








专利摘要
方法、系统和电路使用至少一个定义的进展风险数学模型对主体发展为2型糖尿病或者具有前驱糖尿病的风险进行评价,所述模型可以对具有相同葡萄糖测量结果的患者的风险进行分级。所述模型可以包括主体的至少一个生物样品的GlycA和多种选定脂蛋白分量的NMR衍生的测量结果。
权利要求
1.一种评价患者发展为2型糖尿病风险的方法,包括:
使用至少一个定义的发展为2型糖尿病的风险数学模型,以编程方式计算主体的糖尿病风险指数,所述模型包括得自主体的至少一个体外生物样品的至少一种脂蛋白分量的测量结果和至少一种(i) GlycA或GlycB或(ii)至少一种支链氨基酸的测量结果。
2.权利要求1的方法,其中一个或多个至少一种脂蛋白分量构成至少一个相互作用参数的分子、分母或乘数。
3.权利要求1的方法,其中定义的风险数学模型包含GlycA,其中至少一种脂蛋白分量包含通过GlycA测量结果乘以高密度脂蛋白(HDL)颗粒的定义亚群浓度定义的相互作用参数。
4.权利要求1的方法,其中定义的风险数学模型的至少一种脂蛋白分量包含GlycA测量结果乘以定义的高密度脂蛋白(HDL) 颗粒亚群浓度的第一相互作用参数,和HDL尺寸乘以定义的HDL亚群浓度的第二相互作用参数,其中HDL亚群仅包括直径在大约8.3 nm(平均)至大约10.0 nm(平均)之间的中等HDL颗粒亚类。
5.权利要求1的方法,进一步包括以编程方式定义至少两个不同的发展为2型糖尿病的风险数学模型,所述至少两个不同的数学模型包括一个用于正在进行他汀治疗的主体的包括至少一个对他汀不敏感的脂蛋白分量的模型,和一个用于未进行他汀治疗的主体的模型。
6.权利要求1的方法,进一步包括以编程方式定义至少两个不同的发展为2型糖尿病的风险数学模型,其中至少之一用于编程计算,所述至少两个不同的数学模型具有不同的脂蛋白分量,包括一种用于空腹生物样品的分量和一种用于非空腹生物样品的分量。
7.权利要求1的方法,进一步包括编程方式产生报告,所述报告具有在未来进展为2型糖尿病的风险相对于葡萄糖水平范围的图,其具有与计算的糖尿病风险指数相关的较高和较低风险值的可视指示,以便于鉴别或了解对于特定葡萄糖水平的风险分级。
8.权利要求1的方法,其中糖尿病风险指数是定义得分范围内的数值得分,所述方法进一步包括与电子装置的显示器连通的电子分析电路,配置所述装置以允许用户输入下列的一个或多个:(i)葡萄糖值,(ii)葡萄糖值和糖尿病风险指数得分,或(iii)糖尿病风险指数得分,且其中当所述葡萄糖值处于与空腹血浆葡萄糖水平在90-110 mg/dL之间,A1C %水平在5.7-6.4之间或口服葡萄糖耐量水平在140-199 mg/dL之间时相关联的中等风险范围时,糖尿病风险指数得分对具有相同葡萄糖值的患者的未来发展为2型糖尿病风险进行分级。
9.权利要求1的方法,其中至少一个定义的风险数学模型包括GlycA 和缬氨酸和至少一个包含高密度脂蛋白(HDL)颗粒亚群的相互作用参数的NMR衍生的测量结果。
10.权利要求1的方法,其中糖尿病风险指数是在定义得分范围内的数值得分,所述得分与人群基准的第九或第十十分位数、第四四分位数(4Q)或第五五分位数(5Q)相关联,反映相对于第一四分位数或第一五分位数(1Q)的增加的或高的发展为2型糖尿病风险。
11.权利要求1的方法,其中糖尿病风险指数是在定义的得分范围内的数值得分,独立于主体的葡萄糖测量结果而获得,所述方法进一步包括当糖尿病风险得分处于得分范围的高端和/或当得分与人群基准的第十十分位数、第四四分位数(4Q)或第五五分位数(5Q)相关联时,鉴别具有最高的增加的发展为2型糖尿病风险的相应主体。
12.权利要求1的方法,其中糖尿病风险指数是在定义的得分范围内的数值得分,或以人群基准的十分位数、四分位数或五分位数提供,所述方法进一步包括评价相应主体的葡萄糖水平,其中当空腹葡萄糖水平在90-110 mg/dL 之间、A1C %水平在5.7-6.4之间或口服葡萄糖耐量水平在140-199 mg/dL之间时,并且当糖尿病风险指数得分在与得分范围的高端相关联的人群基准的第四四分位数(4Q)、第五五分位数(5Q)或第十十分位数中时,主体具有增加的发展为糖尿病的风险。
13.权利要求1的方法,其中糖尿病风险指数是在定义的得分范围内的数值得分,所述得分与人群基准的第四四分位数(4Q)、第五五分位数(5Q)或第十十分位数相关,反映增加的或高的发展为2型糖尿病风险,且其中当所述葡萄糖值在当空腹血浆葡萄糖水平在90-110 mg/dL之间,A1C %水平在5.7-6.4之间或口服葡萄糖耐量水平在140-199 mg/dL之间时与之相关联的中等风险范围内时,糖尿病风险指数得分对具有相同葡萄糖值的患者的未来发展为2型糖尿病风险进行分级。
14.权利要求1的方法,其中定义的数学风险模型仅包括各个主体的至少一个体外血浆或血清生物样品的NMR衍生的测量结果。
15.权利要求1的方法,进一步包括,在编程计算之前,
将主体的体外生物样品置于NMR谱仪中;
获得所述生物样品的至少一个NMR谱;
对所获得的至少一个NMR谱进行去卷积;以及
基于去卷积的至少一个NMR谱计算GlycA和多个选定脂蛋白亚类的NMR衍生的测量结果。
16.权利要求15的方法,进一步包括计算作为支链氨基酸之一或仅有的支链氨基酸的缬氨酸测量结果。
17.权利要求1的方法,其中所述至少一个定义的数学模型包括选定的脂蛋白分量,其包括至少下述之二:(i)定义的中等尺寸高密度脂蛋白(HDL)颗粒亚群的浓度,其具有直径在8.3 nm(平均) 至大约10.0 nm(平均)之间的HDL颗粒亚类;(ii)相互作用参数定义的HDL尺寸乘以中等定义的HDL亚群浓度;(iii) 通过中等HDL亚群浓度乘以GlycA定义的相互作用参数;(iv)脂蛋白胰岛素抗性指数;(v)大VLDL亚类颗粒数量;(vi)中等VLDL亚类颗粒数量;(vii)总HDL亚类颗粒数量;(viii)中等HDL亚类颗粒数量;和(ix) VLDL颗粒尺寸。
18.权利要求17的方法,其中选定的脂蛋白分量包括所列脂蛋白分量的(i)-(iv)。
19.权利要求1的方法,其中至少一个定义的数学模型的至少一种脂蛋白分量的至少之一包括下列的一种或多种:VLDL亚类颗粒尺寸 (vsz3)、中等HDL-P对总HDL-P的比值 (HMP_HDLP)乘以GlycA和VLDL尺寸对大VLDL-P和中等VLDL-P的总和的比值。
20.权利要求1的方法,其中所述至少一种脂蛋白分量包含至少一个相互作用参数,其包括高密度脂蛋白(HDL)颗粒亚群的浓度作为比值的乘数或分子或分母。
21.权利要求1的方法,进一步包括,在编程计算之前:以电子方式获得主体的生物样品的GlycA拟合区域的复合NMR谱,其中GlycA拟合区域从1.845 ppm延伸至2.080 ppm,并且其中GlycA峰区域的中心位于2.00 ppm;
使用定义的去卷积模型和与至少GlycA峰区域相关联的曲线拟合函数对复合NMR谱以电子方式进行去卷积,所述定义的去卷积模型具有高密度脂蛋白(HDL)分量、低密度脂蛋白(LDL)分量、VLDL(极低密度脂蛋白)/乳糜微粒分量;以及
使用曲线拟合函数以编程方式产生GlycA的测量结果。
22.权利要求21的方法,进一步包括在糖尿病风险指数的编程计算之前,以电子方式对GlycA测量结果应用换算系数以提供以μmol/L为单位的测量结果。
23.权利要求21的方法,其中曲线拟合函数是重叠曲线拟合函数,且其中通过将定义数量的曲线拟合函数加和来产生GlycA的测量结果,并且其中去卷积模型进一步包含密度大于1.21 g/L的蛋白质的蛋白质信号分量。
24.权利要求1的方法,进一步包括,在编程计算之前:
以电子方式获得主体的生物样品的支链氨基酸拟合区域的NMR谱;
以电子方式鉴别缬氨酸信号为位于生物样品中定义稀释剂的参考峰的上游或下游;
使用定义的去卷积模型对复合NMR谱以电子方式进行去卷积;
在获得步骤期间评价参考峰的线宽;
使用去卷积的NMR谱对缬氨酸以电子方式进行定量;以及
使用基于与用于获得NMR谱的NMR谱仪的匀场状态相关联的参考峰线宽的调整系数以电子方式校正对缬氨酸的定量。
25.权利要求1的方法,其中至少一个定义的风险数学模型包括多个不同的定义的模型,包括一个包括对他汀治疗不敏感的脂蛋白分量的模型,一个包括对他汀治疗敏感的脂蛋白分量的模型,一个用于空腹生物样品的模型和一个用于非空腹生物样品的模型。
26.被配置以确定患者是否具有发展为2型糖尿病风险和/或患者是否具有前驱糖尿病的电路,包括:
至少一个处理器,所述处理器被配置以基于至少一个趋同为2型糖尿病的风险数学模型以电子方式计算糖尿病风险指数,所述数学模型考虑来自主体的至少一个体外生物样品的至少一种脂蛋白分量的测量结果,和(i)至少一种支链氨基酸或GlycA或者(ii) 至少一种支链氨基酸和GlycA的测量结果。
27.权利要求26的电路,其中糖尿病风险指数是定义得分范围内的数值得分,并且其中所述电路与电子分析电路连通或者与电子分析电路一起配置,所述电子分析电路与远程电子装置的各个显示器连通,配置所述远程电子装置以允许用户输入(i)葡萄糖值,(ii)葡萄糖值和糖尿病风险指数得分,或(iii)糖尿病风险指数得分,且其中当所述葡萄糖值处于与当空腹血浆葡萄糖水平在90-110 mg/dL之间,A1C %水平在5.7-6.4之间或口服葡萄糖耐量水平在140-199 mg/dL之间时相关联的中等风险范围内时,配置所述电路以使用患者的相应葡萄糖值和糖尿病风险指数得分对具有相同葡萄糖值的患者的未来发展为2型糖尿病风险进行分级。
28.权利要求26的电路,其中至少一个风险数学模型包括GlycA的测量结果以及缬氨酸的NMR测量结果,其中缬氨酸作为至少一种支链氨基酸,且其中至少一种脂蛋白分量包括至少一个相互作用参数,所述相互作用参数包含高密度脂蛋白(HDL)颗粒亚群的浓度。
29.权利要求26的电路,其中定义的风险数学模型包含GlycA,且其中至少一个脂蛋白分量包含GlycA测量结果乘以定义的高密度脂蛋白(HDL)颗粒亚群浓度的相互作用参数。
30.权利要求26的电路,其中定义的风险数学模型的至少一种脂蛋白分量包含GlycA测量结果乘以定义的高密度脂蛋白(HDL) 颗粒亚群浓度的第一相互作用参数,和HDL尺寸乘以定义的HDL亚群浓度的第二相互作用参数。
31.权利要求29或30的电路,其中定义的HDL亚群仅包括直径在8.3 nm(平均)至大约10.0 nm(平均)之间的中等HDL颗粒亚类。
32.权利要求26的电路,其中配置所述至少一个处理器以定义至少两个不同的发展为2型糖尿病的风险数学模型,所述至少两个不同的数学模型包括一个用于正在进行他汀治疗的主体的包括对他汀不敏感的脂蛋白分量的第一模型,和一个用于未进行他汀治疗的主体的第二模型,其中所述第二模型包括至少一些与第一模型不同的脂蛋白分量,且其中配置所述电路以鉴别主体和/或生物样品特征,以选择合适的第一或第二风险模型,用于计算糖尿病风险指数得分。
33.权利要求26的电路,其中配置至少一个处理器以定义至少两个具有不同的脂蛋白分量的不同的发展为2型糖尿病风险数学模型,所述至少两个不同的数学模型包括一个用于空腹生物样品的模型,和一个用于非空腹生物样品的模型,且其中所述电路鉴别主体和/或生物样品特征,以选择合适的用于计算糖尿病风险指数得分的数学模型。
34.权利要求26的电路,其中配置至少一个处理器以产生作为定义范围内的数值得分的糖尿病风险指数,其中处于尺度高端的得分代表增加的风险,且其中配置至少一个处理器以产生报告,所述报告具有在未来进展为2型糖尿病风险相对于葡萄糖水平的范围和与糖尿病风险指数得分相关联的风险比较尺度的图。
35.权利要求34的电路,其中所述图包括基于定义人群的,至少与DRI得分的第一四分位数、第一五分位数或第一十分位数相关联的相对低风险的DRI得分,和与DRI得分的第四四分位数、第五五分位数或第十十分位数相关联的高风险DRI得分的可视化参考,由此允许易于鉴别或了解风险分级。
36.权利要求26的电路,其中配置至少一个处理器以评价主体的血糖测量结果,其中糖尿病风险指数得分是在定义的得分范围内的数值得分,所述得分与人群基准的第四四分位数(4Q)、第五四分位数(5Q)或第十十分位数相关联,反映出增加的和/或高的发展为2型糖尿病风险,且其中配置至少一个处理器以产生报告,所述报告可以对具有相同葡萄糖测量结果和不同糖尿病风险得分的主体中的风险进行分级。
37.权利要求26的电路,其中至少一个定义的数学模型包括选定的脂蛋白分量,其包括至少下述之二:(i)定义的中等尺寸高密度脂蛋白(HDL)颗粒亚群的浓度,其具有直径在8.3 nm(平均) 至大约10.0 nm(平均)之间的HDL颗粒亚类;(ii)相互作用参数定义的HDL尺寸乘以中等定义的HDL亚群浓度;(iii) 通过中等HDL亚群浓度乘以GlycA定义的相互作用参数;(iv)脂蛋白胰岛素抗性指数;(v)大VLDL亚类颗粒数量;(vi)中等VLDL亚类颗粒数量;(vii)总HDL亚类颗粒数量;(viii)中等HDL亚类颗粒数量;和(ix) VLDL颗粒尺寸。
38.权利要求37的电路,其中数学模型包括所列脂蛋白分量的所有分量(i)-(iv)。
39.权利要求37的电路,其中数学模型的脂蛋白分量之一是中等HDL-P对总HDL-P的比值。
40.权利要求26的电路,其中所述至少一个数学模型包括多种脂蛋白分量,包括VLDL亚类颗粒尺寸 (vsz3)、中等HDL-P对总HDL-P的比值 (HMP_HDLP)乘以GlycA和VLDL尺寸对大VLDL-P和中等VLDL-P的总和的比值。
41.一种用于评价体外患者生物样品的计算机程序产品,所述计算机程序产品包括:
永久性计算机可读存储介质,其具有存储在介质中的计算机可读程序代码,所述计算机可读程序代码包含:
提供至少一个在未来进展为2型糖尿病的风险数学模型的计算机可读程序代码,其中至少一个进展为2型糖尿病的风险数学模型包括多种分量,包括至少一种脂蛋白分量,至少一种炎性生物标志物和至少一种支链氨基酸;以及
基于至少一个发展为2型糖尿病的风险数学模型计算与患者的生物样品相关联的糖尿病风险指数的计算机可读程序代码。
42.权利要求41的计算机程序产品,其中提供至少一个数学模型的计算机可读程序代码包括作为炎性标志物的GlycA以及作为至少一种支链氨基酸的缬氨酸的NMR衍生的测量结果的模型分量。
43.权利要求41的计算机程序产品,其中至少一个风险数学模型包括作为至少一种炎性标志物的GlycA、作为至少一种支链氨基酸的缬氨酸以及作为至少一种脂蛋白分量的一种或多种的至少一个相互作用参数的NMR衍生的测量结果,其中至少一个相互作用参数包含高密度脂蛋白(HDL)颗粒亚群浓度。
44.权利要求41的计算机程序产品,其中定义的风险数学模型包含GlycA 作为炎性生物标志物,且其中至少一种脂蛋白分量包括GlycA测量结果乘以定义的高密度脂蛋白(HDL)颗粒亚群浓度的相互作用参数。
45.权利要求41的计算机程序产品,其中至少一种脂蛋白分量包括GlycA测量结果乘以定义的高密度脂蛋白(HDL)颗粒亚群浓度的相互作用参数,和HDL尺寸乘以定义的HDL亚群浓度的第二相互作用参数。
46.权利要求44或45的计算机程序产品,其中定义的HDL亚群仅包括直径在8.3 nm(平均)至大约10.0 nm(平均)之间的中等HDL颗粒亚类。
47.权利要求41的计算机程序产品,进一步包含被配置以评价患者的葡萄糖测量结果的计算机可读程序代码,其中所述计算机可读程序代码将糖尿病风险指数计算为在定义的得分范围内的数值得分,所述得分与人群基准的第四四分位数(4Q)、第五五分位数(5Q)或第十十分位数相关联,反映增加的或高的发展为2型糖尿病的风险。
48.权利要求47的计算机程序产品,其中所述计算机程序产品进一步包括计算机可读程序代码,所述计算机可读程序代码被配置为当:(i)空腹血糖水平在90-110 mg/dL之间或者当A1C %水平在5.7-6.4之间或者当口服葡萄糖耐量水平在140-199 mg/dL之间并且(ii)糖尿病风险得分在4Q、5Q或第十十分位数范围内时,鉴别具有增加的发展为2型糖尿病风险的相应患者。
49.权利要求41的计算机程序产品,其中至少一个定义的数学模型包括选定的脂蛋白分量,其包括至少下述之二:(i)定义的中等尺寸高密度脂蛋白(HDL)颗粒亚群的浓度,其具有直径在8.3 nm(平均) 至大约10.0 nm(平均)之间的HDL颗粒亚类;(ii)相互作用参数定义的HDL尺寸乘以中等定义的HDL亚群的浓度; (iii) 通过中等HDL亚群浓度乘以GlycA定义的相互作用参数;(iv)脂蛋白胰岛素抗性指数;(v)大VLDL亚类颗粒数量;(vi)中等VLDL亚类颗粒数量;(vii)总HDL亚类颗粒数量;(viii)中等HDL亚类颗粒数量;和(ix) VLDL颗粒尺寸。
50.权利要求49的计算机程序产品,其中所述数学模型包括所列脂蛋白分量的分量(i)-(iv)。
51.权利要求41的计算机程序产品,其中所述数学模型包括中等HDL-P对总HDL-P的比值。
52.权利要求41的计算机程序产品,其中所述至少一个数学模型包括多种脂蛋白分量,包括VLDL亚类颗粒尺寸 (vsz3)、中等HDL-P对总HDL-P的比值 (HMP_HDLP)乘以GlycA和VLDL尺寸对大VLDL-P和中等VLDL-P的总和的比值。
53.权利要求41的计算机程序产品,进一步包含:
鉴别并对主体的血清或血浆样品的复合NMR谱的缬氨酸拟合区域进行去卷积,并产生计算的缬氨酸测量结果的计算机可读程序代码;以及
对复合NMR谱的GlycA拟合区域进行去卷积的计算机可读程序代码,其中所述对复合NMR谱进行去卷积的计算机可读程序代码使用具有(i)高密度脂蛋白(HDL)分量,(ii)低密度脂蛋白(LDL)分量,(iii)VLDL(极低密度脂蛋白)/乳糜微粒分量,(iv)另一种定义的蛋白质信号分量和(v)应用于至少一个GlycA峰区域的曲线拟合函数的定义的GlycA去卷积模型,并产生计算的GlycA测量结果。
54.系统,包含:
用于获得体外生物样品的至少一个NMR谱的NMR谱仪;和
至少一个与NMR谱仪连通的处理器,配置至少一个处理器以基于至少一个定义的趋同为2型糖尿病风险数学模型,使用所获得的至少一个NMR谱确定各个生物样品的糖尿病风险指数,所述数学模型包括从主体的至少一个体外生物样品获得的至少一种脂蛋白分量、至少一种支链氨基酸和至少一种炎性生物标志物。
55.权利要求54的系统,其中配置所述至少一个处理器以对获得的至少一个NMR谱进行去卷积并产生:(i)作为至少一种炎性生物标志物的GlycA的NMR测量结果;(ii)作为至少一种支链氨基酸的缬氨酸的NMR测量结果;以及(iii)脂蛋白亚类的NMR测量结果,并且其中至少一个处理器使用GlycA、缬氨酸和至少一种脂蛋白分量作为至少一个定义的数学模型的分量,计算糖尿病风险指数得分作为定义范围内的数值得分。
56.权利要求54的系统,其中定义的风险数学模型包含GlycA 作为炎性生物标志物,且其中至少一种脂蛋白分量包括具有定义的高密度脂蛋白(HDL)亚类浓度或HDL颗粒尺寸作为数学比值或乘积的分量的相互作用参数。
57.权利要求54的系统,其中至少一种脂蛋白分量包含相互作用参数,GlycA和定义的高密度脂蛋白(HDL)颗粒亚群浓度的相乘系数(multiplied factor)。
58.权利要求54的系统,其中定义的风险数学模型的至少一种脂蛋白分量包含GlycA测量结果乘以定义的高密度脂蛋白(HDL) 颗粒亚群浓度的第一相互作用参数,和HDL尺寸乘以定义的HDL亚群浓度的第二相互作用参数。
59.权利要求57或58的系统,其中所述系统计算定义的HDL亚群的浓度,且其中HDL亚群仅包含直径在8.3 nm(平均)至10.0 nm(平均)之间的中等HDL颗粒亚类。
60.权利要求54的系统,其中配置至少一个处理器以定义至少两个不同的发展为2型糖尿病的风险数学模型,所述至少两个不同的数学模型包括一个用于正在进行他汀治疗的主体的包括对他汀不敏感的脂蛋白分量的模型,和一个用于未进行他汀治疗的主体的具有至少一种不同的脂蛋白分量的模型。
61.权利要求54的系统,其中配置至少一个处理器以定义至少两个不同的具有不同脂蛋白分量的发展为2型糖尿病的风险数学模型,所述至少两个不同的数学模型,包括一个用于空腹生物样品的模型和一个用于非空腹生物样品的模型。
62.权利要求54的系统,其中配置至少一个处理器以产生报告,所述报告具有在未来进展为2型糖尿病风险相对于葡萄糖水平和基于与糖尿病风险指数得分相关联的人群基准的四分位数、五分位数或十分位数的图。
63.权利要求62的系统,其中所述图包括基于定义的人群的至少第一(低)和第四四分位数或第五五分位数或第十十分位数(高)DRI得分的可视化参考,由此允许易于鉴别或了解风险分级。
64.权利要求54的系统,其中所述定义的至少一个数学模型包括从体外血浆或血清生物样品测量的GlycA和使用脂蛋白亚类、尺寸和浓度的多种选定脂蛋白分量的NMR测量结果。
65.权利要求54的系统,其中至少一个定义的数学模型包括选定的脂蛋白分量,其包括至少下述之二:(i)定义的中等尺寸高密度脂蛋白(HDL)颗粒亚群的浓度,其具有直径在8.3 nm(平均) 至大约10.0 nm(平均)之间的HDL颗粒亚类;(ii)相互作用参数定义的HDL尺寸乘以中等定义的HDL亚群浓度;(iii)通过中等HDL亚群浓度乘以GlycA定义的相互作用参数;(iv)脂蛋白胰岛素抗性指数;(v)大VLDL亚类颗粒数量;(vi)中等VLDL亚类颗粒数量;(vii)总HDL亚类颗粒数量;(viii)中等HDL亚类颗粒数量;和(ix) VLDL颗粒尺寸。
66.权利要求65的系统,其中选定的脂蛋白分量包括所列脂蛋白分量的(i)-(iv)项。
67.权利要求54的系统,其中至少一种脂蛋白分量包括至少下述之一:VLDL亚类颗粒尺寸 (vsz3)、中等HDL-P对总HDL-P的比值 (HMP_HDLP)乘以GlycA和VLDL尺寸对大VLDL-P和中等VLDL-P的总和的比值。
68.患者报告,其包含:
基于定义的进展为2型糖尿病风险数学模型计算的糖尿病风险指数 (DRI)得分,其中所述模型包括GlycA和至少一种脂蛋白分量的测量结果,并且得分与相对于第一四分位数、五分位数或十分位数而言与较高风险相关的人群基准的第四四分位数、第五五分位数或第十十分位数相关联。
69.权利要求68的报告,进一步包含显示糖尿病转变风险范围相对于葡萄糖水平的图,其中对于各个葡萄糖水平,不同的DRI得分定义不同的风险水平,提供可视化风险分级信息。
70.权利要求68的报告,进一步包含阐释相对风险分级的条形图或曲线图,所述相对风险分级阐释对于相同葡萄糖水平的不同DRI得分的不同风险水平,且所述条形图或曲线图包括当空腹血浆葡萄糖水平在90-110 mg/dL之间,A1C %水平在5.7-6.4之间或口服葡萄糖耐量水平在140-199 mg/dL之间时,与之相关联的葡萄糖的中等风险范围。
71.一种NMR系统,其包含:
NMR谱仪;
与谱仪连通的流量探针;和
至少一个与谱仪连通的处理器,所述谱仪被配置以获得 (i)与流量探针中的血浆或血清样品的GlycA相关联的NMR谱的定义的GlycA拟合区域的NMR信号;(ii) 流量探针中的样品相关联的NMR谱的定义的支链氨基酸拟合区域的NMR信号;和(iii)脂蛋白亚类的NMR信号;
其中至少一个处理器被配置以使用NMR信号计算 (i) GlycA,(ii)至少一种支链氨基酸和(iii) 脂蛋白亚类的测量结果,且其中至少一个处理器被配置以计算糖尿病风险指数,所述糖尿病风险指数使用计算的GlycA、至少一种支链氨基酸和一些脂蛋白亚类的测量结果。
72.权利要求71的系统,其中所述至少一个处理器包含至少一个本地或远程处理器,其中所述至少一个处理器被配置以计算至少一个相互作用参数。
73.权利要求71的系统,其中所述至少一个相互作用参数包括通过GlycA测量结果乘以定义的高密度脂蛋白(HDL) 颗粒亚群浓度定义的第一相互作用参数。
74.权利要求71的系统,其中所述至少一个处理器计算GlycA测量结果乘以定义的高密度脂蛋白(HDL) 颗粒亚群浓度的第一相互作用参数,和HDL尺寸乘以定义的HDL亚群浓度的第二相互作用参数。
75.权利要求71的系统,其中对于至少一个相互作用参数,至少一个处理器使用HDL亚类计算定义的HDL亚群浓度,其中HDL亚群仅包含直径在8.3 nm(平均)至大约10.0 nm(平均)之间的中等HDL颗粒亚类。
76.权利要求71的系统,其中至少一种支链氨基酸包含缬氨酸。
77.监测患者以评价治疗或确定患者是否具有发展为2型糖尿病风险的方法,包括:
以编程方式评价至少一个患者体外生物样品的选定的脂蛋白亚类和至少下列之一的多个NMR衍生的测量结果:(i) 至少一种支链氨基酸或GlycA或者(ii) 至少一种支链氨基酸和GlycA;
使用NMR衍生的测量结果,以编程方式计算各个患者的糖尿病风险指数;和
评价下述至少之一:(i)糖尿病风险指数是否高于与增加的发展为2型糖尿病相关联的人群基准的定义水平;和/或(ii) 糖尿病风险指数是否随着时间升高或降低,由此评价可对治疗应答的风险状态的变化。
说明书
相关申请
本申请要求2012年6月8日提交的美国临时申请序列号61/657,315、2012年10月9日提交的美国临时申请序列号61/711,471、2012年12月19日提交的美国临时申请序列号61/739,305、和2013年3月14日提交的美国专利申请序列号13/830,784的利益和优先权,通过引用将它们的内容合并入文本,如同在本文中描述其全文。
发明领域
本发明一般地涉及体外生物样品的分析。本发明可特别适用于体外生物样品的NMR分析。
发明背景
在美国和其它国家,2型糖尿病(T2DM或“糖尿病”)是花费最多和负担最重的慢性病之一。T2DM的明显特征是高血糖症,其反映出由于胰岛素分泌反应缺陷或不足导致的受损的碳水化合物(葡萄糖)利用。T2DM是多年前开始的代谢紊乱的晚期表现。认为其原因是胰岛素抗性的进行性增加结合β-细胞功能退化。只要胰腺β-细胞能够分泌足够的胰岛素来补偿靶组织对胰岛素降血糖作用的进行性抗性,患者就能够维持正常的空腹血糖水平。高血糖症和向T2DM的转变是进行性β-细胞功能紊乱的结果,β-细胞功能紊乱导致在面对增加的胰岛素抗性时,难以维持胰岛素的高分泌。
传统上通过检测血液中升高水平的葡萄糖(糖)来诊断2型糖尿病(高血糖症)。虽然高血糖症定义糖尿病,但它在由胰岛素抗性通向完全的糖尿病的一系列事件中是非常晚期的发展。相应地,有一种在发生典型症状,例如高血糖症之前鉴别主体是否具有发展成2型糖尿病的风险(即有该状况的倾向)的方法是合乎需要的。对该疾病指标的早期检测(例如在葡萄糖水平升高到足以被认为是高血糖症之前检测)可以更有效地治疗该疾病,即使没有实际预防该疾病的发生。
评估胰岛素抗性的最直接和准确的方法是费力且耗时间的,因此对于临床应用来说是不实用的。这些研究方法中的“金标准”是高胰岛素正糖钳,其在钳夹期间对最大葡萄糖代谢清除率(GDR,与胰岛素抗性成反比)进行定量测定。另一种再现性稍差(CV 14-30%)的费力的研究方法是具有最小模型分析的频繁静脉取样的葡萄糖耐量测试(IVGTT),其测量胰岛素敏感性(Si),胰岛素抗性的倒数。
目前主要通过空腹葡萄糖评估2型糖尿病的进展风险,浓度100-125 mg/dL定义高风险的“前驱糖尿病”状况,并且因此,目前在具有126 mg/dL 或更高的空腹血浆葡萄糖水平的患者中定义T2DM。但是,具有前驱糖尿病的个体患者(那些具有最大的在不久的将来发展为T2DM风险的患者)的实际风险差别很大。
NMR谱已用于同时测量作为来自体外血浆或血清样品的LDL、HDL和VLDL颗粒亚类的低密度脂蛋白(LDL)、高密度脂蛋白(HDL)、和极低密度脂蛋白(VLDL)。参见,美国专利号4,933,844和6,617,167,通过引用将其内容合并入本文,如同在本文中描述其全文。Otvos等的美国专利号6,518,069描述了对葡萄糖和/或特定脂蛋白值的NMR衍生的测量结果,以评估患者发展为T2DM的风险。
通常来说,为了评价血浆和/或血清样品中的脂蛋白,通过对复合甲基信号包络(composite methyl signal envelope)的去卷积获得NMR谱的化学位移区域内的多个NMR谱衍生信号幅度,以产生亚类浓度。亚类由多个(通常超过60个)与NMR频率和脂蛋白直径相关联的不连续的贡献亚类信号代表。NMR评价可以探查(interrogate)NMR信号以产生不同亚群,典型地是73个不连续亚群的浓度,其中27个是VLDL,20个是LDL且26个是HDL。这些亚群可以进一步描述为与VLDL、LDL或HDL亚类中的特定尺寸范围相关联。
高级脂蛋白试验组(panel),例如可从LipoScience, Raleigh, N.C.获得的LIPOPROFILE?脂蛋白测试,典型地包括将所有HDL亚类的浓度加和的总高密度脂蛋白颗粒(HDL-P)的测量结果(例如HDL-P数量),和将所有LDL亚类的浓度加和的总低密度脂蛋白颗粒(LDL-P)的测量结果(例如LDL-P数量)。LDL-P和HDL-P数量代表那些相应的颗粒的浓度,以浓度单位例如nmol/L表示。LipoScience还开发了一种基于脂蛋白的胰岛素抗性和敏感性指数(“LP-IR?”指数),如美国专利号8,386,187所述,通过引用将其内容合并入本文,如同在本文中描述其全文。
尽管如上文所述,仍然需要有能够在发生该疾病之前可以预测或评估一个人发展为2型糖尿病的评价。
发明内容
本发明的实施方案提供使用定义的预测生物标志物的多参数(多变量)模型对患者在未来发展为2型糖尿病的风险的风险评估。
风险评估可以产生糖尿病风险指数得分,其对单独的葡萄糖测量结果之外的风险进行分级,并可以与葡萄糖测量结果分离。葡萄糖测量结果,如果使用的话,可以帮助建立向2型糖尿病转变的时间线。当不与葡萄糖信息一起使用时,糖尿病风险指数得分可以反映出与基础代谢问题相关联的较长的时期中的风险 。
多变量风险进展模型可以包括至少一种定义的脂蛋白分量,至少一种定义的支链氨基酸和至少一种炎性生物标志物。
多变量模型可用于为临床试验的目的或在临床实验期间、在治疗(therapy)或治疗(therapies)期间、为药物开发的目的、和/或为鉴别或监测抗肥胖药物或其它药物治疗候选物的目的对患者进行评估。
多变量模型可以包括至少下述之一:GlycA、缬氨酸和衍生自同一个NMR谱的多种脂蛋白分量(例如亚类)的NMR测量结果。
所定义的风险数学模型的至少一种脂蛋白分量可以包括第一相互作用参数,其是GlycA的测量结果乘以定义的高密度脂蛋白(HDL) 颗粒亚群的浓度。该模型还可以包括或者作为一种替代方式包括第二相互作用参数,其是HDL尺寸乘以定义的HDL亚群的浓度。
HDL亚群可以仅包括直径在大约8.3 nm(平均)至大约10.0 nm(平均)之间的中等HDL颗粒亚群。
本发明的实施方案包括方法、电路(circuits)、NMR谱仪或NMR分析仪、和处理器,使用定义的多分量风险进展模型通过评价体外血浆或血清患者样品的NMR谱,来为那些具有“前驱糖尿病”的人评价发展为糖尿病的未来风险和/或风险分级。
对于GlycA,NMR信号可以具有中心在大约2.00 ppm的峰。
可以使用风险的数学模型计算糖尿病风险指数,该模型产生代表将来发展成2型糖尿病风险的单个得分,其在反映大约0-80%或0-100%的风险的数字的数值范围内。
糖尿病风险指数可以包括脂蛋白分量和GlycA和缬氨酸的至少一种。
脂蛋白分量可以包括(i)中等相对于总高密度脂蛋白颗粒 (HDL-P)数量的比值和(ii)VLDL尺寸的至少一种。
其它实施方案涉及患者报告,其包括显示未来糖尿病转变率风险百分比(例如0-100)的糖尿病风险指数(DRI),其是基于研究人群(在1-25年的时间段或其它时间段,例如1、2、3、4、5、6、 7、8、9、10或10-15年的风险窗中进行评价)、基于葡萄糖水平和相对于定义的人群的患者DRI风险得分的相关四分位数或五分位数。患者报告可以包括患者风险和具有较低或较高四分位数或五分位数DRI得分和相同葡萄糖的人群的比较风险。
可以使用多个NMR衍生的测量结果计算DRI风险得分,所述NMR衍生的测量结果包括:脂蛋白测量结果、以μmol/L和/或任意单位的GlycA的测量结果、和任选地以μmol/L为单位的缬氨酸的测量结果。
本发明的实施方案包括评价主体的发展为2型糖尿病和/或具有前驱糖尿病的风险的方法。该方法包括使用至少一种定义的发展为2型糖尿病的风险数学模型以编程方式计算主体的糖尿病风险指数得分,所述模型包括得自主体的至少一种体外生物样品的至少一种脂蛋白分量、至少一种支链氨基酸和至少一种炎性生物标志物。
在一些实施方案中,至少一种定义的风险数学模型可以包括对主体的至少一种生物样品的多个选定脂蛋白分量的NMR衍生的测量结果,和对GlycA和缬氨酸的至少一种的NMR测量结果。定义的数学风险模型可以仅包括对主体的体外血浆或血清生物样品的NMR衍生的测量结果。
在一些实施方案中,该方法可以包括以编程方式定义至少两个不同的发展为2型糖尿病的风险数学模型,所述至少两个不同的数学模型包括一个用于正在进行他汀治疗的主体的模型,其包括对他汀不敏感的脂蛋白分量,和一个用于未进行他汀治疗的主体的模型,其包括至少一种不同的脂蛋白分量。
在一些实施方案中,该方法可以包括以编程方式定义至少两个不同的发展为2型糖尿病的风险数学模型。所述至少两个不同的发展为2型糖尿病的风险数学模型可以具有不同的脂蛋白分量,包括一种用于空腹生物样品的分量和一种用于非空腹生物样品的分量。
在一些实施方案中,该方法可以包括以编程方式产生报告,所述报告具有在未来(例如1-7年的时间)进展为2型糖尿病的风险作为不同糖尿病水平范围的函数的图,显示那些处于糖尿病风险指数得分的不同四分位数、五分位数或十分位数的人的风险。在一些实施方案中,该图显示基于定义人群的至少第一(低)和高(例如第四四分位数、第五五分位数或第十十分位数)DRI得分的参考,由此使得易于识别或了解风险分类。
在一些实施方案中,该方法可以包括以编程方式评价使用至少一个体外生物样品进行的主体的空腹血糖测量结果。糖尿病风险指数得分可以是在定义的得分范围内的数值得分,其得分与人群基准(population norm)的第四四分位数(4Q)或第五五分位数(5Q)相关联,反映出在5-7年内发展为2型糖尿病的增加的风险或高风险。该方法可以包括当空腹血糖水平在90-110 mg/dL之间并且糖尿病风险得分在4Q或5Q范围内时,在发生2型糖尿病之前,以编程方式鉴别具有增加的发展为2型糖尿病的风险的各个主体。
在一些实施方案中,该方法可以包括评价主体的空腹血糖测量结果,其中糖尿病风险指数得分是在定义的得分范围内的数值得分,其得分与人群基准(population norm)的第四四分位数(4Q)或第五五分位数(5Q)相关联,反映出在5-7年内发展为2型糖尿病的增加的风险或高风险。
该方法可以包括当空腹血糖(FPG)水平在90-125 mg/dL之间时,在发生2型糖尿病之前,以编程方式鉴别具有增加的发展为2型糖尿病的风险的各个主体。可以进行以编程方式的鉴别以对具有相同FPG和不同风险得分的患者中的风险进行分级。
在一些实施方案中,该方法可以包括,在编程计算之前,将主体的血浆或血清样品置于NMR谱仪中;获得样品的至少一个NMR谱;对获得的至少一个NMR谱进行去卷积;并基于去卷积的至少一个NMR谱计算GlycA和多个选定的脂蛋白参数的NMR衍生的测量结果。可以进行计算步骤以同样计算支链氨基酸缬氨酸的测量结果。
在一些实施方案中,糖尿病风险指数可以具有定义的数值范围。该方法可以包括以编程方式产生报告,如果空腹血浆或血清葡萄糖值低于100,例如在大约80-99 mg/dl之间(或者甚至更低)并且糖尿病风险指数处于人群基准的第四四分位数、第五五分位数和/或最高十分位数,则该报告将各个主体鉴别为具有发展为前驱糖尿病的风险。
在一些实施方案中,定义的至少一个数学模型可以包括GlycA和多个选定脂蛋白分量的NMR测量结果,其使用从体外血浆或血清生物样品测量的脂蛋白亚类、尺寸和浓度。
在一些实施方案中,至少一个定义的数学模型可以是包括下述至少两种的选定脂蛋白分量:大VLDL亚类颗粒数量、中等VLDL亚类颗粒数量、总HDL亚类颗粒数量、中等HDL亚类颗粒数量和VLDL颗粒尺寸。
选定脂蛋白分量可以包括所有列出的脂蛋白分量。
在一些实施方案中,至少一个定义的数学模型可以包括中等HDL-P对总HDL-P的比值。
至少一个定义的数学模型可以,在一些实施方案中,包括VLDL亚类颗粒尺寸(vsz3)、中等HDL-P对总HDL-P的比值 (HMP_HDLP)乘以GlycA和VLDL尺寸对大VLDL-P和中等VLDL-P的总和的比值。
在编程计算之前,在一些实施方案中,该方法可以包括以电子方式获得主体的生物样品的GlycA拟合区域(fitting region)的复合NMR谱,其中GlycA拟合区域从1.845 ppm延伸至2.080 ppm,并且其中GlycA峰区域的中心位于2.00 ppm;使用定义的去卷积模型和与至少GlycA峰区域相关联的曲线拟合函数对复合NMR谱以电子方式进行去卷积,所述定义的去卷积模型具有高密度脂蛋白(HDL)分量、低密度脂蛋白(LDL)分量、VLDL(极低密度脂蛋白)/乳糜微粒分量;并且使用曲线拟合函数以编程方式产生GlycA的测量结果。该方法可以进一步包括对GlycA的测量结果应用换算系数以提供以μmol/L为单位的测量结果。
在一些实施方案中,曲线拟合函数可以是重叠曲线拟合函数(overlapping curve fit functions)。可以通过将定义数量的曲线拟合函数加和来产生GlycA的测量结果。 去卷积模型可以进一步包含密度大于1.21 g/L的蛋白质的蛋白质信号分量。
在编程计算之前,在一些实施方案中,该方法可以包括以电子方式获得主体的生物样品的缬氨酸拟合区域的NMR谱;以电子方式鉴别缬氨酸信号为位于生物样品中定义稀释物的峰的定义数量的数据点的上游或下游;使用定义的去卷积模型对复合NMR谱以电子方式进行去卷积;并使用去卷积的NMR谱对缬氨酸以电子方式进行定量。
在一些实施方案中,至少一种定义的数学模型可以包括多个不同的定义模型,包括一个包括对他汀治疗不敏感的脂蛋白分量的模型,一个包括对他汀治疗敏感的脂蛋白分量的模型,一个用于空腹生物样品的模型和一个用于非空腹生物样品的模型。
本发明的特定的实施方案涉及电路,所述电路被配置(configured)为用于确定患者是否具有在接下来的5-7年内发展为2型糖尿病的风险和/或患者是否具有前驱糖尿病。该电路包括至少一个处理器,所述处理器被配置以基于至少一个在5-7年内趋同为2型糖尿病的风险数学模型以电子方式计算糖尿病风险指数,所述数学模型考虑来自主体的至少一个体外生物样品的至少一种脂蛋白分量,至少一种支链氨基酸和GlycA。
至少一个风险数学模型,在一些实施方案中,可以包括对GlycA、缬氨酸和多种脂蛋白分量的NMR衍生的测量结果。
在一些实施方案中,可以配置至少一个处理器以定义至少两个不同的发展为2型糖尿病风险数学模型。所述至少两个不同的数学模型可以包括用于正在进行他汀治疗的主体的第一模型,其包括对他汀不敏感的脂蛋白分量,和用于未进行他汀治疗的主体的第二模型。第二模型可以包括至少一些与第一模型不同的脂蛋白分量。可以配置电路以鉴别主体特征,以选择合适的第一或第二风险模型,用于计算糖尿病风险指数得分。
在特定的实施方案中,可以配置至少一个处理器以定义至少两个不同的发展为2型糖尿病风险数学模型,其具有不同的脂蛋白分量,所述至少两个不同的数学模型包括一个用于空腹生物样品的模型,和一个用于非空腹生物样品的模型。该电路可以鉴别主体特征,以选择合适的用于计算糖尿病风险指数得分的数学模型。
在一些实施方案中,可以配置至少一个处理器以产生报告,所述报告具有在未来1-7年的时间发展为2型糖尿病风险相对于空腹葡萄糖水平范围和与糖尿病风险指数得分相关联的风险四分位数的图。该图可以包括基于定义人群的至少第一(低)和第四(高)四分位数DRI得分的可视化参考,从而允许易于识别或了解风险分级。
可以配置至少一个处理器,在一些实施方案中,以评价主体的空腹血糖测量结果,其中糖尿病风险指数得分是在定义得分范围内的数值得分,其得分与人群基准(population norm)的第四四分位数(4Q)、第五五分位数(5Q)或第十十分位数相关联,反映出增加的或高的发展为2型糖尿病风险。可以配置至少一个处理器以在空腹血糖水平在90-110 mg/dL之间并且糖尿病风险得分处于4Q、5Q或第十十分位数范围内时,在发生2型糖尿病之前,鉴别具有增加的发展为2型糖尿病风险的各个主体 。
在一些实施方案中,可以配置至少一个处理器以评价主体的空腹血糖测量结果。糖尿病风险指数得分可以是在定义得分范围内的数值得分,其得分与人群基准的第四四分位数(4Q)、第五五分位数(5Q)或第十十分位数相关,反映出增加的或高的发展为2型糖尿病风险。可以配置至少一个处理器以在空腹血糖(FPG)水平在90-125 mg/dL之间时,在发生2型糖尿病之前,鉴别具有增加的发展为2型糖尿病的风险的各个主体。可以配置至少一个处理器以产生报告,所述报告可对具有相同血糖水平和不同糖尿病风险得分的患者中的风险进行分级。
在一些实施方案中,至少一个数学模型可以包括多种脂蛋白分量,其包下述的至少两种:大VLDL亚类颗粒数量、中等VLDL亚类颗粒数量、总HDL亚类颗粒数量、中等HDL亚类颗粒数量和VLDL颗粒尺寸。数学模型可以包括所有列出的脂蛋白分量。
在一些实施方案中,数学模型的脂蛋白分量之一是中等HDL-P对总HDL-P的比值。
在特定的实施方案中,至少一个数学模型可以包括多种脂蛋白分量,包括VLDL亚类颗粒尺寸(vsz3)、中等HDL-P对总HDL-P的比值 (HMP_HDLP)乘以GlycA和VLDL尺寸对大VLDL-P和中等VLDL-P的总和的比值。
本发明的某些实施方案涉及用于评价体外患者生物样品的计算机程序产品。计算机程序产品包括永久性计算机可读存储介质,其具有存储在介质中的计算机可读程序代码。计算机可读程序代码包括提供至少一个在定义时间段中发展为2型糖尿病风险数学模型的计算机可读程序代码。至少一个发展为2型糖尿病风险数学模型可以包括多种分量,包括至少一种脂蛋白分量,至少一种炎性标志物和至少一种支链氨基酸;以及基于至少一个发展为2型糖尿病风险数学模型计算与患者的生物样品相关联的糖尿病风险指数的计算机可读程序代码。
在一个实施方案中,提供至少一个数学模型的计算机可读程序代码可以包括GlycA和缬氨酸的NMR衍生的测量结果的模型分量。
在一些实施方案中,计算机程序产品可以包括被配置以评价患者的葡萄糖测量结果的计算机可读程序代码。计算糖尿病风险指数的计算机可读程序代码可以将该指数计算为在定义得分范围内的数值得分,其得分与人群基准(population norm)的第四四分位数(4Q)、第五五分位数(5Q)或第十十分位数相关联,反映出增加的或高的发展为2型糖尿病风险。
计算机程序产品可以进一步包括计算机可读程序代码,所述计算机可读程序代码被配置以在空腹血糖水平在90-110 mg/dL之间并且糖尿病风险得分在4Q、5Q或第十十分位数范围内时,在发生2型糖尿病之前,鉴别具有增加的发展为2型糖尿病风险的各个患者。
在一些实施方案中,可以配置计算机程序产品以产生报告,该报告鉴别在空腹血糖(FPG)水平在90-125 mg/dL之间时,在发生2型糖尿病之前具有增加的发展为2型糖尿病的风险的各个主体。数学模型可以对具有相同葡萄糖水平和不同风险得分的患者中的风险进行分级。
在一些实施方案中,至少一个数学模型可以包括多种脂蛋白分量,其包含下述的至少两种:大VLDL亚类颗粒数量、中等VLDL亚类颗粒数量、总HDL亚类颗粒数量、中等HDL亚类颗粒数量和VLDL颗粒尺寸。数学模型可以包括所有列出的脂蛋白分量。
在一些实施方案中,数学模型可以包括中等HDL-P对总HDL-P的比值。在一些实施方案中,至少一个数学模型可以包括多种脂蛋白分量,包括VLDL亚类颗粒尺寸(vsz3)、中等HDL-P对总HDL-P的比值 (HMP_HDLP)乘以GlycA和VLDL尺寸对大VLDL-P和中等VLDL-P的总和的比值。
计算机程序产品可以进一步包括鉴别并对主体的血清或血浆样品的复合NMR谱的缬氨酸拟合区域进行去卷积,并产生计算的缬氨酸测量结果的计算机可读程序代码;和对复合NMR谱的GlycA拟合区域进行去卷积的计算机可读程序代码。计算机可读程序代码可以使用具有(i)高密度脂蛋白(HDL)分量,(ii)低密度脂蛋白(LDL)分量,(iii)VLDL(极低密度脂蛋白)/乳糜微粒分量,(iv)另一种定义的蛋白质信号分量和(v)应用于至少一个GlycA峰区域的曲线拟合函数的定义的GlycA去卷积模型对复合NMR谱进行去卷积,并产生计算的GlycA测量结果。
还有另一个实施方案涉及系统。该系统包括用于获得体外生物样品的至少一个NMR谱的NMR谱仪和至少一个与NMR谱仪连通的处理器。配置至少一个处理器以使用至少一个NMR谱基于至少一个定义的趋同为2型糖尿病风险数学模型确定各个生物样品的糖尿病风险指数得分,所述数学模型考虑自主体的至少一个体外生物样品获得的至少一种脂蛋白分量、至少一种支链氨基酸和至少一种炎性标志物。
可以配置至少一个处理器以对至少一个NMR谱进行去卷积并使用GlycA和缬氨酸的NMR测量结果作为至少一个定义的数学模型的分量,产生:(i)GlycA的NMR测量结果;(ii)缬氨酸的NMR测量结果;(iii)脂蛋白参数的NMR测量结果;和(iv)糖尿病风险指数。
在一些实施方案中,可以配置至少一个处理器以定义至少两个不同的发展为2型糖尿病风险数学模型。所述至少两个不同的数学模型可以包括一个用于正在进行他汀治疗的主体的模型,其包括对他汀不敏感的脂蛋白分量,和一个用于未进行他汀治疗的主体的模型,其包括不同的脂蛋白分量。
在一些实施方案中,可以配置系统中的至少一个处理器以定义具有不同脂蛋白分量的至少两个不同的发展为2型糖尿病风险数学模型,所述至少两个不同的数学模型包括一个用于空腹生物样品的模型和一个用于非空腹生物样品的模型。
可以配置系统中的至少一个处理器,在一些实施方案中,以产生报告,该报告具有在未来(例如在1-7年或甚至更长的时间段中)发展为2型糖尿病风险相对于空腹血糖水平范围和与糖尿病风险指数得分相关联的风险四分位数的图。该图可以包括基于定义人群的DRI得分的至少第一(低)和第四(高)四分位数或者相应五分位数或十分位数的可视化参考,从而能够易于识别或了解风险分级。
在一些实施方案中,定义的至少一个数学模型可以包括GlycA和多个选定的脂蛋白分量的NMR测量结果,其使用由体外血浆或血清生物样品测量的脂蛋白亚类、尺寸和浓度。
在一些实施方案中,至少一个定义的数学模型可以包括包含下述至少两种的选定的脂蛋白分量:大VLDL亚类颗粒数量、中等VLDL亚类颗粒数量、总HDL亚类颗粒数量、中等HDL亚类颗粒数量和VLDL颗粒尺寸。选定的脂蛋白分量可以包括所有列出的脂蛋白分量。
在一些实施方案中,至少一个定义的数学模型可以包括中等HDL-P对总HDL-P的比值。
在一些实施方案中,至少一个定义的数学模型可以包括VLDL亚类颗粒尺寸(vsz3)、中等HDL-P对总HDL-P的比值 (HMP_HDLP)乘以GlycA和VLDL尺寸对大VLDL-P和中等VLDL-P的总和的比值。
本发明的其它实施方案涉及患者报告,其包含:基于定义的发展为2型糖尿病风险数学模型计算的糖尿病风险指数得分,其值高于与增加的风险相关联的人群基准,并包含显示出糖尿病转变风险范围中的百分比相对于葡萄糖水平和患者相对于定义人群的DRI风险得分的相关联四分位数和五分位数的图,以及任选地具有较低或较高四分位数或五分位数DRI得分和相同葡萄糖测量结果的人群的比较风险。
还有其它实施方案涉及NMR系统。该系统包括NMR谱仪;与谱仪连通的流量探测器(flow probe);和至少一个与谱仪连通的处理器。配置至少一个处理器以:(a)获得(i) 与流量探测器中的血浆或血清样品的GlycA相关的NMR谱的定义的GlycA拟合区域的NMR信号;(ii) 与流量探测器中的样品相关的NMR谱的定义的缬氨酸拟合区域的 NMR信号;和(iii)脂蛋白参数的NMR信号;(b)计算GlycA、缬氨酸和脂蛋白参数的测量结果;以及(c)使用定义的发展为2型糖尿病和/或具有前驱糖尿病风险数学模型计算糖尿病风险指数,所述模型使用计算的GlycA、缬氨酸和至少多种脂蛋白参数的测量结果。
NMR系统中的至少一个处理器可以包括至少一个本地或远程处理器NMR分析仪,其中配置至少一个处理器以对样品的至少一个复合NMR谱进行去卷积,以产生GlycA、缬氨酸和脂蛋白参数的测量结果。
本发明的其它方面涉及监测患者以对治疗进行评价或确定患者是否具有发展为2型糖尿病的风险或者具有前驱糖尿病的方法。该方法包括:以编程方式提供至少一个定义的发展为2型糖尿病风险数学模型,其包括多个分量,包括选定脂蛋白亚类和至少缬氨酸或GlycA之一的NMR衍生的测量结果;以编程方式对各个体外患者血浆或血清样品的至少一个NMR谱进行去卷积并确定脂蛋白亚类、GlycA和缬氨酸的测量结果;使用至少一个定义的模型和相应的患者样品测量结果,以编程方式计算各个患者的糖尿病风险指数得分;以及评价至少以下之一:(i)糖尿病风险指数是否高于与增加的发展为2型糖尿病风险相关联的定义的人群基准水平;或 (ii)糖尿病风险指数是否随着时间而升高或降低,从而监测变化,所述变化可能是对治疗的反应。
本领域普通技术人员将会通过阅读附图和下述的优选实施方案的详细描述了解本发明的进一步的特征、优点和细节,这种描述仅仅是对本发明的说明。一个实施方案中所描述的特征可以与其它实施方案组合,虽然没有对此特别进行讨论。也就是说,应当注意,一个实施方案中所描述的本发明的方面可以被包含在不同的实施方案中,虽然没有对此特别进行讨论。也就是说,所有实施方案和/或任何实施方案的特征可以以任何方式和/或组合进行组合。申请人保留改变任何原始提交的权利要求或相应地提交任何新的权利要求的权利,包括根据任何其它权利要求的任何特征修改任何原始提交的权利要求,和/或对其进行修改以并入任何其它权利要求的任何特征,虽然原始权利要求并非以该方式表述。本发明的前述和其它方面将在下述的说明书中详细解释。
如本领域技术人员根据本公开将会了解的,本发明的实施方案可以包括方法、系统、装置和/或计算机程序产品或其组合。
附图简述
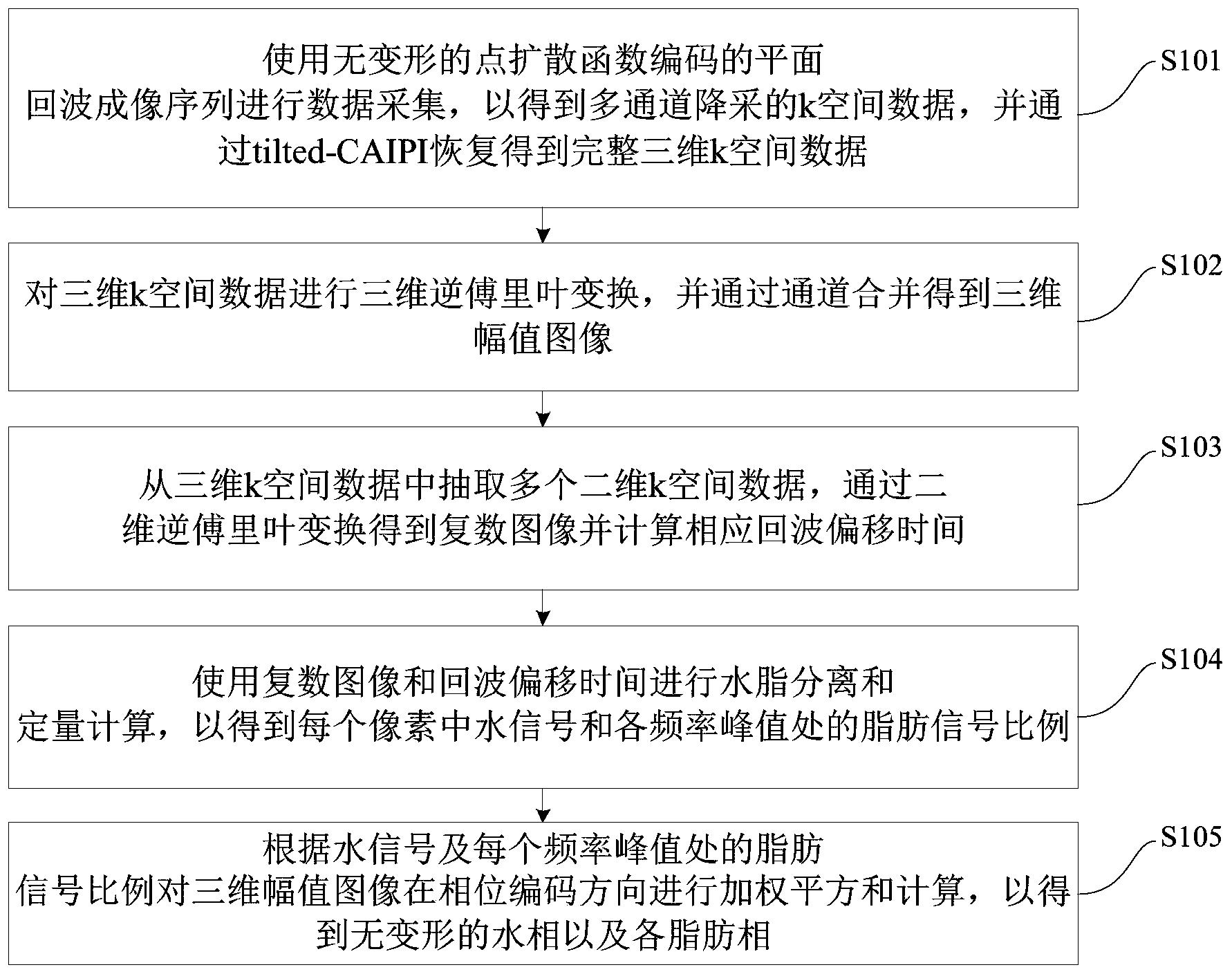
图1A是根据本发明实施方案的,显示基于空腹葡萄糖水平(mg/dl)和糖尿病风险指数的第一和第四四分位数(分别为Q1、Q4)的发展为T2DM的5年转变风险的图。表中的数据代表5年期间转变为2型糖尿病的六个葡萄糖亚组的第一和第四四分位数中的主体的百分比。
图1B是根据本发明实施方案的,显示基于MESA的向糖尿病的糖尿病转变率(%)的图,所述MESA具有处于不同葡萄糖范围的较高和较低DRI得分。
图2A是根据本发明实施方案的,不同脂蛋白亚类群体和示例性尺寸分组的示意图。
图2B是根据本发明实施方案的,不同脂蛋白亚类群体的示意图,其提供了正的和负的风险相关性,例如那些用于评估胰岛素抗性和CHD风险的风险相关性。
图2C是根据本发明实施方案的,HDL亚类H1-H26的表,其中对亚群进行分组以优化中等风险患者(具有高水平和低水平之间的葡萄糖的患者)与T2DM的风险相关性。
图3A显示了被分组为 4个空腹葡萄糖类别的MESA研究参与者的糖尿病转变率(%)。MEA研究人群中的4985名个体中的411名主体在6年的随访期中转变为糖尿病。虚线将研究人群划分为那些具有前驱糖尿病(由空腹血糖水平>100 mg/dL 定义)的,和那些具有正常葡萄糖(≤ 100 mg/dL)的。
图3B显示了被分组为 3个空腹葡萄糖类别的MESA研究参与者的糖尿病转变率(%)。MEA研究人群中的4985名个体中的411名主体在6年的随访期中转变为糖尿病。根据本发明实施方案,虚线将研究人群划分为那些具有低风险葡萄糖(<90 mg/dL)的、中等风险葡萄糖(90-110 mg/dL)的和高风险葡萄糖(>110 mg/dL)的。
图4A是根据本发明实施方案的,显示在4个葡萄糖亚组的每一个中,具有高(第五五分位数)和低(第一五分位数)DRI得分的MESA主体的糖尿病转变率(%)的图,其来自于这样的研究,其中4985名全部的MESA参与者中的411名在6年的随访期中转变为糖尿病。
图4B是根据本发明实施方案的,显示在4个葡萄糖亚组的每一个中,具有高(最高十分位数)和低(最低十分位数)DRI得分的MESA主体的糖尿病转变率(%)的图,数据来自于这样的研究,其中4985名全部的MESA参与者中的411名在6年的随访期中转变为糖尿病。
图5是根据本发明实施方案的,说明26HDL亚群的9个不同尺寸的分组或亚群糖尿病风险相关性的图,其中三个方框是选定HDL亚类的进一步分组。根据本发明的实施方案,逻辑回归模型的χ2值表明在4968名MESA参与者中在6年随访期间在MESA研究人群中确定的风险相关性的优势和标志(strengths and signs),其中有411名被诊断为糖尿病发病病例(在同一个逻辑回归模型中包括了所有9个亚群,根据年龄、性别、种族和葡萄糖进行调整)。
图6是DRI预测模型参数的表,其具有对中等风险葡萄糖亚组(例如FPG在90-110 mg/dL之间)的相关性的统计学测量结果,如本发明的实施方案所预期的。
图7是显示对MESA(4968名参与者中的411名在6年期间转变为糖尿病)中糖尿病发病的增量预测的图,其是由年龄、性别、种族和葡萄糖水平给出的预测之外的预测,通过LR χ2统计进行量化,对于4个不同的逻辑回归模型,其包括,除了年龄、性别、种族和葡萄糖水平以外,下面每一个数据条列出的变量。
图8是根据本发明实施方案的,可用于评估发展为T2DM风险的示例性操作的流程图。
图9是根据本发明实施方案的NMR谱,其显示血浆NMR谱(来自糖基化急性期蛋白的N-乙酰基甲基信号)中的分别与定义的NMR标志物,GlycA和GlycB相关联的炎性标志物。
图10A是根据本发明实施方案的,使用四个缬氨酸(四重)信号计算缬氨酸的NMR测量结果的拟合函数/去卷积模型的实例。
图10B是根据本发明实施方案的,含有来自脂蛋白和支链氨基酸的甲基信号的血浆NMR谱的放大图。
图10C显示根据本发明实施方案的含有来自脂蛋白和支链氨基酸的甲基信号的全NMR谱,其放大图显示来自所注明代谢物的信号的位置。
图11A是根据本发明实施方案的,显示在几个位置为多重谱线的葡萄糖信号的NMR谱。
图11B是根据本发明实施方案的,含有葡萄糖峰的血浆质子NMR谱的区域。
图12A和12B是N-乙酰基糖基化蛋白的碳水化合物部分的化学结构的示意图,显示有CH3基团,其产生GlycA NMR信号。
图13A和13B是N-乙酰基神经氨酸修饰的糖蛋白的碳水化合物部分的化学结构的示意图,显示有CH3基团,其产生GlycB NMR信号。
图14A是根据本发明实施方案的,显示血浆NMR谱放大部分的图,其含有来自血浆脂蛋白的信号包络(signal envelope)和基础的GlycA和GlycB信号。
图14B和14C是根据本发明实施方案的,图14A中显示的NMR谱区域的图,其说明用于产生NMR信号以测量GlycA和GlycB的去卷积模型,。
图14D是根据本发明实施方案的,GlycA/B去卷积模型中不同分量的表。
图14E是根据本发明实施方案的NMR谱,其显示在样品中以典型的正常(低)浓度存在的代谢物A。
图14F是根据本发明实施方案的NMR谱,其显示在样品中以升高的(高)浓度存在的代谢物A。
图15A-15D是GlycA NMR谱区域的图,其说明对于具有高TG(甘油三酯)的样品,来自脂蛋白信号(特别是来自VLDL/Chylos)的谱重叠 。
图16A是GlycA浓度的不同测量结果的表,其取决于去卷积(例如拟合)模型中使用的蛋白质分量。
图16B-16D说明根据本发明实施方案的,使用具有不同蛋白分量(图16A中的表中的#1-#3)的去卷积模型对同一个血浆样品的GlycA和GlycB“拟合”(去卷积) 。
图17是根据本发明实施方案的,用于产生有关GlycA和GlycB信号面积向糖蛋白N-乙酰基甲基基团浓度的换算系数的N-乙酰葡糖胺的10 mmol/L参考样品的去卷积的示意性屏幕截图。
图18A是根据本发明实施方案的,NMR缬氨酸测试方案的流程图。
图18B是根据本发明实施方案的,可在获得生物样品的NMR信号之前使用的示例性预分析处理的流程图。
图18C是根据本发明实施方案的,可用于使用NMR评价缬氨酸的操作的流程图。
图19是根据本发明实施方案的,预期的hs-CRP和NMR-测量结果的GlycA和NMR-测量结果的缬氨酸水平与MESA(n=5680)中各种疾病结果的相关性的图表 。
图20是根据本发明实施方案的,NMR测量结果的GlycA四分位数(以“NMR信号面积单位”表示)的MESA主体的特征的图表。
图21是根据本发明实施方案的,使用DRI风险指数模组和/或电路来分析患者的可预测风险的系统的示意图。
图22是根据本发明实施方案的NMR谱学仪器的示意图。
图23是根据本发明实施方案的数据处理系统的示意图。
图24是根据本发明实施方案的,可用于评估未来发展为T2DM和/或具有前驱糖尿病风险的示例性操作的流程图。
图25A是根据本发明实施方案的患者报告的实例,其包括GlycA测量结果和/或糖尿病风险指数。
图25B是根据本发明实施方案的患者报告的另一个实例,其具有从低到高的连续风险的可视化(典型地是彩色编码的)图形摘要信息。
图26是根据本发明实施方案的,DRI相对于时间的图的预测实例,其可用于监测变化以评价患者的风险状态、状态的变化、和/或治疗的临床效果或者甚至用于临床试验或者用于反对预定的治疗等等。
图27A和27B是图示的糖尿病风险%相对于FPG水平和DRI得分和风险途径的患者/临床报告。图27A显示#1患者的得分,而图27B显示#1患者得分与具有相同FPG的较低风险患者(第2号患者)的比较。根据本发明的实施方案,虽然每一个患者具有相同的FPG,但他们具有由对风险进行分级的DRI得分鉴别的不同的代谢问题。
图28A- 28C是根据本发明实施方案的,图示的糖尿病转变率(%)相对于FPG水平和DRI得分(高DRI、Q4和低DRI、Q1) 的患者/临床报告。图28A是4年转变为糖尿病的风险的报告。图28B是5年转变风险,且图28C是6年转变风险。
图29是根据本发明实施方案的,图示的对于6年(高线)和2年转变期来说,糖尿病转变的Q4/Q1相对风险(1-8)相对于FPG水平和DRI得分的患者/临床报告。
图30是根据本发明实施方案的,图示的对数尺度的5年转变的患者/临床报告 ,其中包括糖尿病转变率(%)相对于FPG水平,和从绿色、黄色、粉色/橙色到红色编码的DRI得分(高DRI、Q4和低DRI、Q1) 颜色,和与风险相关的文字图例,为非常高、高、中等和低。
图31是根据本发明实施方案的,图示的5年转变为糖尿病的患者/临床报告,具有糖尿病转变率(%)相对于FPG水平,和从绿色、黄色、粉色/橙色到红色编码的DRI得分(高DRI、Q4和低DRI、Q1)颜色,和与风险文字相关的图例,为非常高、高、中等和低。
图32是根据本发明实施方案的,显示IRAS数据集、MESA数据集、和IRAS数据集(使用来自MESA的葡萄糖亚组)中DRI效能的数据表。
图33显示根据本发明实施方案的,与图32为相同的数据集标准下的DRI(w/o葡萄糖)效能。
本发明的前述和其它目的和方面在下文的描述中详细说明。
本发明具体实施方案的详细描述
现在参考所附的附图在下文中对本发明进行更充分描述,附图中显示了本发明的实施方案。但是,本发明可以以多种不同的方式实施,而不应当被解释为限制于本文所述的实施方案;而且,提供这些实施方案是为了使本公开充分和完整,并向本领域技术人员充分表达本发明的范围。
在全文中,同类数指同类要素。在图中,为清楚起见,特定线的宽度、层、部件、要素或特征可能被放大。虚线说明是任选的特征或操作,除非另有说明。
本文使用的术语仅是为了描述特定实施方案的目的,不是意图限制本发明。如本文所使用的,单数形式“一(a)”、“一(an)”和“这(the)”也包括复数形式,除非上下文另外明确指出。进一步应当理解术语“包含(comprises)”和/或“包含(comprising)”,当在本说明书中使用时,表示存在所述特征、整数、步骤、操作、要素、和/或部件,但不排除存在或增加一个或多个其它特征、整数、步骤、操作、要素、部件和/或其组合。如本文所使用的,术语“和/或”包括一个或多个相关的所列项目的任意和所有组合。如本文所使用的,短语例如“在X和Y之间”和“在大约X和Y之间”应当理解为包括X和Y。如本文所使用的,短语例如“在大约X和Y之间”的意思是“在大约X和大约Y之间”。如本文所使用的,短语例如“从大约X到Y”的意思是“从大约X到大约Y”。
除非另有定义,本文使用的所有术语(包括技术和科学术语)与本发明所属领域普通技术人员的通常理解具有相同的含义。应当进一步理解术语,例如那些在常用的字典中定义的,应当被理解为具有与它们在说明书和相关领域的背景中的含义一致的含义,而不应当以理想化的或过分正式的意义去理解,除非在本文中明确如此定义。为了简洁和/或清楚,可不对熟知的功能或结构进行详细描述。
应当理解,虽然在本文中可以使用术语第一、第二等来描述不同要素、部件、区域、层和/或部分,这些要素、部件、区域、层和/或部分不应当受到这些术语限制。这些术语仅用于区分一个要素、部件、区域、层或部分与另一个区域、层或部分。因此下面所讨论的第一要素、部件、区域、层或部分可以叫做第二要素、部件、区域、层或部分,而不背离本发明的教导。操作(或步骤)的顺序不限于权利要求中或图中显示的顺序,除非另外特别指出。
术语“以编程方式”的意思是使用计算机程序和/或软件、处理器或ASIC指示的操作来进行。术语“电子”和其衍生词指使用具有电子电路和/或模组的装置,而不是通过精神步骤(mental steps)进行的自动化或半自动化操作,其典型地是指以编程方式进行的操作。术语“自动化(automated)”和“自动的(automatic)”指以可以最少的或无人力的劳动或输入的方式进行操作。术语“半自动化”指允许操作者进行一些输入和激活,但是计算和信号采集以及离子分量浓度的计算以电子方式,典型地以编程方式进行,无需人工输入。
术语“大约”指+/- 特定的值或数字的10% (平均值或均值)。
术语“前驱糖尿病”指患者或主体的风险状态,而不是疾病状态。因此,术语“前驱糖尿病”指还未被诊断为2型糖尿病的人,并且如美国糖尿病协会(American Diabetes Association)目前所定义的,与具有100和125 mg/dL 之间的空腹血浆葡萄糖水平,140-199 (mg/dL)之间的口服葡萄糖耐量测试水平或下述表1中所示的5.7至6.4之间的A1C百分比(对于每一个类型的测试,水平越高,2型糖尿病风险越高)的个体相关联。
表 1:糖尿病和前驱糖尿病的血液测试水平
定义:mg = 毫克,dL = 分升。
对于所有三种测试,在前驱糖尿病范围内,测试结果越高,糖尿病风险越高。
参见,美国糖尿病协会(American Diabetes Association). 糖尿病的医疗护理标准—2012. Diabetes Care. 2012:35 (Supp 1):S12, 表 2。
本发明的实施方案特别适合于对具有相同或相似空腹葡萄糖水平的患者进行风险分级。参见,例如,图1A、1B。 通常来说,预期糖尿病风险指数得分可以单独用于或与FPG或其它葡萄糖测量结果如A1C(使用血红蛋白A1C的非空腹样品)或口服葡萄糖耐量测量结果一起用于对未来发展为2型糖尿病风险进行分级。糖尿病风险得分可以对具有相同葡萄糖水平但不同基础代谢状况的患者的2型糖尿病风险进行分级。
本发明的实施方案可以评价患者患有或在未来发展为2型糖尿病的风险。可以使用一个或多个使用多个风险模型参数的未来转变为2型糖尿病的定义的模型,相对于任何合适的时间线产生该风险,典型地表示在5-25年时间框架内,更典型地在大约5年或6年时间框架内。
本发明的实施方案提供新的生物标志物,其可以对具有中等风险类别的患者的未来发展为2型糖尿病的风险进行分级。
术语“患者”被广泛使用,指提供用于测试或分析的生物样品的个体。
术语“GlycA”指新的生物标志物,其来源于复合NMR信号的测量结果,所述复合NMR信号来自于含有N-乙酰基葡糖胺和/或N-乙酰基半乳糖胺部分的急性期反应物糖蛋白的碳水化合物部分,更特别地来自于2-NAcGlc和2-NAcGal甲基基团的质子。在大约47摄氏度(+/-0.5摄氏度),在血浆NMR谱中,GlycA信号的中心在大约2.00 ppm。峰位置与谱仪的场无关,但可能随生物样品的分析温度而变化,并且在尿生物样品中没有找到峰位置。因此,如果测试样品的温度变化,GlycA峰区域可能变化。GlycA NMR信号可以包括在定义的峰区域的NMR信号子集,以便于仅包括临床相关信号贡献,并可以排除该区域中蛋白质对信号的贡献,如下文所进一步讨论的。
术语“GlycB”指新的生物标志物,其来源于复合NMR信号的测量结果,所述复合NMR信号来自于含有N-乙酰神经氨酸(唾液酸)分子的急性期反应物糖蛋白的碳水化合物部分,更特别地来自于5-Nacetyl甲基基团的质子。在大约47摄氏度,在血浆NMR谱中,GlycB信号的中心在大约2.04
多参数糖尿病风险评价专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。

















动态评分
0.0