









专利摘要
一种基于DQN的云计算资源调度优化方法,所述方法包括:确认任务和目标并形成任务部署计划;记录服务器当前负载状态并部署计划至服务器的虚拟机上;记录任务部署后状态;形成第一回报值,形成第二回报值;统计多次的任务部署后的第一回报值形成第一回报集,统计多次的任务部署后的第二回报值形成第二回报集;将第一回报集及第二回报集分别进行归一化处理;根据能源消耗权重、时间权重、归一化后的第一回报集及归一化后的第二回报集计算得最终回报集;根据最终回报集中的元素形成样本加入至样本池。解决了如何形成基于DQN调度模型用于在特定云端服务器布置任务时平衡服务器能源消耗和任务完工时间的样本的问题。
权利要求
1.一种基于DQN的云计算资源调度优化方法,其特征在于,所述方法包括:
确认任务和目标网络的服务器负载状态并根据任务情况和目标网络的服务器负载状态形成任务部署计划;
记录服务器当前负载状态为起始状态并根据任务部署计划将任务部署至服务器的虚拟机上;
记录任务部署后的服务器的负载状态为完成状态;
根据完成状态计算任务完工时间并根据任务完工时间形成第一回报值,根据目标网络的起始状态与完成状态形成第二回报值;
统计多次的任务部署后的第一回报值形成第一回报集,统计多次的任务部署后的第二回报值形成第二回报集;
将第一回报集及第二回报集分别进行最小-最大值归一化处理;
根据能源消耗权重、时间权重、归一化后的第一回报集及归一化后的第二回报集计算得最终回报集,所述能源消耗权重为用于表示服务器负载状态变化导致的能源消耗在计算中的权重,所述时间权重为用于表示任务完工时间在计算中的权重;
根据最终回报集中的元素形成样本加入至样本池。
2.根据权利要求1所述的一种基于DQN的云计算资源调度优化方法,其特征在于,所述根据最终回报集中的元素形成样本加入至样本池的步骤具体包括:
分析最终回报集中的一个元素结合其所对应的起始状态、完成状态及任务部署计划形成参考样本;
对最终回报集中的所有元素逐个进行分析后将分析结果作为样本加入样本池。
3.根据权利要求1所述的一种基于DQN的云计算资源调度优化方法,其特征在于,所述根据完成状态计算任务完工时间并根据任务完工时间形成第一回报值的步骤具体包括:
根据完成状态计算任务部署所需的等待时间和执行任务所需的执行时间;
根据任务部署所需的等待时间及执行任务所需的执行时间的时间和的反比计算第一回报值。
4.根据权利要求1所述的一种基于DQN的云计算资源调度优化方法,其特征在于,所述根据目标网络的起始状态与完成状态形成第二回报值的步骤具体包括:
计算起始状态的服务器总能源消耗及完成状态的服务器总能源消耗;
将起始状态的服务器总能源消耗及完成状态的服务器总能源消耗的差值作为第二回报值。
5.根据权利要求4所述的一种基于DQN的云计算资源调度优化方法,其特征在于,所述服务器总能源消耗为服务器的静态能源消耗和服务器的动态能源消耗之和。
6.根据权利要求1所述的一种基于DQN的云计算资源调度优化方法,其特征在于,所述确认任务和目标网络的服务器负载状态并根据任务情况和目标网络的服务器负载状态形成任务部署计划的步骤具体包括:
获取任务并分析任务之间的依赖性;
采用粗粒度资源配置方式根据ε-greedy调度策略及任务之间的依赖性形成任务部署计划。
7.根据权利要求1所述的一种基于DQN的云计算资源调度优化方法,其特征在于,所述根据最终回报集中的元素形成样本加入至样本池的步骤后具体包括:
当样本池的样本数量累积至阈值后,从样本池中随机抽取Mini-batch个样本,采用随机梯度下降法更新在线网络参数;
在线网络参数每更新一定次数,便将在线网络参数赋值给目标网络参数。
说明书
技术领域
本发明涉及云计算领域,更具体地,涉及一种基于DQN的云计算资源调度优化方法。
背景技术
随着大数据时代的到来,云计算成为这个时代最具有活力与发展前景的一种计算服务模式。云计算不仅对信息产业技术架构产生重大影响,也不断的影响着人们的生活方式。在云计算快速发展的过程中同样也面对许多急需解决的问题,如提高用户的服务质量和提高云服务供应商的经济效益等问题。
从云计算的定义可知,资源管理调度问题仍是云计算领域亟需解决的核心问题之一。良好的资源管理与调度策略不仅能保证用户服务质量,而且能充分利用云系统的资源,增加云服务供应商的经济收益。云计算资源管理调度问题实际上是一种多约束、多目标优化的NP-hard问题。针对资源管理调度问题,国内外研究学者与课题组进行了大量的深入研究并取得丰硕的研究成果。
深度强化学习是一种结合深度学习与强化学习的新型的端对端(End to End,ETE)的感知与控制系统,通过结合深度学习的感知能力与强化学习的优秀的决策能力,优势互补,为解决复杂云系统的资源管理与任务调度问题提供了新的思路与方法。Mao等人将多资源作业调度问题转化成多资源任务装箱问题,把云资源和作业状态抽象为“图像”,来表示系统的状态空间。利用标准的深度策略梯度算法对模型进行训练,获得云环境下的多资源的作业调度模型。研究表明该策略能够适应复杂云环境,具有更强的适用性和通用性,性能方面优于大多经典的启发式算法,收敛性更好。Lin等人在此模型基础上,提出一种基于Deep Q network的多资源云作业调度模型,引入卷积神经网络CNN和递增的ε-greedy探索策略,实验结果表明该模型的收敛性更快,收敛效果更好。
但目前就如何基于DQN调度模型形成用于在特定云端服务器布置任务时平衡服务器能源消耗和任务完工时间的样本的问题目前仍没有太好的方法。
发明内容
本发明旨在克服上述现有技术问题,提供一种基于DQN的云计算资源调度优化方法,解决了如何形成基于DQN调度模型用于在特定云端服务器布置任务时平衡服务器能源消耗和任务完工时间的样本的问题。
一种基于DQN的云计算资源调度优化方法,所述方法包括:
确认任务和目标网络的服务器负载状态并根据任务情况和目标网络的服务器负载状态形成任务部署计划;
记录服务器当前负载状态为起始状态并根据任务部署计划将任务部署至服务器的虚拟机上;
记录任务部署后的服务器的负载状态为完成状态;
根据完成状态计算任务完工时间并根据任务完工时间形成第一回报值,根据目标网络的起始状态与完成状态形成第二回报值;
统计多次的任务部署后的第一回报值形成第一回报集,统计多次的任务部署后的第二回报值形成第二回报集;
将第一回报集及第二回报集分别进行最小-最大值归一化处理;
根据能源消耗权重、时间权重、归一化后的第一回报集及归一化后的第二回报集计算得最终回报集,所述能源消耗权重及时间权重为基于调整策略的能源消耗或时间因素的权重值;
根据最终回报集中的元素形成样本加入至样本池。
由于所述方法是针对于服务器能源消耗及任务完工时间的优化问题,因此将所述服务器能源消耗和任务完工时间作为因子,由于服务器能源消耗和任务完工时间的数值区间相差较大,因此使用最小-最大值归一化对其进行处理,最后便可得出用于在特定云端服务器布置任务时平衡服务器能源消耗和任务完工时间的样本。
优选的,所述通过最终回报集中的元素形成样本加入至样本池的步骤具体包括:
分析最终回报集中的一个元素结合其所对应的起始状态、完成状态及任务部署计划形成参考样本;
对最终回报集中的所有元素逐个进行分析后将分析结果作为样本加入样本池。
将通过最终回报集中的元素形成样本与服务器状态及任务的部署行为对应起来,避免了数据的散乱,在使用样本时提供了选取基础避免了选取混乱提升了样本的选取价值。
优选的,所述根据完成状态计算任务完工时间并根据任务完工时间形成第一回报值的步骤具体包括:
根据完成状态计算任务部署所需的等待时间和执行任务所需的执行时间;
根据任务部署所需的等待时间及执行任务所需的执行时间的时间和的反比计算第一回报值。
为达成偏向于最小化任务完工时间的优化目标,所述方法选择了任务部署所需的等待时间和执行任务所需的执行时间作为参考。
优选的,所述根据目标网络的起始状态与完成状态形成第二回报值的步骤具体包括:
计算起始状态的服务器总能源消耗及完成状态的服务器总能源消耗;
将起始状态的服务器总能源消耗及完成状态的服务器总能源消耗的差值作为第二回报值。
总能源消耗差值可用于表达服务器能源的优化效率,表达了所述任务部署的能源消耗价值。
优选的,所述服务器总能源消耗为服务器的静态能源消耗和服务器的动态能源消耗之和。
由于影响服务器的能源消耗差值变化的主要因素在于服务器非线性增长的动态能源消耗及服务器运转固定产生的静态能源消耗,因此通过平衡服务器的动态能源消耗和静态能源消耗便可控制服务器的总能源消耗。
优选的,所述获取任务并根据任务形成任务部署计划的步骤具体包括:
获取任务并分析任务之间的依赖性;
采用粗粒度资源配置方式根据ε-greedy调度策略及任务之间的依赖性形成任务部署计划。
使用粗粒度资源配置方式有益于优化零散任务的分配,避免了由于最后分配具有依赖性的任务而导致的服务的任务负载不均及导致的服务器的资源浪费。
优选的,所述根据最终回报集中的元素形成样本加入至样本池的步骤后具体包括:
当样本池的样本数量累积至阈值后,从样本池中随机抽取Mini-batch个样本,采用随机梯度下降法更新在线网络参数;
在线网络参数每更新一定次数,便将在线网络参数赋值给目标网络参数。
调节网络更新的频率以提升网络更新所产生的效益,通过随机梯度下降的方式更新在线网络参数可以降低在线网络参数的更新速度以及在一定程度上解决普通梯度下降法在更新过程中无法一定找到全局极小值的位置的问题。
与现有技术相比,本发明的有益效果为:
1.所述方法能够进行单目标优化,生成合理高效的资源配置与任务调度策略;
2.所述方法可以通过调整回报值权重,权衡能源消耗与任务完工时间这两个优化目标关系;
3.在具备足够多的样本数的情况下,基于DQN模型框架设计的算法相比于Random算法与RR算法在任务数较多的情况下,基于DQN模型框架设计的算法的总能源消耗更小,服务器的负载更加均衡;
4.在具备足够多的样本数的情况下,基于DQN模型框架设计的算法相比于Random算法与RR算法的平均任务完成时间明显缩短;
附图说明
图1为本方法的流程图。
图2为本方法的又一流程图。
图3为任务等待时间的示意图。
图4为服务器配置示意图。
图5为动态能耗与服务器资源利用率关系图。
图6为用户作业负载状态示意图。
图7为DQN训练模型参数表。
图8为不同权重α下任务完工时间与能源消耗的变化趋势图。
图9为不同权重α下任务完工时间与能源消耗的又一变化趋势图。
具体实施方式
本发明附图仅用于示例性说明,不能理解为对本发明的限制。为了更好说明以下实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
如图1至6所示,一种基于DQN的云计算资源调度优化方法,所述方法包括:
确认任务和目标网络的服务器负载状态并根据任务情况和目标网络的服务器负载状态形成任务部署计划;
记录服务器当前负载状态为起始状态并根据任务部署计划将任务部署至服务器的虚拟机上;
记录任务部署后的服务器的负载状态为完成状态;
根据完成状态计算任务完工时间并根据任务完工时间形成第一回报值,根据目标网络的起始状态与完成状态形成第二回报值;
统计多次的任务部署后的第一回报值形成第一回报集,统计多次的任务部署后的第二回报值形成第二回报集;
将第一回报集及第二回报集分别进行最小-最大值归一化处理;
根据能源消耗权重、时间权重、归一化后的第一回报集及归一化后的第二回报集计算得最终回报集,所述能源消耗权重及时间权重为基于调整策略的能源消耗或时间因素的权重值;
根据最终回报集中的元素形成样本加入至样本池。
由于所述方法是针对于服务器能源消耗及任务完工时间的优化问题,因此将所述服务器能源消耗和任务完工时间作为因子,由于服务器能源消耗和任务完工时间的数值区间相差较大,因此使用最小-最大值归一化对其进行处理,最后便可得出用于在特定云端服务器布置任务时平衡服务器能源消耗和任务完工时间的样本。
其中,所述方法将通过赋予不同目标回报函数不同的权重来权衡任务完工和能耗。数值表示对优化目标的偏重程度。由于两个目标的回报值存在数量级上差异,因此需要对两个目标的回报值先进行最小-最大值归一化处理,使得两个目标的回报值的值域均处于[0,1]。
设R为最终回报值,Rmakespan为用于表示任务完工时间的第一回报值,α为时间权重为用于表示任务完工时间在计算中的权重,Rp为用于表示服务器负载状态变化导致的能源消耗的第二回报值,(1-α)为能源消耗权重为用于表示服务器负载状态变化导致的能源消耗在计算中的权重,则:
R=α·Normal(Rmakespan)+(1-α)·Normal(RP),α∈[0,1]。
在具体实施过程中,所述通过最终回报集中的元素形成样本加入至样本池的步骤包括:
分析最终回报集中的一个元素结合其所对应的起始状态、完成状态及任务部署计划形成参考样本;
对最终回报集中的所有元素逐个进行分析后将分析结果作为样本加入样本池。
将通过最终回报集中的元素形成样本与服务器状态及任务的部署行为对应起来,避免了数据的散乱,在使用样本时提供了选取基础避免了选取混乱提升了样本的选取价值。
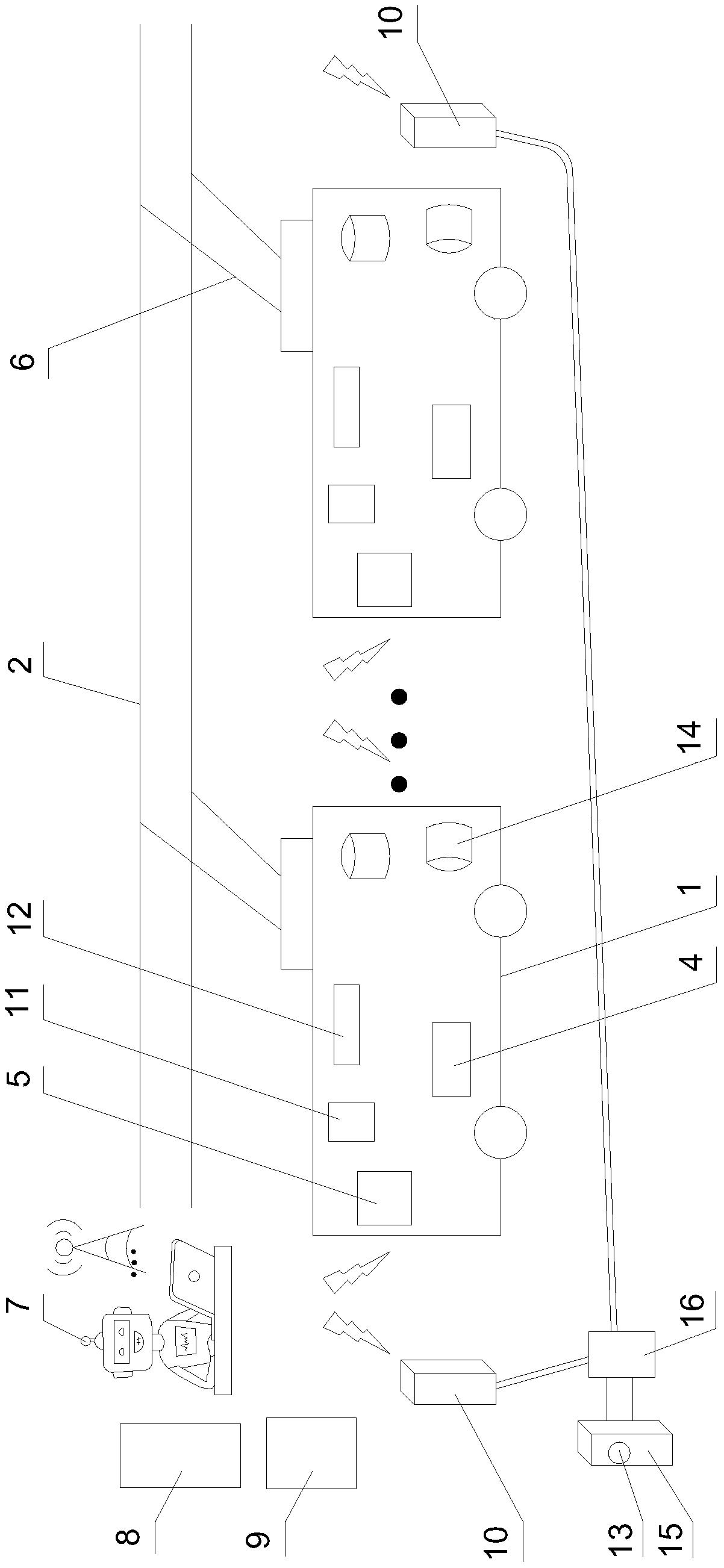
其中,假设有数据中心有X台物理服务器,表示为{S1,S2,...,Sx}。每个服务器的最大负载虚拟机数为 在时刻t服务器Sx上可用虚拟机数为 作业部署到服务器Sx需要等待的时间 则所述方法对应的模型的状态空间定义如下:
State:
则定义S:有限的环境状态集合,st∈S表示t时刻的状态;
在每个时间步为任务选择一个服务器进行部署,因此动作空间数为服务器数,所述方法对应的模型的动作空间表示为:
Action:{S1,S2,...,Sx};
则定义A:有限的动作集合,at∈A,表示t时刻选择的动作。
具体的,所述根据完成状态计算任务完工时间并根据任务完工时间形成第一回报值的步骤包括:
根据完成状态计算任务部署所需的等待时间和执行任务所需的执行时间;
根据任务部署所需的等待时间及执行任务所需的执行时间的时间和的反比计算第一回报值。
为达成偏向于最小化任务完工时间的优化目标,所述方法选择了任务部署所需的等待时间和执行任务所需的执行时间作为参考。
其中,如图3所示假设服务器的最大可负载3个虚拟机,任务1在t=0到达并部署在VM1上,执行时间Te=t1,等待时间Tw=0,任务2在时刻t0到达,此时任务2有两种调度选择,第一种是将任务2部署到VM1上,但是VM1仍被任务1所占用,所以任务2需要等待到t1才能部署到VM1,相应的等待时间为Tw=t1-t0。第二种是将任务2部署到VM2或是VM3上,无需等待,在t0时刻即可立即部署运行。因此对任务完工时间的定义为:
Tmakespan=Te+Tw;
其中,Te表示执行任务所需的执行时间,Tw表示任务部署所需的等待时间,则针对最小化任务完工时间优化目标的回报函数定义如下:
Rmakespan=1/Te+Tw。
其中,Rmakespan表示第一回报值。
具体的,所述根据目标网络的起始状态与完成状态形成第二回报值的步骤包括:
计算起始状态的服务器总能源消耗及完成状态的服务器总能源消耗;
将起始状态的服务器总能源消耗及完成状态的服务器总能源消耗的差值作为第二回报值。
总能源消耗差值可用于表达服务器能源的优化效率,表达了所述任务部署的能源消耗价值。
其中,针对最小化能耗优化目标,采用将当前时间步t的总能耗Ptotal(t)减去前一时间步t-1的总能耗Ptotal(t-1)来作为该时间步动作的价值。则所述第二回报值Rp的表达式为:
RP=Ptotal(t)-Ptotal(t-1)。
具体的,所述服务器总能源消耗为服务器的静态能源消耗和服务器的动态能源消耗之和。
由于影响服务器的能源消耗差值变化的主要因素在于服务器非线性增长的动态能源消耗及服务器运转固定产生的静态能源消耗,因此通过平衡服务器的动态能源消耗和静态能源消耗便可控制服务器的总能源消耗。
其中,假设数据中心有X台具有不同资源配置的服务器,表示为{S1,S2,...,Sx},服务器资源以虚拟机为单位,每台服务器具有不同最大负载虚拟机数。如图4所示,服务器具有两种状态(开启与关闭)。例如服务器S1处于开启状态,运行2个虚拟机。服务器S3则处于关闭状态,无运行虚拟机。
服务器Sx在t时刻的总能源消耗 包括静态能源消耗 与动态能源消耗 两者均取决服务器的资源利用率Ux(t)的大小。服务器的资源利用率定义为:
式中, 表示当前时刻t运行在服务器Sx的虚拟机数, 表示服务器Sx能够负载的最大虚拟机数。当Ux(t)>0时, 是一个常量,当Ux(t)=0时, 另一方面,动态能源消耗 与服务器的资源利用率Ux(t)之间存在复杂的关系。服务器Sx存在最优资源利用率 当 时,动态能源消耗 随服务器资源利用率Ux(t)线性增长,当 动态能源消耗 随服务器资源利用率Ux(t)非线性快速增长。因此,将动态能源消耗 定义为:
当参数设置为αx=0.5,βx=10, 不同的服务器资源利用率下的能源消耗如图5所示。
即t时刻的所有服务器的总能源消耗为:
若假设整个任务调度过程持续时间为T,则整个过程中服务器的总能源消耗为:
通过以上两个优化目标的定义可知,不同的调度策略会造成任务完工时间与能耗的不同。当优化目标偏向于最小化任务完工时间,采取的策略即是开启更多的服务器或是增加服务器的负载,尽可能减少任务的等待时间,因此会造成服务器资源浪费或是服务器负载过高,使得能源消耗增加。相反的,当优化目标偏向于最小化能源消耗,采取的策略是尽可能使得服务器的资源利用率处于最优利用率水平,使得全局的能耗最小化。
具体的,所述获取任务并根据任务形成任务部署计划的步骤包括:
获取任务并分析任务之间的依赖性;
采用粗粒度资源配置方式根据ε-greedy调度策略及任务之间的依赖性形成任务部署计划。
使用粗粒度资源配置方式有益于优化零散任务的分配,避免了由于最后分配具有依赖性的任务而导致的服务的任务负载不均及导致的服务器的资源浪费。
其中,本方法采用粗粒度资源配置方式,为每个任务配置满足其资源需求的虚拟机,每个服务器能部署负载多个虚拟机。每个用户作业负载U包含多个存在依赖性的子任务φ,作业负载模型可用一个有向无环图(Directed Acyclic Graphs,DAG)表示。如图6所示,图中结点 表示作业负载Um中的子任务φn,结点之间的有向边 表示作业负载Um中任务 与任务 之间的数据传输量以及传输方向。例如用户作业负载U1中,任务 必须在任务 完成执行与数据传输的情况才能被调度执行。因此,在整个云系统的任务调度与资源配置的过程中,首先需要对用户作业负载进行解耦,根据子任务之间的依赖性关系,将子任务调度到等待调度队列中,按照先来先服务的原则,为等待调度的任务配置虚拟机资源,执行任务。
具体的,所述根据最终回报集中的元素形成样本加入至样本池的步骤后包括:
当样本池的样本数量累积至阈值后,从样本池中随机抽取Mini-batch个样本,采用随机梯度下降法更新在线网络参数;
在线网络参数每更新一定次数,便将在线网络参数赋值给目标网络参数。
使用DQN模型的训练方式,调节网络更新的频率以提升网络更新所产生的效益,通过随机梯度下降的方式更新在线网络参数可以降低在线网络参数的更新速度以及在一定程度上解决普通梯度下降法在更新过程中无法一定找到全局极小值的位置的问题。
其中,在DQN训练模型过程中,智能体Agent通过不断试错与环境进行交互探索,根据在线网络生成的每个动作的Q值,采用递增的ε-greedy策略来选择动作,生成一系列的状态s、动作a及回报值r。目标是最大化期望累积折扣回报。模型中采用深度卷积网络来拟合最优的动作-值函数。
其中,E表示求参数的数学期望,s’表示在状态s选择动作a后进入到的下一个状态,a’表示下一个动作,行为策略π表示在状态s下选择动作a。在训练过程中,采用Mini-batch训练方法,每个训练回合均从经验池中随机选取M条经验,将状态s作为在线网络的输入,获得动作a的当前Q值,将下一状态st+1即s’作为目标网络的输入,获得目标网络中所有动作中的最大Q值,采用均分差(Mean-Square Error,MSE)来定义损失函数Li:
γ是折扣因子,决定着智能体Agent的视野,θi表示在第i次迭代的在线网络的参数, 是用来计算第i次迭代目标网络的参数。计算参数θ关于损失函数的梯度:
有了上面的梯度,而 可从神经网络中计算可得,因此,可使用随机梯度下降法(Stochastic Gradient Descent,SDG)来更新参数θ,从而获得最优的Q值。该网络参数采用延迟更新方法,每C个训练回合才将当前在线网络的参数值复制给目标网络,更新一次目标网络参数θ~。
实施例2
如图7至9所示,首先初始化在线网络参数θ、目标网络参数θ~以及经验样本池D。在训练过程中,每个时间步t,从任务队列中按照先来先服务的顺序调度任务,根据递增的ε-greedy调度策略选择动作at(即选择一个服务器),将任务部署到目标服务器,观察新的系统状态st+1并获得两个不同目标的回报值r1,r2。将(st,at,r1,r2,st+1)存储到临时列表中,直到任务队列中所有任务调度完成,该回合结束。将该回合的所获得回报值r1,r2进行归一化处理,根据权重值α,计算总回报值r,将样本(st,at,r,st+1)存储到经验样本池D中,当样本数达到设定阈值时,从样本池中随机抽取Mini-batch个样本,采用随机梯度下降法更新在线网络参数θ。每C个训练回合更新一次目标网络参数,将在线网络参数值θ赋值给目标网络参数θ~。
其中,DQN训练模型参数如图7所示。
图8和图9在不同权重下(α分别取0.8,0.6,0.4,0.2),任务完工时间与能源消耗的变化。其中,灰色曲线为实验数据,实心黑色曲线为实验数据平均值。从图8及图9中曲线的收敛结果可以明显看出通过调整不同目标回报函数的权重α,可以有效权衡任务完成时间与能源消耗。
显然,本发明的上述实施例仅仅是为清楚地说明本发明技术方案所作的举例,而并非是对本发明的具体实施方式的限定。凡在本发明权利要求书的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
一种基于DQN的云计算资源调度优化方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。










动态评分
0.0