计算烧炉操作样本的局部密度和距离,根据规整路径距离以及烧炉样本的局部密度和距离确定类簇中心以及对应类别的非中心样本完成对对优良烧炉炉次的聚类分类。根据预定义的综合评价指标公式,综合该燃烧时段的拱顶温升、烟气温升和能耗情况将各炉次划分为优、良、中三个等级,其中优级的匹配优先级最高,中级的匹配优先级最低。综合评价指标越小,说明其指标越好。
S4、根据优良烧炉炉次的工况数据、聚类类别以及优先级类别,建立模式匹配空间。
参见图3,建立高炉热风炉烧炉过程优化操作模式匹配集,即对大量烧炉操作经验,以操作模式向量的形式进行记录。操作模式向量P由烧炉过程的状态参数U以及相对应的操作参数Y构成,其输出是综合评价指标E。基于相关性分析,确定状态参数U={u1,u2,…,u7},分别为拱顶温度、烟气温度、拱顶温变速率、烟气温变速率、煤气压力、空气压力、空燃比;操作参数Y={y1,y2},分别表示煤气阀门开度、空气阀门开度。将热风炉烧炉过程各燃烧阶段内对应所有的操作模式进行组合,可形成热风炉烧炉阶段操作模式,即
式中C表示该燃烧阶段所有操作模式的个数。将热风炉从开始烧炉至准备送风这段时间所有控制阶段序号对应的烧炉阶段操作模式组合起来,可形成热风炉烧炉过程操作模式。设Ph为任意一个烧炉阶段操作模式,h=1,2,3,…,则实际生产过程中所有优良炉次的烧炉阶段操作模式组成操作模式匹配集V,即V={P1,P2,…,Ph,…},并结合上述聚类结果和综合评价指标对空间进行类别和匹配优先级的划分。
S5、基于相似度衡量将当前工况数据与模式匹配空间进行分时段多级匹配,搜寻烧炉各阶段最优的空燃比及与空燃比对应的当前操作参数。
优选地,根据工况数据选择烧炉操作样本集包括以下步骤:
S11、对烧炉操作样本集的样本数据进行预处理。
由于采集工况数据时,存在高炉休风、减风、热风炉维修的情况或者检测设备在恶劣工作环境下出现故障等,导致采集到的数据存在缺失值或者异常值,其对热风炉运行规律的研究十分不利,因此必须对缺失值和异常值进行处理。在采样过程中,受到热风炉运行过程炉况不稳定或者检测设备不精确等非正常状况,数据存在异常跳变。这些跳变数据在一定程度上会改变数据的变化趋势,影响后期模式匹配的准确性,因此需要对跳变数据进行滤波。通过拉伊达准则检测跳变数据,方法如下:
其中 为xi的残差。若残差|Vi|>3σ,则该数据为跳变数据,通过尖峰噪声滤波算法予以补偿,再对补偿后的数据中较小的高频测量噪声波动干扰采用移动平均滤波算法进行滤波处理。由于各数据变量量纲不同,增加了计算时间成本且影响匹配精度,因此需要对滤波处理后的数据变量进行归一化处理来消除变量间的量纲影响。方法如下:
其中xi、 分别为第i个数据变量归一化前、后取值, σ分别为第i个变量归一化前的平均值和标准差。
S12、选择评价烧炉炉次的工况数据。
由于热风炉烧炉过程中存在人工失误等情况,在烧炉过程中热风炉出现欠烧或者过少等问题,导致热风温度过低、送风时长短或煤气用量过大。因此结合对现场操作工艺的了解和对预处理后数据的分析选择送风时长、烧炉时长、送风温度和煤气总用量来评价热风炉烧炉好坏的因素。
S13、根据所选评价烧炉炉次的工况数据,建立热风炉烧炉过程能效评价模型,热风炉烧炉过程能效评价模型的计算公式为:
其中T、t1、t2、L分别表示送风温度、烧炉时长、送风时长、煤气总用量, 和 分别是对样本集所有煤气用量和送风温度的统计平均值。当U=(0,0.6)∪(1.5,+∞)时,判断该样本为非优良样本;当U=[0.6,1.5]时,判断该样本为优良样本。采用能效评价方法对各样本进行筛选,避免热风炉烧炉过程,由于工人经验不足或者操作失误等原因,造成欠烧和过烧的问题:欠烧导致送风温度过低,难以达到高炉炼铁要求,使炼铁质量下降;送风时间过低,产生连锁反应影响下一炉送风质量;过烧导致煤气用量浪费,影响热风炉使用寿命,出现安全隐患。
优选地,获得聚类类别包括以下步骤:
S31:根据优良烧炉炉次空燃比曲线的二维统计特征,计算各烧炉炉次空燃比曲线之间的距离。
本发明采用密度峰值快速搜索聚类算法实现对优良烧炉炉次的分类,提高匹配速度,避免盲目搜索。首先,通过分段聚合特征表示得到各烧炉过程空燃比曲线的二维统计特征,即整体趋势变化特征;基于相似度衡量原理,计算各组特征间的规整路径距离,进行预分类得到预聚类中心样本集和非预聚类样本集。
根据一次烧炉过程各燃烧阶段传热机理和操作工艺的不同,提取各阶段初始拱项温度和初始烟气温度以及对应温升数据,对预聚类中心样本集和非预聚类样本集进行二级分类确定类别数Nc、类别中心 各非中心样本的归类属性。历史数据集X={x1,x2,…,xn},其中n代表所包含的样本总数,对数据集X进行如下划分:
基于分段聚合特征表示方法,将空燃比曲线Q={q1,q2,…,qn}平均分成λ条序列段,由分段数据的均值和标准差表示各序列段,得到均值特征序列{μ1,μ2,…,μλ}和标准差特征序列{σ1,σ2,…,σλ}。基于均值特征序列和标准差特征序列的线性组合计算各曲线之间的距离,β∈(0,1),即:
d(qi,cj)=(μio-μjo)2+β(σio-σjo)2。
S32:根据各烧炉炉次空燃比曲线之间的距离,计算各烧炉炉次空燃比曲线间规整路径距离以及各烧炉炉次空燃比曲线样本的局部密度以及距离。
式中,
Q={q1,q2,…,qn},C={c1,c2,…,cm}
wk={i,j}k
d(qi,cj)=(qi-cj)2
W={w1,w2,…,wk,…,wK}表示qi和cj之间失真度的对整映射程度d(qi,cj)的路径集合。令wk=(a,b),wk-1=(a′,b′),满足如下条件:
因为不同长度的路径可能对应于不同规整距离D的长度,因此需对遍历路径进行归一化处理。计算各烧炉操作样本xi的局部密度ρi以及距离δi,公式如下:
δi定义为局部密度比xi大且距离最近的xj与xi的距离,其中dc是截断距离,将D进行升序排列,设得到序列D1≤D2≤…≤DM,式中:
dc=Df(Mt)
S33:确定预聚类中心,根据所述预聚类中心确定非预聚类样本的归类属性并对非预聚类中心的样本点进行归类。
选择ρ和δ都较大的样本定为类簇中心, 是各类别中心对应样本的编号,nc为类别个数。 表示排序后样本集中局部密度比xi大的数据点中与xi距离最近的样本编号,定义如下:
其中 表示降序排列下标,确定非聚类中心样本点的归类属性。
S34:提取预聚类中心样本数据和非预聚类样本数据中各烧炉阶段初始拱顶温度、初始烟气温度以及对应温升数据并计算欧式距离,根据欧式距离计算预聚类中心样本和非预聚类样本数的局部密度以及距离得到聚类中心以及对应类别的非中心样本从而获得所述优良烧炉炉次的聚类类别。
根据一次烧炉过程各燃烧阶段传热机理和操作工艺的不同,提取各阶段初始拱顶温度和初始烟气温度以及对应温升数据,对预聚类中心样本集和非预聚类样本集进行二级分类确定类别数Nc、类别中心 各非中心样本的归类属性。
聚类具体流程如下:
Step1:计算各样本之间的规整路径距离,设定用于确定截断距离dc的参数t∈(0,1),根据步骤3)计算dc,局部密度 和距离
Step2:确定聚类中心,并生成编号 确定该归类属性。
Step3:降序生成编号 对非聚类中心的样本点进行归类。
Step4:对预分类后的数据子集,提取各阶段初始拱顶温度和初始烟气温度以及对应温升数据并计算欧式距离进行上述聚类方法,得到最终聚类中心 以及对应类别的非中心样本。
优选地,综合评价指标的计算公式为:
其中 Li分别表示第i段的初始拱顶温度,拱顶温升、烟气温升、煤气用量;TG、ΔTY、L0分别为其相对应的期望值,设置TG、ΔTY、L0为第i段燃烧阶段所属类别中对应特征的统计平均值,a1、a2、a3为权重,且a1+a2+a3=1。综合评价指标越小,说明其指标越好,可根据指标将各炉次划分为优、良、中三个等级,其中优级的匹配优先级最高,中级的匹配优先级最低。
优选地,参见图4和图5,基于相似度衡量对当前工况与模式匹配空间进行分时段多级匹配包括以下步骤:
S51:采集高炉热风炉烧炉过程的当前状态参数,并基于聚类中心获得当前状态参数所属的聚类类别。
从现场获得工况数据之后,进行一级匹配。基于相似度衡量,从模式匹配空间获取与当前拱顶温度和烟气温度以及对应温变速率最匹配的类别中心,判断当前工况所属燃烧阶段。定义相似度指标:
是向量Pi和向量Pj的相似度,其范围在(0,1], 越靠近1,则说明向量Pi和向量Pj越相似。当 时,说明向量Pi和向量Pj一致。将相似度指标最大的类别中心Ci作为当前状态参数所属类别。
S52:在当前状态参数所属的聚类类别对应的模式匹配空间中,按匹配优先级类别逐一匹配获得匹配度最高的操作模式以及与操作模式对应的空燃比给定曲线。
得到所属工况类别后,进行二级匹配。根据各操作模式综合评价指标的优先级,在该类中逐一进行状态参数匹配,匹配优先级最高的操作模式优先匹配。若相似度低于设定阈值α,则得到当前工况下匹配度最高的操作模式以及对应空燃比给定曲线,否则,在下一优先级中逐一进行状态参数匹配,完成操作模式参数的优化。
其中,Ψ(Pi,t,Pj,t)是向量Pi,t和向量Pj,t的相似度,当Ψ(Pi,t,Pj,t)=0时,说明向量Pi,t和向量Pj,t一致。其中t为当前烧炉时间,uik,t为t时刻第k个参数,分别为拱顶温度、烟气温度、拱顶温变速率、烟气温变速率、煤气压力、空气压力、空燃比。
S53:定时采集高炉热风炉烧炉过程的状态参数,判断状态参数与已匹配操作模式的匹配相似度是否超出设定阈值,若未超出设定阈值,继续按照当前已获得空燃比给定曲线进行煤气阀门开度和空气阀门开度的设定,否则,重新搜索聚类中心选择聚类类别。
定时采集热风炉烧炉过程的实时参数,判断当前状态参数与已匹配操作模式的相似度是否超出设定阈值α。若未超出设定阈值,继续按照当前已获得空燃比给定曲线进行煤气阀门开度和空气阀门开度的设定,否则,重复一级匹配和二级匹配。最终获得各时段最佳空燃比设定值以及对应的煤气阀门开度和空气阀门开度,完成操作参数的优化。
综上可知,本发明基于采样数据以及热风炉工艺特点,挖掘优良烧炉炉次,采用密度峰值快速搜索聚类算法确定对复杂工况的类别,并根据综合评价指标划分样本优良等级,确立模式匹配空间,定时采集工况数据进行分时段多级匹配实现烧炉过程空燃比寻优的目的。本发明充分利用热风炉可检测到的工况数据,利用数据挖掘从海量历史数据中挖掘规律,有效地在实现节能和降低成本的目标上完成送入高炉热风的温度要求,对热风炉烧炉过程操作现场具有更好的指导作用,对实现热风炉自动烧炉意义重大。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
高炉热风炉烧炉过程操作参数分时段多级匹配寻优方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。





















动态评分
0.0