







专利摘要
本发明公开了一种基于自学习的多模型控制方法,步骤为:(1)构建模型库,由非线性模型的一组局部模型组成;(2)构建一组控制器,根据模型库中的局部模型设计出来一组局部控制器;(3)执行性能评测:观察输出误差以及系统输出y和模型输出yi之间的差异;基于这些信号,一个性能反馈或者价值函数将被计算出并送到API模块;(4)执行近似策略迭代算法:观察性能反馈信号,接收参考输出和系统输出之间的误差信号,这些信号将作为Markov决策过程的状态,同时状态反馈将成为增强学习的回报信号。本发明具有原理简单、适应范围广、可靠性强、能够保证控制的一般性能以及收敛性等优点。
权利要求
1.一种基于自学习的多模型控制方法,其特征在于,步骤为:
(1)构建模型库,由非线性模型的一组局部模型组成;
(2)构建一组控制器,根据模型库中的局部模型设计出来一组局部控制器;
(3)执行性能评测:观察输出误差以及系统输出y和模型输出yi之间的差异;基于这些信号,一个性能反馈或者价值函数将被计算出并送到API模块;一个基于实际输出与预期输出误差的价值函数被定义为r(t)=R[|e(t)|]=R[|ysp-y(t)|],其中R为非负的函数并且关于|e(t)|单调递减;
(4)执行近似策略迭代算法:观察性能反馈信号,接收参考输出和系统输出之间的误差信号,这些信号将作为Markov决策过程的状态,同时状态反馈将成为增强学习的回报信号。
2.根据权利要求1所述的基于自学习的多模型控制方法,其特征在于,所述步骤(1)中,构建模型库的流程为:
模型组由n个局部模型组成:
或者是其离散时间形式:
∑d=x(t)=fi(x(t-1),...,x(t-n),u(t-1),...,u(t-m-1));
线性模型为:
离散时间的局部线性模型为:
Ai(z-1)x(t)=z-1Bi(z-1)u(t)+d
其中:
Ai(z-1)=1+ai1z-1+…+ainz-n,Bi(z-1)=bi0+bi1z-1+…+bimz-m
3.根据权利要求1所述的基于自学习的多模型控制方法,其特征在于,所述步骤(3)的具体流程为:
(3.1)将系统输出与参考信号之间的误差记为:e(t)=yst-y(t);
将系统输出设定为系统的状态向量,而跟踪误差就变为:e(t)=xst-x(t);
在MDP建模中,e(t)或者是向量组合 被定义为MDP的状态;在多时间点上的向量组合 则是将系统的阶数考虑进来,从而使状态转换 到 满足Markov特性;
(3.2)假设局部控制器的编号为1,2,…,n,记基于API的增强式学习模块在t时刻的输出为a(t),则a(t)就等于所选控制器的编号,即:
1≤a(t)≤n
在t时刻,当API模块的输出确定后,对象的控制变量就为:
而在下一时刻的误差则由下式确定:
其中F(.)由对象的动态特性和反馈控制器所决定。
4.根据权利要求1所述的基于自学习的多模型控制方法,其特征在于,所述步骤(4)的具体流程为:
先初始化价值函数近似器和第0次迭代的策略,其中用一个特定的策略来构建这一初始策略,接着就是不断重复近似策略迭代过程;
在每一次的API迭代中,对象都在一开始被设定为初始状态,并且在每一个时间步长,都会基于当前策略π[k]的价值函数选出一个局部控制器;通过观察对象在下一时间点上的状态,计算出一个性能回报值,同时一对状态转换值将被表示成[x(t),at,rt,x(t+1)]的形式;在收集到足够多的状态转换数据后,运用LSPI或者KLSPI方法得到Qπ[k]的估计值;对于LSPI或者KLSPI方法的提高,可在Qπ[k]基础上产生贪婪策略π[k+1],即为:
重复这一迭代过程直到策略π[k]和策略π[k+1]之间不存在差异,就会收敛得到一个最优策略。
5.根据权利要求4所述的基于自学习的多模型控制方法,其特征在于,所述KLSPI的终止条件选择最大迭代次数或者两次相继策略之间的距离。
6.根据权利要求4所述的基于自学习的多模型控制方法,其特征在于,在LSPI中,行动-状态价值函数由基函数的线性组合来近似并且用LS-TD(λ)算法来计算权值向量W,通过解方程直接得到,即:
7.根据权利要求4所述的基于自学习的多模型控制方法,其特征在于,在KLSPI中,通过在API的策略评估过程中引入Mercer核,利用KLSTD(λ)的一个新变量来近似行动状态价值函数:
其中k(.,.)是Mercer核方程,s,si分别是状态行动组(x,a)和(xi,ai)的组合特性;αi(i=1,2,…,t)是系数,并且(xi,ai)是在采样数据中被选中的状态行动组,也就是说是由Markov决策过程产生的轨迹。
说明书
技术领域
本发明主要涉及到复杂非线性系统的控制领域,特指一种基于自学习的多模型控制方法,它是利用增强学习和近似动态规划思想来实现多个控制器之间的最优转换,因此属于一种多模型自学习转换控制方法。
背景技术
随着现代工业和技术的发展,工程系统装置的复杂程度正具有着一个平稳上升的趋势。更重要的是,这一趋势在很大程度上强调了对于一种方法需求:那就是可以帮助工程技术人员更好地理解和演绎复杂模型以及完成控制任务的实用方法。
几十年来,尽管已经出现了很多关于解决复杂非线性模型的研究,但是在这些研究中提出的高级模型和先进控制方法并没有被广泛地用于解决实际问题。其困难就在于以下两个方面:一是由于这些方法复杂难懂,需要大量的理论知识;二是由于这些方法仍对控制模型的表述具有很强的要求,但同时可利用的精确系统知识却很少。
正是因为上述两项困难,近年来关于多模型的控制方法研究才受到了越来越多人的关注。现今主要的一些多模型研究方法是拆分系统的工作范围,从而解决复杂的非线性建模以及控制问题。此方法的原理是:对于局部模型之间所出现的相关现象的交互要比全局模型来的简单得多,因此,局部模型更加的简单,并且局部模型的建立方法还具有诸如更好的理解性、更少的计算复杂性以及更多的包含先验知识等优势。
正因为上述这些优势的存在,这一领域已经投入了大量的研究工作,并且也取得了一定的成果。到目前为止,现有的多模型控制方法可被分为许多种,其中主要包括增益调度控制(gain scheduling control)、多模型自适应控制(multiple model adaptive control,MMAC)和多模型预测控制(multiple model predictive control)。从传统意义上来讲,增益调度控制是实际运用中最普遍的对于严重非线性系统的控制方法。但是,这种控制方式所表现出的瞬态特性却不是很好。与增益调度控制关系密切的多模型预测控制或者监督控制,它们与增益调度控制最主要的区别就在于运用了一个基于调度算法的估计器。而多模型自适应控制方法提出的主要动机就是要在不增加系统稳态噪声灵敏度的基础上提高它的瞬态特性。MMAC方法最早是被用于解决线性系统的控制问题,但近些年来,由于非线性模型的预测控制被广泛关注,MMAC方法才被延伸用于对非线性系统进行控制。而当今对于非线性系统多模型预测控制方法的进一步推进,则是出现了多模型的动态矩阵控制方式,它除了具有先进的理论意义之外,还有成功的应用案例。
不同于局部控制器已有的成熟设计方法,对于多模型之间的转换策略问题并没有被很好的研究,而且可用于进行设计的控制工具也非常短缺。现有的例如增益调度控制,其转换策略是基于模糊逻辑或者是内插法。此方法的最大缺陷就是自主优化能力和瞬态性能都不是很能令人满意。而另一种多模型自适应控制方法,它的转换策略是基于由估计误差驱动的微小监控信号。虽然这种方法能在一定程度上提高系统的瞬态性能,但是当有未知干扰存在时,系统反馈缺乏鲁棒性,当然,这也是自适应方法存在的通病。
发明内容
本发明要解决的技术问题在于:针对现有技术存在的技术问题,本发明提供一种原理简单、适应范围广、可靠性强、能够保证控制的一般性能以及收敛性的基于自学习的多模型控制方法。
为解决上述技术问题,本发明采用以下技术方案:
一种基于自学习的多模型控制方法,其步骤为:
(1)构建模型库,由非线性模型的一组局部模型组成;
(2)构建一组控制器,根据模型库中的局部模型设计出来一组局部控制器;
(3)执行性能评测:观察输出误差以及系统输出y和模型输出yi之间的差异;基于这些信号,一个性能反馈或者价值函数将被计算出并送到API模块;一个基于实际输出与预期输出误差的价值函数被定义为r(t)=R[|e(t)|]=R[|ysp-y(t)|],其中R为非负的函数并且关于|e(t)|单调递减;
(4)执行近似策略迭代算法:观察性能反馈信号,接收参考输出和系统输出之间的误差信号,这些信号将作为Markov决策过程的状态,同时状态反馈将成为增强学习的回报信号。
作为本发明的进一步改进:
所述步骤(1)中,构建模型库的流程为:
模型组由n个局部模型组成:
或者是其离散时间形式:
∑d=x(t)=fi(x(t-1),...,x(t-n),u(t-1),...,u(t-m-1));
线性模型为:
离散时间的局部线性模型为:
Ai(z-1)x(t)=z-1Bi(z-1)u(t)+d
其中:
Ai(z-1)=1+ai1z-1+…+ainz-n,Bi(z-1)=bi0+bi1z-1+…+bimz-m
所述步骤(3)的具体流程为:
(3.1)将系统输出与参考信号之间的误差记为:e(t)=yst-y(t);
将系统输出设定为系统的状态向量,而跟踪误差就变为:e(t)=xst-x(t);
在MDP建模中,e(t)或者是向量组合 被定义为MDP的状态;在多时间点上的向量组合 则是将系统的阶数考虑进来,从而使状态转换 到 满足Markov特性;
(3.2)假设局部控制器的编号为1,2,…,n,记基于API的增强式学习模块在t时刻的输出为a(t),则a(t)就等于所选控制器的编号,即:
1≤a(t)≤n
在t时刻,当API模块的输出确定后,对象的控制变量就为:
而在下一时刻的误差则由下式确定:
其中F(.)由对象的动态特性和反馈控制器所决定。
所述步骤(4)的具体流程为:
先初始化价值函数近似器和第0次迭代的策略,其中用一个特定的策略来构建这一初始策略,接着就是不断重复近似策略迭代过程;
在每一次的API迭代中,对象都在一开始被设定为初始状态,并且在每一个时间步长,都会基于当前策略π[k]的价值函数选出一个局部控制器;通过观察对象在下一时间点上的状态,计算出一个性能回报值,同时一对状态转换值将被表示成[x(t),at,rt,x(t+1)]的形式;在收集到足够多的状态转换数据后,运用LSPI或者KLSPI方法得到Qπ[k]的估计值;对于LSPI或者KLSPI方法的提高,可在Qπ[k]基础上产生贪婪策略π[k+1],即为:
重复这一迭代过程直到策略π[k]和策略π[k+1]之间不存在差异,就会收敛得到一个最优策略。
所述KLSPI的终止条件选择最大迭代次数或者两次相继策略之间的距离。
在LSPI中,行动-状态价值函数由基函数的线性组合来近似并且用LS-TD(λ)算法来计算权值向量W,通过解方程直接得到,即:
在KLSPI中,通过在API的策略评估过程中引入Mercer核,利用KLSTD(λ)的一个新变量来近似行动状态价值函数:
其中k(.,.)是Mercer核方程,s,si分别是状态行动组(x,a)和(xi,ai)的组合特性;αi(i=1,2,…,t)是系数,并且(xi,ai)是在采样数据中被选中的状态行动组,也就是说是由Markov决策过程产生的轨迹。
与现有技术相比,本发明的优点在于:本发明原理简单、适应范围广、可靠性强,能够保证控制的一般性能以及收敛性。在多个局部控制器进行转换时,优化了系统的瞬态性能;相较于传统的固定转换策略,本发明能够持续保证较好的性能,特别是当闭环系统中存在未知干扰和噪声的情况下。
附图说明
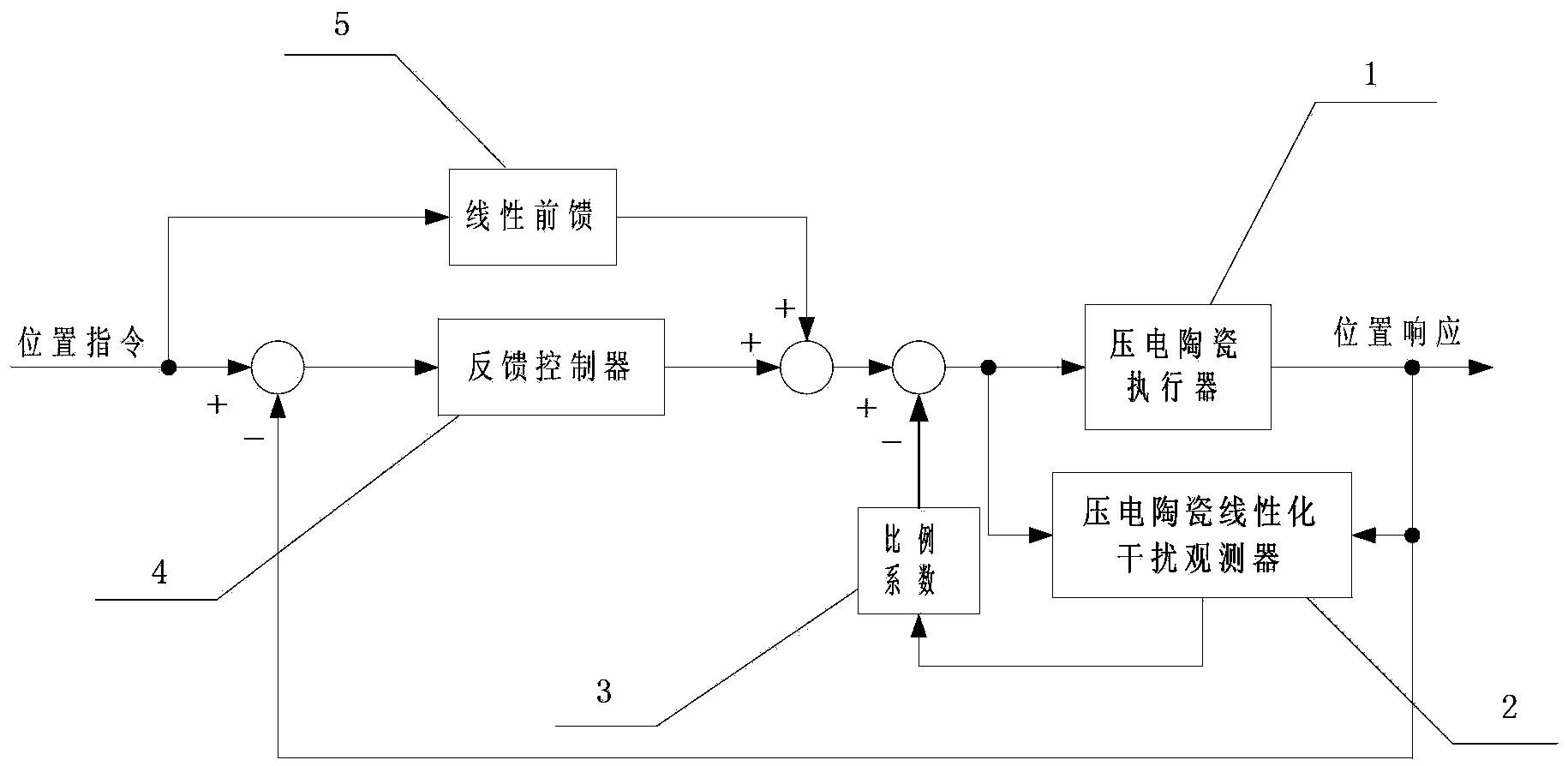
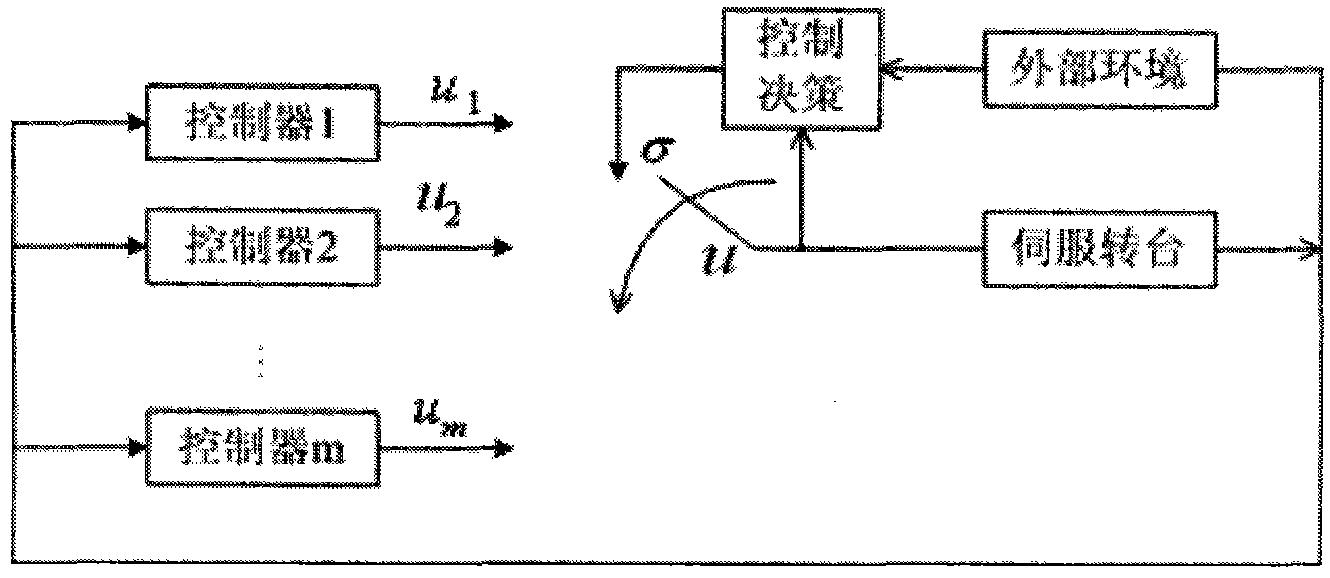
图1是本发明在应用时的原理示意图。
图2是本发明采用近似策略迭代和执行器-评判学习控制结构的原理示意图。
图3是本发明中API算法的流程示意图。
图4是本发明中自学习转换控制器和固定策略转换控制器性能的比较示意图;其中,图4(a)为变量u(t),图4(b)为变量w(t),图4(c)为变量q(t),图4(d)为变量θ(t)。
图5是不同转换策略的转换动作示意图;其中,图5(a)为固定转换策略,图5(b)为LSPI近似最优策略。
图6是本发明在具体应用实例中自学习转换控制器和固定策略转换控制器性能的比较示意图;其中,图6(a)为变量u(t),图6(b)为变量w(t),图6(c)为变量v(t),图6(d)为变量θ(t)。
图7是本发明在不同策略的转换动作示意图;其中,图7(a)为固定转换策略,图7(b)为LSPI近似最优策略。
具体实施方式
以下将结合附图对本发明做进一步详细说明。
如图1所示,本发明基于自学习的多模型控制方法,其步骤为:
(1)构建模型库;由非线性模型的一组局部模型组成;
(2)构建一组控制器,其根据模型库中的局部模型设计出来,这是由于对局部模型控制器的设计要比对全局非线性模型控制器的设计更加的简单与灵活,例如:对于线性化的模型,LQR控制器可以设计为ui=-Kix(i=1,2,...,n);
(3)执行性能评估:观察输出误差以及系统输出y和模型输出yi之间的差异。基于这些信号,一个性能反馈或者价值函数将被计算出并送到API模块。一个基于实际输出与预期输出误差的价值函数被定义为r(t)=R[|e(t)|]=R[|ysp-y(t)|],其中R为非负的函数并且关于|e(t)|单调递减;
(4)执行近似策略迭代算法:不仅要观察性能反馈信号,同时还要接收参考输出和系统输出之间的误差信号,这些信号将作为Markov决策过程的状态,同时状态反馈将成为增强学习的回报信号。基于API的增强学习算法的最终目标就是要最大化性能价值,也就是说要使输出误差得到最小化,其中
在上述步骤(1)中,模型组由n个局部模型组成:
或者是其离散时间形式:
∑d=x(t)=fi(x(t-1),...,x(t-n),u(t-1),...,u(t-m-1))
一个得到局部模型的常用方法,就是在不同的工作区间将全局非线性模型进行线性化。选定一个平衡点及其周围的微小扰动,表达如下:
Δx=x-xie,Δu=u-uie
然后可以得到:
记:
因此可以导出线性模型为:
同样的,可以得到离散时间的局部线性模型为:
Ai(z-1)x(t)=z-1Bi(z-1)u(t)+d
其中:
Ai(z-1)=1+ai1z-1+…+ainz-n,Bi(z-1)=bi0+bi1z-1+…+bimz-m
在上述步骤(3)中,由于增强学习算法是用于Markov决策问题,因此自学习转换控制的关键就在于MDP建模。
首先,将系统输出与参考信号之间的误差记为:
e(t)=yst-y(t)
由于在某些情况下,目标是控制系统的全部状态轨迹。因此,系统的输出就可以被设定为系统的状态向量,而跟踪误差就变为:
e(t)=xst-x(t)
在MDP建模中,e(t)或者是向量组合 被定义为MDP的状态。在多时间点上的向量组合 则是将系统的阶数考虑进来,从而使状态转换 到 满足Markov特性。对于连续对象,由于转换策略和控制信号均只在采样时刻产生,因此,只需考虑在离散时间点上的误差和状态。
假设局部控制器的编号为1,2,…,n。记基于API的增强式学习模块在t时刻的输出为a(t),则a(t)就等于所选控制器的编号,即:
1≤a(t)≤n
在t时刻,当API模块的输出确定后,对象的控制变量就为:
而在下一时刻的误差则由下式确定:
其中F(.)由对象的动态特性和反馈控制器所决定。
在上述步骤(4)中,如图3所示,算法的具体流程为:最开始先要初始化价值函数近似器和第0次迭代的策略,其中将会用一个特定的策略来构建这一初始策略。接着,就是不断重复近似策略迭代过程。
在每一次的API迭代中,对象都在一开始被设定为初始状态,并且在每一个时间步长,都会基于当前策略π[k]的价值函数选出一个局部控制器。通过观察对象在下一时间点上的状态,计算出一个性能回报值,同时一对状态转换值将被表示成[x(t),at,rt,x(t+1)]的形式。在收集到足够多的状态转换数据后,就可运用LSPI或者KLSPI方法得到Qπ[k]的估计值。对于LSPI或者KLSPI方法的提高,可在Qπ[k]基础上产生贪婪策略π[k+1],即为:
因此,贪婪策略Qπ[k+1]是一种决定性的策略,并且当价值函数Qπ[k]能够很好的近似π[k]时,π[k+1]不会比π[k]差。重复这一迭代过程直到策略π[k]和策略π[k+1]之间不存在差异。通常在很少的几步迭代后,就会收敛得到一个最优策略。
KLSPI的终止条件可以选择最大迭代次数或者两次相继策略之间的距离。
基于此,上述近似策略迭代的具体算法为:
近似策略迭代同增强式学习的执行器-评判学习控制结构(actor-critic learning control architecture)有着很密切的关系,它可由图2来描述。在图中,评判部分和执行器部分分别用来演绎策略评估和策略提高过程。在策略评估的过程中,TD学习算法通常被用于在没有任何模型信息的前提下估计价值函数Qπ[t]的值。然而,由于策略迭代的收敛性在很大程度上依赖价值函数的估计精度,因此选用LS-TD(λ)和它的核形式,即KLS-TD(λ);因为它们在收敛性、估计精度和复杂度方面相较于其他算法有很大的优势。在多模型自学习转换控制框架中,LS-TD(λ)方法和KLS-TD(λ)方法均可用于策略评估过程,它们也是LSPI和KLSPI的主要思想。
在LSPI中,行动-状态价值函数由基函数的线性组合来近似并且用LS-TD(λ)算法来计算权值向量W,并且可以通过解方程直接得到,即:
对于拥有大规模非线性价值函数的Markov决策过程,往往需要对价值函数进行非线性估计。KLSPI算法被提出正是由于该方法具有很好的普遍性和非线性近似能力的优势。在KLSPI中,通过在API的策略评估过程中引入Mercer核,利用KLSTD(λ)的一个新变量来近似行动状态价值函数:
其中k(.,.)是Mercer核方程,s,si分别是状态行动组(x,a)和(xi,ai)的组合特性。αi(i=1,2,…,t)是系数,并且(xi,ai)是在采样数据中被选中的状态行动组,也就是说是由Markov决策过程产生的轨迹。
以下将结合对非线性直升机模型进行的多模型控制的具体应用实例,对本发明做进一步详细说明。
直升机模型控制大致上分为3个操作控制,分别为油门控制、总变矩控制θ0,θ0T以及周期变矩操纵θ1s,θ1c。在实验中,只关注直升机纵向运动的动力学,也就是说假设油门控制为常数。直升机纵向运动的状态具有6个自由度,包括直升机沿机身轴的平移速度(u,w,v),直升机的角速度(p,q,r),并且相对于地球定义直升机方向的欧拉角为(θ,φ,ψ)。因此,直升机的动态方程就包含9维状态和4维输入。
直升机的非线性动力学方程为:
其中F(·)是一个非线性的方程,x和u分别为飞行状态和控制输入:
x={u,w,q,θ,v,p,φ,r,ψ},u={θ0,θ1s,θ1c,θ0T} (2)
动力学方程包含以下9个等式:
令xe为直升机的平衡状态。基于微小平衡原理,直升机的状态可以近似为:
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。

















动态评分
0.0