







专利摘要
本发明公开了一种基于关联规则挖掘的锅炉控制方法和装置,该方法包括:采集锅炉状态数据;对数据进行预处理,将数据进行分段线性化逼近,转化为二维空间中的向量,再将其拟合时间序列,对每段时间序列进行聚类,再将时间序列流转变为事务流;建立全局滑动窗口频繁项集树SWFI-tree和局部SWFI-tree,将局部SWFI-tree的信息添加到全局SWFI-tree,修剪全局SWFI_tree;根据FP-growth算法生成频繁项集;利用预先设置的置信度,由频繁项集生成关联规则;利用该关联规则预测指定时间过后锅炉的各参数的变化状态与趋势;根据预测结果提前修改参数,控制锅炉运行。本发明对锅炉状态数据进行统一挖掘,利用挖掘到的关联规则修改锅炉参数,从而达到智能控制锅炉运行的目的。
权利要求
1.一种基于关联规则挖掘的锅炉控制方法,其特征在于,所述方法包括以下步骤:
采集锅炉状态数据;
对数据进行预处理,将数据进行分段线性化逼近,转化为二维空间中的向量,再将其拟合时间序列,对每段时间序列进行聚类,再将时间序列流转变为事务流;
建立全局滑动窗口频繁项集树SWFI-tree和局部SWFI-tree,将局部SWFI-tree的信息添加到全局SWFI-tree,修剪全局SWFI_tree;
根据FP-growth算法生成频繁项集;
利用预先设置的置信度,由频繁项集生成关联规则;
利用所述关联规则预测指定时间过后锅炉的各参数的变化状态与趋势;
根据预测结果提前修改参数,控制锅炉运行。
2.根据权利要求1所述的方法,其特征在于,所述将时间序列流转变为事务流的步骤进一步包括:将多元时间序列流上每个元的拐点进行X轴投影,然后在投影点对所有的时间序列流进行切割,将每个切割段内的数据作为一个事务。
3.根据权利要求1或2所述的方法,其特征在于,所述在将时间序列流转变为事务流步骤之前,将每段时间序列用一个符号代替,在不同流上的近似的时间序列用同一个符号进行代替,并将所在流的序号作为其前缀。
4.根据权利要求1所述的方法,其特征在于,所述SWFI-tree的节点包括若干数据域:item_name,count,segnum,nodelink,parentnode和childnodes,其中
item_name表示节点的名称;
count表示从根节点算起到目前节点的路径上所有的元素的支持度计数;
segnum表示时间序列流的序列号;
nodelink表示指向与此节点有相同item_name值的节点的指针;
parentnode表示指向本节点父节点的指针;
childnodes表示指向子节点的指针集合。
5.根据权利要求1所述的方法,其特征在于,在所述将局部SWFI-tree的信息添加到全局SWFI-tree步骤之后,删除局部SWFI-tree。
6.根据权利要求1所述的方法,其特征在于,所述修剪全局SWFI_tree步骤进一步包括:删除过时模式。
7.根据权利要求6所述的方法,其特征在于,所述修剪全局SWFI_tree步骤进一步包括:更新全局SWFI-tree的项目头表的计数,以及链接指针,同时相应的更新SWFI-tree。
8.根据权利要求1所述的方法,其特征在于,所述修剪全局SWFI_tree步骤进一步包括:删除非频繁模式。
9.根据权利要求8所述的方法,其特征在于,所述修剪全局SWFI_tree步骤进一步包括:更新项目头表的相关信息。
10.一种基于关联规则挖掘的锅炉控制装置,其特征在于,所述装置包括以下步骤:
采集模块,用于采集锅炉状态数据;
预处理模块,用于对数据进行预处理,将数据进行分段线性化逼近,转化为二维空间中的向量,再将其拟合时间序列,对每段时间序列进行聚类,再将时间序列流转变为事务流;
SWFI-tree建立模块,用于建立全局滑动窗口频繁项集树SWFI-tree和局部SWFI-tree,将局部SWFI-tree的信息添加到全局SWFI-tree,修剪全局SWFI_tree;
频繁项集生成模块,用于根据FP-growth算法生成频繁项集;
关联规则生成模块,用于利用预先设置的置信度,由频繁项集生成关联规则;
预测模块,用于利用所述关联规则预测指定时间过后锅炉的各参数的变化状态与趋势;
参数修改模块,用于根据预测结果提前修改参数,控制锅炉运行。
说明书
技术领域
本发明涉及工业控制技术领域,尤其涉及一种基于关联规则挖掘的锅炉控制方法和装置。
背景技术
在燃煤锅炉控制领域中,利用数据流的关联规则调整参数以控制设备,可以有效提高生产效率。现有的关于时间序列数据流关联规则挖掘的技术,一般可分为两个步骤:首先进行频繁模式的挖掘,然后根据频繁模式生成满足要求的关联规则。在时间序列数据流中挖掘频繁模式,大部分是基于Apriori算法的计数,多次遍历数据库,有一些针对Apriori技术进行了改进,最经典的就是FP-growth技术,该技术可以在有限次遍历数据库后得到频繁项集。在获得频繁项集后,生成关联规则的方法大体都相同的,都是根据已知的置信度来筛选关联规则。
在时间序列上已有的技术,大部分都是基于时间窗口的技术,来对数据流上的数据进行本地限制。现有的时间窗口技术分三种,根据不同时序范围可以将数据流环境下的查询窗口划分为不同的三种窗口模式:界标窗口、衰减窗口、滑动窗口。
在数据预处理方面已有的技术是数据的离散化,线性化和聚类。在时间序列频繁模式挖掘方面,已有的技术大部分是基于FP-growth基础上进行相关改进,使其可以适应数据流的相关特性。改进的方面主要有存储结构,有一些技术改进FP-growth技术提出的FP-tree存储结构,以减少为挖掘频繁模式而遍历数据库的次数,有一些技术通过存储结构的修改,来预测潜在的频繁项集,这对数据流上挖掘频繁模式有很大的帮助。
但是,现有技术也存在若干缺点:
1、现有技术大部分专注于单一的时间序列。一般情况下它们在挖掘时间序列关联规则中,只考虑了有一个流的存在。有些技术即便是考虑了多元时间流的存在,但是并没有考虑到不同元之间的相互作用,这样很可能失去许 多有益的关联规则。由现实生活可知,影响属性A当前值的因素不只是属性A以前的值,很可能另外一个属性B对A当前的影响也很大,但是在现有技术中,大部分都没有考虑这样的问题。
2、现有技术在数据预处理的部分进行取元模式时都是根据时间点划分的,一般都是等时间间隔划分的元模式。等时间间隔划分元模式的好处是易于处理,但是这样却忽视了模式的自有特性,因为等时间间隔的划分元模式可能将一个完整的模式认为的分到两个或多个不同的模式中,致使破坏模式的自有特性,再者在实际工作中各个模式的自然长度几乎不能是等长的。
3、现有技术在挖掘频繁项集时,一般都是将当前窗口内的所有数据加入到已存在的数据结构中。这样做的好处是处理简单,同时如果数据结构设计的好的话,也可以在有限时间内完成挖掘。但是随着时间的推移,数据量的增大,可能完成一次数据更新花的时间会越来越多。
发明内容
为了解决现有技术中燃煤锅炉控制领域缺乏对锅炉状态数据进行有效的关联规则挖掘的技术问题,本发明提供了一种基于关联规则挖掘的锅炉控制方法和装置,以实现对锅炉状态数据进行统一挖掘,利用挖掘到的关联规则修改锅炉参数,从而达到智能控制锅炉运行的目的。
本发明公开了一种基于关联规则挖掘的锅炉控制方法,该方法包括以下步骤:
采集锅炉状态数据;
对数据进行预处理,将数据进行分段线性化逼近,转化为二维空间中的向量,再将其拟合时间序列,对每段时间序列进行聚类,再将时间序列流转变为事务流;
建立全局滑动窗口频繁项集树SWFI-tree和局部SWFI-tree,将局部SWFI-tree的信息添加到全局SWFI-tree,修剪全局SWFI_tree;
根据FP-growth算法生成频繁项集;
利用预先设置的置信度,由频繁项集生成关联规则;
利用该关联规则预测指定时间过后锅炉的各参数的变化状态与趋势;
根据预测结果提前修改参数,控制锅炉运行。
本发明还公开了一种基于关联规则挖掘的锅炉控制装置,该装置包括以下步骤:
采集模块,用于采集锅炉状态数据;
预处理模块,用于对数据进行预处理,将数据进行分段线性化逼近,转化为二维空间中的向量,再将其拟合时间序列,对每段时间序列进行聚类,再将时间序列流转变为事务流;
SWFI-tree建立模块,用于建立全局滑动窗口频繁项集树SWFI-tree和局部SWFI-tree,将局部SWFI-tree的信息添加到全局SWFI-tree,修剪全局SWFI_tree;
频繁项集生成模块,用于根据FP-growth算法生成频繁项集;
关联规则生成模块,用于利用预先设置的置信度,由频繁项集生成关联规则;
预测模块,用于利用该关联规则预测指定时间过后锅炉的各参数的变化状态与趋势;
参数修改模块,用于根据预测结果提前修改参数,控制锅炉运行。
与现有技术相比,本发明提出的方法能够同时采集了锅炉状态数据的多元时间序列流,在挖掘时并没有将它们分别开来独立挖掘,而是统一进行挖掘,因此可以有效的发现不同流之间的关联模式,从而发现所有的相互作用关系;其次,本发明在分割模式时,并不是一味的以等间隔时间点进行分割,而是根据各流的间隔拐点进行自然分割,这样能很好的保持各个模式的自然长度;最后,本发明在挖掘时考虑了模式的历史特性,通过衰减策略降低了历史数据对当前挖掘结果的影响。
附图说明
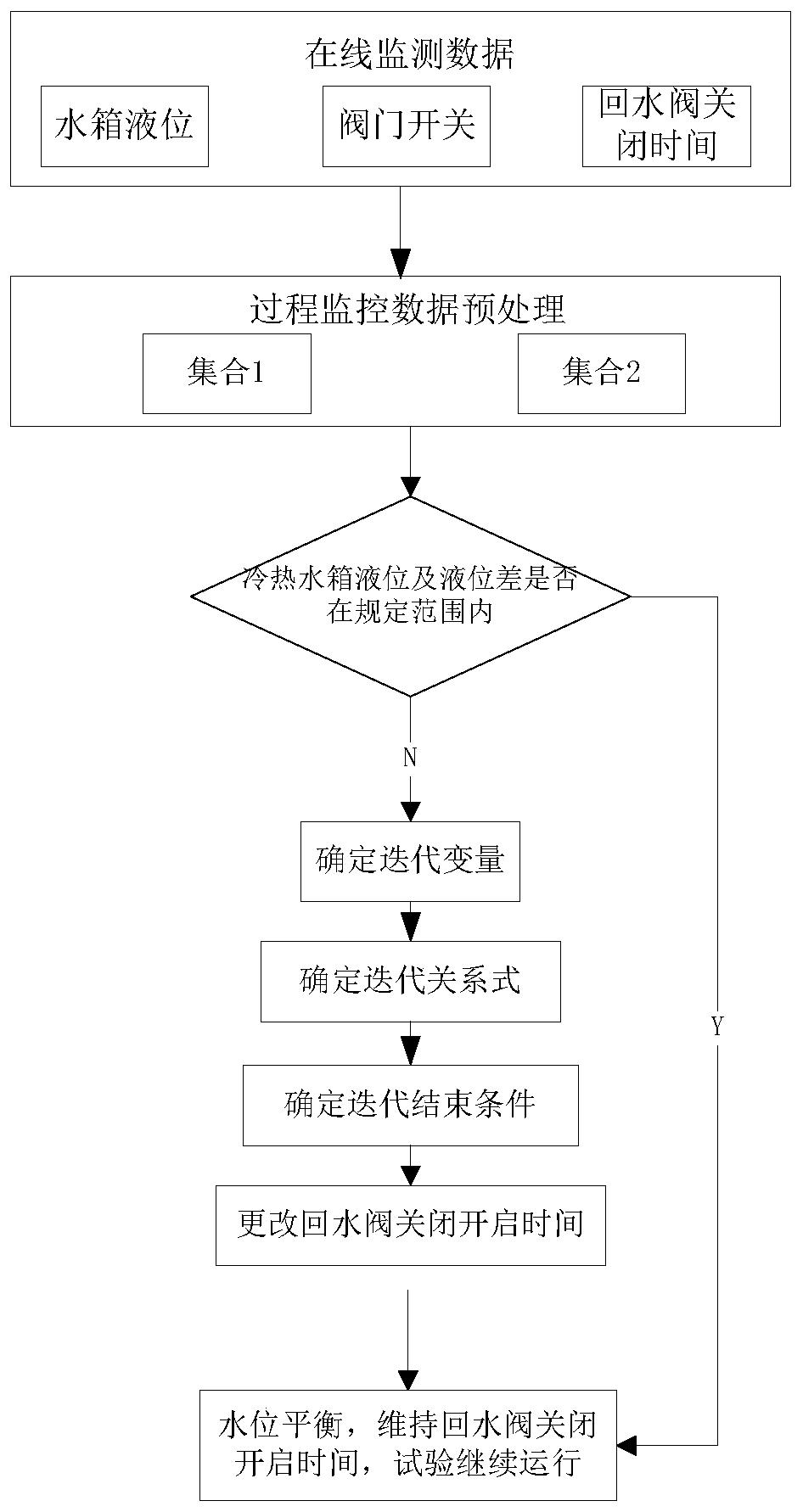
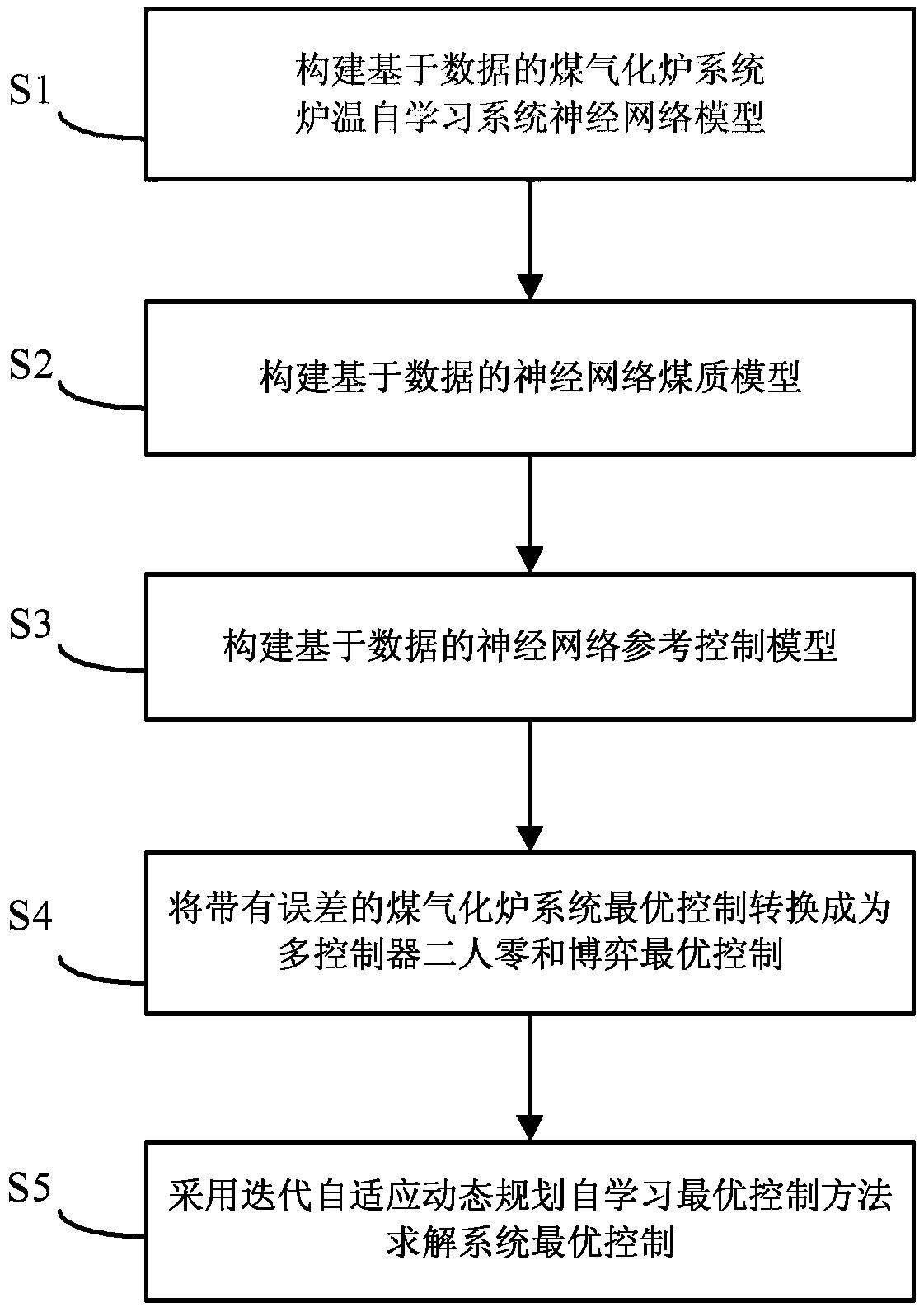
图1为本发明具体实施例锅炉控制方法的流程图。
图2为本发明具体实施例锅炉控制装置的框图。
具体实施方式
本发明提供的实施例应用于热电厂燃煤锅炉控制中,挖掘煤热值关联规 则,可以很好找到与热值相关的相关属性与属性特征。
下面结合图1和图2对本发明的具体实施方式进行详细描述。本发明实施例包括以下步骤:
一、采集数据
将监控锅炉状态的多个传感器与计算机相连,使其生成的数据可以随时输入计算机。为得到比较客观的数据,设置很短的采样周期,即以很短的固定时间间隔来采集数据点。
二、对数据进行相关预处理
采集到的原始数据大都是浮点型数据,但浮点型数据不适合用来挖掘频繁项集。由于在估计燃煤热值的过程中,每个变量的升降趋势比变量本身更有价值,所以为了有效挖掘,需要将原始数据在二维空间中进行分段线性化逼近,转化为二维空间中的向量,再将其拟合时间序列。然后将每段时间序列进行聚类,聚类过程中最重要的就是聚类距离的选择了,本发明考虑到向量同时具有大小与方向两个属性,在计算向量间距离时同时兼顾了向量的大小与方向二属性,因此引进了以下公式:
式中表示最终的二向量的距离; 在进行聚类之后,每个类中的数据点用该类的中心点进行代替。
下一个步骤就是将时间序列流转变为类似传统的事务流。转化为传统的事务流之前还要进行符号化,将每段时间序列用一个符号代替,在不同流上的近似的时间序列用同一个符号进行代替,并且前面要加一个所在流的序号作为其前缀。将时间序列流转变为事务流的步骤包括:将多元时间序列流上每个元的拐点进行X轴投影,然后在投影点对所有的时间序列流进行切割,将每个切割段内的数据看成一个事务,所以整个时间序列流就成为事务流了。
三、挖掘频繁项集
首先,在滑动窗口的基础上建立一个滑动窗口频繁项集树(SWFI-tree)。树的节点有六个数据域:item_name,count,segnum,nodelink,parentnode和childnodes,其中
item_name表示节点的名称;
count表示从根节点算起到目前节点的路径上所有的元素的支持度计数;
segnum表示时间序列流的序列号。根据处理时间序列流的每个序列的先后顺序,将其赋值为0,1……等;
nodelink表示指向与此节点有相同item_name值的节点的指针;
parentnode表示指向本节点父节点的指针;
childnodes表示指向子节点的指针集合。
根据预先定义的全序关系对SWFI-tree和它的项表进行排序。本发明中全序关系就是时间序列数据流的序列号,当在同一个序列中根据原模式的对应在英语字母表中的先后顺序进行排序。数据经过预处理之后,将全序关系应用到事务流集。在FP-tree(Frequency Pattern tree)中,项是以支持度计数的降序的顺序进行排序的,这种方式有助于更多的模式共享公共前缀。然而,由于时间序列数据流的不可预测性的特点,项的支持度计数总是随着时间发生变化的,因此如果用纯粹的FP-tree来存储此数据集的话,那么将会对FP-tree进行频繁的修改,这将花费大量的时间资源。
本发明通过在基本的FP-tree数据结构上进行改变,建立一种新的数据结构SWFI-tree,可以很好的存储时间序列流的模式信息,同时当发生变化时也便于修改。
由于SWFI-tree的结构特点,可知除了根节点以外的节点,其父节点的支持度计数一定不小于本身节点以及本身节点的子节点的支持度计数。
下面具体描述如何构建和维护SWFI-tree。
本发明中构建一个全局SWFI-tree来维持滑动窗口中潜在的频繁模式,所谓潜在的频繁模式就是有可能成为频繁模式,但还不是频繁模式的模式。同时为当前正在分析处理的时间序列流创建一个局部SWFI-tree,当分析处理完成后,就将局部SWFI-tree的信息添加到全局SWFI-tree,然后删除局部SWFI-tree。初始化时全局SWFI-tree与局部SWFI-tree都是空的,然后当第一个数据来到后进行建树,并插入数据。局部SWFI-tree保存有全部的当前窗口信息。将局部的SWFI-tree信息加入全局SWFI-tree时要进行信息的筛选。
算法1的伪代码描述了将局部SWFI-tree信息加入全局SWFI-tree中的过程。
随着时间的推移,全局SWFI-tree的规模逐渐增大,最终可能导致计算设备存储空间的溢出。本发明采用修剪策略来有效降低SWFI-tree的规模。本发明修剪的过程是逐流修剪的,也就是每次循环修剪一个序列流。具体伪代码如下:
步骤1-9是删除过时模式,步骤11-16是删除非频繁模式。
对上述伪代码可以作以下解释。假设滑动窗口SW的大小是N,在SW中基本滑动窗口(基本滑动窗口组成滑动窗口)数是m,目前正在修剪部分的时间序列流的段号是n。总体的修剪策略可以作以下描述:
a,对于在全局SWFI-tree中的节点node1,如果|n-node1.segnum|≥m,那么节点node1和它的后代节点全部被记录为过时模式。直接删除此过时以node1为根节点的子树,同时更新全局SWFI-tree的项目头表的计数,以及链接指针,同时相应的更新SWFI-tree。
b,对于项目头表中每一个nodelink不为空的项,如果|item.count|<ξN,那么在SWFI-tree中所有的与该项有相同的item_name的节点所在的模式均为非频繁模式,可以立即删除这些节点,同时更新项目头表的相关信息。
频繁项集的生成便是按照FP-growth算法里的方法来生成频繁项集。
四、生成关联规则
本发明的生成关联规则与其它一般技术生成关联规则的方法类似,即利用预先设置的置信度来筛选关联规则。
五、预测趋势
利用生成的关联规则预测指定时间过后锅炉的各参数的变化状态与趋势。
六、修改参数
根据预测结果提前修改参数,控制锅炉运行。
本发明应用于热电厂燃煤锅炉控制中,对热值预测技术方面进行了改进与创新。本发明挖掘到的关联规则类似于“A1^B5=>C3(0.6,0.8)”模式长度是L1,可以解释为当元模式A1与B5从时间点t1开始,维持了长度为L1的时间后,那么在时间点t2模式C3可能发生的概率是0.8,即置信度时0.8,支持度0.6的意思是在整体的事务集中此关联规则出现的概率是0.6。将此技术应用到热电厂的锅炉燃烧控制中,可以发现,例如:主气门前压力有模式z1^主蒸汽压力有模式z2,那么在单位时间后磨煤机A进口一次进风压则有模式z3,其中支持度是0.41,置信度时0.84。其中模式z1是以斜率-0.189513下降,模式z2是以斜率1.0178上升,那么在单位时间间隔后就会有模式z3以相应的支持度和置信度发生,模式z3是斜率为-0.189513下降,此关联规则的持续时间长度为1.015个单位时间。在挖掘过程中多次查看挖掘结果可以发现挖掘结果是动态改变着的。在热电厂燃煤锅炉控制中,可以利用在线已挖掘到的关联规则来预测在一段时间之后锅炉的各参数的变化状态与趋势,从而为达到理想的效果可以提前对各参数进行目标性修改,从而达到智能控制锅炉运行。
本领域普通技术人员可以理解实现该实施例方法中全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,该程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如该各方法的实施例的流程。其中,该存储介质可为光盘、磁盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random Access Memory,RAM)等。
应说明的是:以上实施例仅用以说明本发明而非限制,本发明也并不仅限于该举例,一切不脱离本发明的精神和范围的技术方案及其改进,其均应涵盖在本发明的权利要求范围中。
一种时间序列数据流中的关联规则的挖掘方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。

















动态评分
0.0